Download
1 / 1
10 likes | 130 Vues
This paper presents the development of a state-of-the-art Mandarin speech recognizer designed explicitly for broadcast news and conversation contexts. Our approach incorporates improved acoustic segmentation, utilizes multiple complementary acoustic models, and employs discriminative features and model adaptation. We report significant reductions in character error rates (CER) across evaluation phases, demonstrating the effectiveness of our system. Key innovations include a two-stage MLP setup for posteriors generation and advanced feature extraction methods that enhance recognition accuracy.

E N D
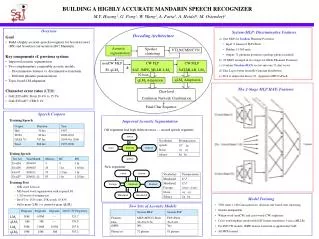
#bigrams #trigrams #4grams Dev07-IV Perplexity LM3 58M 108M --- 325.7 qLM3 6M 3M --- 379.8 LM4 58M 316M 201M 297.8 System-MLP System-PLP qLM4 19M 24M 6M 383.2 Features Dim MLP+MFCC+Pitch 32+39+3=74 PLP+Pitch 39+3=42 fMPE NO Yes Phone set 72 phones 81 phones BUILDING A HIGHLY ACCURATE MANDARIN SPEECH RECOGNIZER M.Y. Hwang1, G. Peng1, W. Wang2, A. Faria3, A. Heidel4, M. Ostendorf1 • Overview • Goal • Build a highly accurate speech recognizer for broadcast news (BN) and broadcast conversation (BC) Mandarin. • Key components cf. previous system: • Improved acoustic segmentation, • Two complementary comparable acoustic models, • Discriminative features vs. discriminative transform, • Different phonetic pronunciations • Topic-based LM adaptation. • Character error rates (CER): • GALE Eval06: From 18.4% to 15.3%. • GALE Eval07: CER 9.1% System-MLP: Discriminative Features Decoding Architecture • One MLP for TandemPhoneme Posteriors • Input: 9 frames of PLP+Pitch • Hidden: 15,000 units • Output: 71 phoneme posteriors (garbage phone excluded) • 20 MLPs arranged in two stages for HATs Phoneme Posteriors • Combine Tandem+HATs vectors into one 71-dim vector • Take Log to better resemble Gaussian distribution • PCA to reduce the dim to 32. Append to MFCC+Pitch. Acoustic segmentation Speaker clustering VTLN/CMN/CVN nonCW MLP SI, qLM3 CW PLP SAT, fMPE, MLLR, LM3 CW MLP SAT,MLLR, LM3 h N-best qLM4 Adaptation qLM4 Adaptation The 2-Stage MLP HATs Features Char-level Confusion Network Combination Final Char Sequence • Speech Corpora • Training Speech • Testing Speech • Training Text • 60K-word Lexicon • ML-based word segmentation with n-gram LM. • 1.2G words of training text • Dev07-iv: 1525 sents, 25K words, 0 OOV • Full n-gram (LMi ) vs. pruned n-gram (qLMi) Improved Acoustic Segmentation Corpus Duration Year Old segmenter had high deletion errors --- missed speech segments. Hub 30 hrs 1997 TDT4 89 hrs 2000-2001 silence GALE Y1 747 hrs 2004-Oct 2006 Vocabulary Pronunciation Total 866 hrs 1997-2006 speech 18+fg noise Start / null End / null Noise rej rej silence bg bg Test Set Year/Month #Shows BC BN speech Eval04 2004/04 3 0 1 hr New segmenter Eval06 2006/02 24 1 hr 1.16 hrs Dev07 2006/11 74 1.5 hrs 1 hr noise silence Vocabulary Pronunciation Eval07 2006/11,12 83 1 hr 1.25 hrs Mandarin1 I1 F Mandarin2 I2 F Foreign Start / null End / null Foreign forgn forgn Noise rej rej Mandarin 1 Mandarin 2 Silence bg bg • Model Training • 3500 states x 128 Gaussians/state, decision-tree based state clustering. • Gender-independent. • Within-word (nonCW) and cross-word (CW) triphones. • Cross-word triphone model with SAT feature transform (1-class cMLLR). • For PLP CW models, fMPE feature transform is applied after SAT. • All MPE trained. • Two Sets of Acoustic Models

















