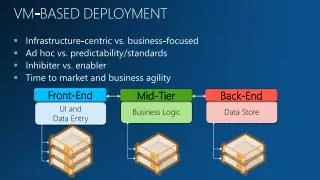
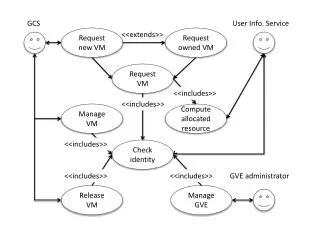
VM CAT
VM CAT. VM CAT. VM US-Eng. VM US-Eng. e001ach2_000_ANV_230000_ENG: hi ~Mary~! how are you. e001ach2_000_ANV_230000_SPA: ¡hola ~Mary~! cómo está. e001ach2_000_ANV_230000_CAT: hola ~Mary~! com està. e001ach1_001_SMA_230000_ENG:

VM CAT
E N D
Presentation Transcript
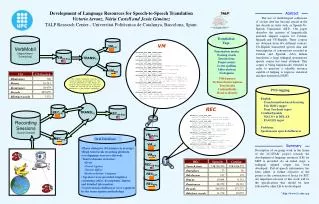
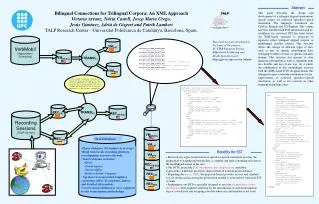
VMCAT VMCAT VMUS-Eng VMUS-Eng e001ach2_000_ANV_230000_ENG: hi ~Mary~! how are you. e001ach2_000_ANV_230000_SPA: ¡hola ~Mary~! cómo está. e001ach2_000_ANV_230000_CAT: hola ~Mary~! com està. e001ach1_001_SMA_230000_ENG: oh I am doing fine Mister ~Vandaloo~. how are you? e001ach1_001_SMA_230000_SPA: oh estoy bien señor ~Vandaloo~. ¿cómo está usted? e001ach1_001_SMA_230000_CAT: oh estic bé senyor ~Vandaloo~. com està vostè? [...] VMSPA VMSPA “The target sentence intends to be as literal as possible to the source sentence in the sense of word-to-word translation and word order as long as it is a proper sentence in the target language.” RECUS-Eng RECUS-Eng Abstract This paper describes the design and development of a trilingual aligned spontaneous speech corpus for statistical speech-to-speech translation. The languages considered are Catalan, Spanish and US-English. This corpus has been enriched with POS information and its usefulness for statistical SST has been tested. An XML-based structure is proposed to represent either bilingual aligned corpora or multilingual parallel corpora. This structure allows the storage of different types of data, such as text or speech, monolingual data, belonging to either a broad- or specific semantic domain. This structure also permits to store linguistic information as well as alignment links in a flexible and easy-to-use way. As a whole, the combination of this multilingual resource with the XML-based DTD designed makes this trilingual corpus a valuable contribution for the improvement of statistical speech-to-speech translation, as well as for research in other language technology areas. RECCAT RECCAT Oral Database RECSPA RECSPA • Phone dialogues (10 minutes in average) • Rigid turn break recording platform (overlappings were not allowed). • Tourist domain scenarios: • Hotel • Travel Agency • Tourist Office • RailwayAirline Company • Speakers were provided templates containing tables, descriptions, figures, and detailed information. • Conversations disfluences were captured by the transcription methodology. Benefits for SST • Research on corpus-based statistical speech-to-speech translation involves the preparation of training and testing data, a complex and time-consuming task due to the multilingual nature of the data. • Our DTD can include POS information and categorisation (time/date expressions), which has proved its improvement of translation performance. • Regarding the use of XML, the proposed format provides an easy and standard way of storing and accessing the information needed to train and test statistical SST systems. • Furthermore, our DTD is specially designed to ease the incorporation of new information when required, allowing for the introduction of several information tags at a word level and accepting raw data when extra information is not used. Bilingual Connections for Trilingual Corpora: An XML Approach Victoria Arranz, Núria Castell, Josep Maria Crego, Jesús Giménez, Adrià de Gispert and Patrik Lambert TALP Research Center - Universitat Politècnica de Catalunya, Barcelona, Spain. VerbMobil [Appointment Scheduling] This work has been developed in the frame of the projects: LC-STAR European Project http://www.lc-star.org andAliado Spanish project http://gps-tsc.upc.es/veu /aliado TRANSL1 <DOC_REPOSITORY DATE="1/1/2004" DESCRIPTION="spontaneous speech dialogue collection" NDOCS="726"> <DOC NDOC="e001a" NSECTIONS="85"> <SCT> <SGM> <LSGM L="CAT">hola Mary !</LSGM> <LSGM L="ENG">hi Mary !</LSGM> <LSGM L="SPA">¡ hola Mary !</LSGM> </SGM> <SGM> <LSGM L="CAT">com està .</LSGM> <LSGM L="ENG">how are you .</LSGM> <LSGM L="SPA">cómo está .</LSGM> </SGM> </SCT> <SCT"> <SGM> <LSGM L="CAT">oh estic bé senyor Vandaloo .</LSGM> <LSGM L="ENG">oh I am doing fine Mister Vandaloo .</LSGM> <LSGM L="SPA">oh estoy bien señor Vandaloo .</LSGM> </SGM> <SGM> <LSGM L="CAT">com està vostè ?</LSGM> <LSGM L="ENG">how are you ?</LSGM> <LSGM L="SPA">¿ cómo está usted ?</LSGM> </SGM> </SCT> [...] <SGM> <LSGM L="CAT"> <W L="oh" P="I">Oh</W> <W L="estar" P="VMI">estic</W> <W L="bé" P="RG">bé</W> <W L="senyor" P="NC">senyor</W> <W L="Vandaloo" P="NP">Vandaloo</W> <W L="." P="Fp">.</W> </LSGM> <LSGM L="ENG"> <W L="oh" P="UH">Oh</W> <W L="I" P="PRP">I</W> <W L="be" P="VBP">am</W> <W L="do" P="VBG">doing</W> <W L="fine" P="JJ">fine</W> <W L="Mister" P="NN">Mister</W> <W L="Vandaloo" P="NNP">Vandaloo</W> <W L="." P=".">.</W> </LSGM> <LSGM L="SPA"> <W L="oh" P="I">Oh</W> <W L="estar" P="VMI">estoy</W> <W L="bien" P="RG">bien</W> <W L="señor" P="NC">señor</W> <W L="Vandaloo" P="NP">Vandaloo</W> <W L="." P="Fp">.</W> </LSGM> </SGM> <SGM> <LSGM L="CAT"> <W L="com" P="PT">Com</W> <W L="estar" P="VMI">està</W> <W L="tu" P="PP">vostè</W> <W L="?" P="Fit">?</W> </LSGM> <LSGM L="ENG"> <W L="How" P="WRB">How</W> <W L="be" P="VBP">are</W> <W L="you" P="PRP">you</W> <W L="?" P=".">?</W> </LSGM> <LSGM L="SPA"> <W L="¿" P="Fia">¿</W> <W L="cómo" P="PT">Cómo</W> <W L="estar" P="VMI">está</W> <W L="tú" P="PP">usted</W> <W L="?" P="Fit">?</W> </LSGM> </SGM> [...] TRANSL2 Recording Sessions [TALP-Tourism]