Download

1 / 18
180 likes | 433 Vues
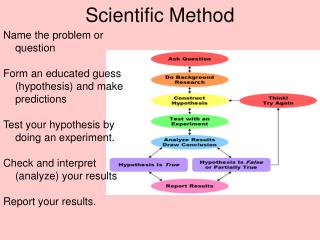
Results: How to interpret and report statistical findings. Today’s agenda: A bit about statistical inference, as it is commonly described in scientific papers Working on Results sections: text, tables and figures. We collect data to test or “falsify” a null hypothesis.

E N D
Results: How to interpret and report statistical findings Today’s agenda: A bit about statistical inference, as it is commonly described in scientific papers Working on Results sections: text, tables and figures
We collect data to test or “falsify” a null hypothesis Null hypothesis: Male and female fish are of similar length Approach: Measure lengths of males and females Data: Length measurements Attributes: Mean, standard deviation, sample size Statistical test: two-sample t-test Output: Probability that the male and female length measurements are drawn from the same population of data (i.e., are similar).
Male mean = 6.5, SD = 0.94, n = 60 Female mean = 7.5, SD = 0.94, n = 60 t = 5.57, df = 118, P < 0.001 Frequency Length (cm)
In this case we can be very confident that the lengths of males and females differ. That is, there is a less than 0.1% chance that their distributions were drawn from the same pool of data. However, this assumes that the fish were collected in a random (non-biased manner), and so the sampling methods are important. Regardless, how would our confidence change is the mean values were the same but the data were more variable?
Male mean = 6.5, SD = 2.73, n = 60 Female mean = 7.5, SD = 2.73, n = 60 t = 2.00, df = 118, P = 0.02 Frequency Length (cm)
In this case we can still be confident that the lengths of males and females differ as the statistical test indicates that there is a less than 2% chance that their distributions were drawn from the same pool of data. Suppose we increase the variation in the data even more but still keep the means the same?
Male mean = 6.5, SD = 4.19, n = 60 Female mean = 7.5, SD = 4.19, n = 60 t = 1.31, df = 118, P = 0.10 Frequency Length (cm)
By convention among scientists, a probability of 5% or less that the distributions are different when in fact they are the same is acceptable. Thus such results are referred to as “statistically significant”. This error is referred to as “alpha” or “Type I” error: the probability of falsely rejecting a null hypothesis that is true, in reality. If the probability is greater than 5% we typically conclude that the difference was not “statistically significant”. This does not mean that the distributions are necessarily the same!
Suppose we take the last data set and double it, without making any other changes? Male mean = 6.5, SD = 4.19, n = 60 Female mean = 7.5, SD = 4.19, n = 60 t = 1.31, df = 118, P = 0.10 Male mean = 6.5, SD = 4.19, n = 120 Female mean = 7.5, SD = 4.19, n = 120 t = 1.86, df = 238, P = 0.03
More on the importance of sample size • If you were gambling, at what point would you suspect that a coin that was being flipped was not “honest”? • 3 heads out of 5 tosses? • 6 heads out of 10 tosses? • 12 heads out of 20 tosses? • 30 heads out of 50 tosses? • 60 heads out of 100 tosses?
Contingency and probability • Are men and women equally likely to be right and left handed? How will sample size influence our confidence in a result? If you want to detect a certain effect, how big should your sample be? P > 0.30 P = 0.07 P = 0.20 P < 0.05
Beta or Type II error: There is another kind of error, referred to as beta or Type II error: the probability of accepting the null hypothesis when in fact it is false. This is not always reported but whenever you see a conclusion that there was “no effect”, you should immediately ask whether the sampling was sufficient to detect an effect. It is easy to make a Type II error if: the sample size was small the effect was subtle the data were highly variable
The probability of making a Type II error is calculated with something called “power analysis” – how powerful was our sampling in terms of the ability to detect an effect? Typically, there is a phrase more or less like this: “Power analysis indicated that these samples provided an 80% chance of detecting a 5% difference in mean length.” This allows the reader to drawn his or her own conclusions as to whether this is an acceptable risk of error.
Hypothesis testing and the burden of proof • H0: “Null Hypothesis” usually means “no effect” or “no difference” • H0 is either true or false. The data might allow you to reject it, with some chance that it is actually true. Alternatively, the data might not allow you to reject it, but in fact it could be false.
Why is this important? The null hypothesis is typically “no effect” and it must be falsified. The alternative would be to assume an effect until it was proved that there was none. In matters of public health, this may means that the burden of proof is on the physicians to show that something is harmful. Consider the process of proving that cigarette smoking contributes to the risk of lung cancer (really, rejecting the null hypothesis that there is no effect). Likewise, in environmental matters, if we use the “falsify the null hypothesis” approach, we assume no harm until harm is shown. This may take a long time, especially if the harm has a long latency period or is complicated by other factors.
In-class activity: Examine published papers to see how statistical terms are used and integrated into the text. How might this have changed over the years? Why?
In-class activity: Students work on Results sections of their papers.
Assignment: Plan your paper’s Discussion. Study the Discussion in the published paper. Read pages 89 – 94 in the book.









![CCSSE 2013 Findings for [College Name]](https://cdn1.slideserve.com/2631776/slide1-dt.jpg)