Download
1 / 15
150 likes | 268 Vues
This resource explores key concepts in parallel computing, focusing on optimization strategies for multithreaded applications. Topics include the definition of fork and join, the importance of synchronization, and the differences between multi-core and hyper-threading architectures. You'll learn how to utilize OpenMP for shared and private variables, manage race conditions, and implement work-sharing in parallel regions. Finally, we discuss common pitfalls and performance considerations in parallelization, providing insights into achieving efficient and effective code execution.

E N D
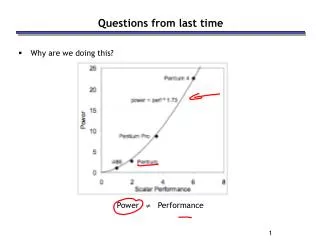
Questions from last time • Why are we doing this? Power Performance
Questions from last time • What are we doing with this? • Leading up to MP 6 • We’ll give you some code • Your task: speed it up by a factor of X • How? • VTune – find the hotspots • SSE – exploit instruction-level parallelism • OpenMP – exploit thread-level parallelism
Questions from last time • Why can’t the compiler do this for us? • In the future, might it? • Theoretically: No (CS 273) • Practically: Always heuristics, not the “best” solution
What is fork, join? • Fork: create a team of independent threads • Join: meeting point (everyone waits until last is done)
What happens on a single core? • It depends (implementation specific) int tid; omp_set_num_threads(4); // request 4 threads, may get fewer #pragma omp parallel private(tid) { /* Obtain and print thread id */ tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); } • Alternative: OS switches between multiple threads • How is multi-core different from hyper-threading? • Logically the same, multi-core is more scalable
What about memory? registers? stack? • Registers: each processor has its own set of registers • same name • thread doesn’t know which processor its on • Memory: can specify whether to share or privatize variables • we’ll see this today • Stack: each thread has its own stack (conceptually) • Synchronization issues? • Can have explicit mutexes, semaphores, etc. • OpenMP tries to make things simple
Thread interaction • Threads communicate by shared variables • Unintended sharing leads to race conditions • program’s outcome changes if threads are scheduled differently #pragma omp parallel { x = x + 1; } • Control race conditions by synchronization • Expensive • Structured block: single entry and single exit • exception: exit() statement
Parallel vs. Work-sharing • Parallel regions • single task • each thread executes the same code • Work-sharing • several independent tasks • each thread executes something different #pragma omp parallel #pragma omp sections { WOW_process_sound(); #pragma omp section WOW_process_graphics(); #pragma omp section WOW_process_AI(); }
Work-sharing “for” • Shorthand: #pragma parallel for [options] • Some options: schedule(static [,chunk]) • Deal-out blocks of iterations of size “chunk” to each thread schedule(dynamic [,chunk]) • Each thread grabs “chunk” iterations off a queue until all iterations have been handled
Sharing data • Running example: Inner product • Inner product of x = (x1, x2, …, xk) and y = (y1, y2, …, yk) is x · y = x1y2 + x2y2 + … + xkyk • Serial code:
Parallelization: Attempt 1 • private creates a “local” copy for each thread • uninitialized • not in same location as original
Parallelization: Attempt 2 • firstprivate is a special case of private • each private copy initialized from master thread • Second problem remains: value after loop is undefined
Parallel inner product • The value of ip is what it would be after the last iteration of the loop • A cleaner solution: reduction(op: list) • local copy of each list variable, initialized depending on “op” (e.g. 0 for “+”) • each thread updates local copy • local copies reduced into a single global copy at the end ip = 0; #pragma parallel for firstprivate(ip) lastprivate(ip) for(i = 0; i < LEN; i++) { ip += x[i] * y[i]; } return ip;
Selection sort for(i = 0; i < LENGTH - 1; i++) { min = i; for(j = i + 1; j < LENGTH; j++) { if(a[j] < a[min]) min = j; } swap(a[min], a[i]); }
Key points • Difference between “parallel” and “work-share” • Synchronization is expensive • common cases can be handled fast! • Sharing data across threads is tricky!! • race conditions • Amdahl’s law • law of diminishing returns