Download

1 / 55
550 likes | 707 Vues
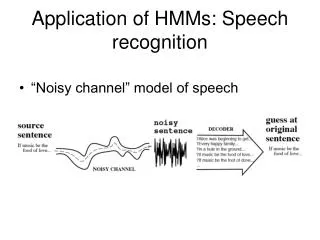
Application of Speech Recognition, Synthesis, Dialog. Speech for communication. The difference between speech and language Speech recognition and speech understanding. Speech recognition can only identify words. System does not know what you want System does not know who you are.

E N D
Application of Speech Recognition, Synthesis, Dialog
Speech for communication • The difference between speech and language • Speech recognition and speech understanding
Speech recognition can only identify words System does not know what you want System does not know who you are
Speech and Audio Processing • Signal processing: • Convert the audio wave into a sequence of feature vectors • Speech recognition: • Decode the sequence of feature vectors into a sequence of words • Semantic interpretation: • Determine the meaning of the recognized words • Dialog Management: • Correct errors and help get the task done • Response Generation • What words to use to maximize user understanding • Speech synthesis: • Generate synthetic speech from a ‘marked-up’ word string
Data Flow Part I Part II Semantic Interpretation Signal Processing Speech Recognition Discourse Interpretation Dialog Management Speech Synthesis Response Generation
Semantic Interpretation: Word Strings • Content is just words • System: What is your address? • User: My address is fourteen eleven main street • Need concept extraction / keyword(s) spotting • Applications • template filling • directory services • information retrieval
Semantic Interpretation: Pattern-Based • Simple (typically regular) patterns specify content • ATIS (Air Traffic Information System) Task: • System: What are your travel plans? • User: [On Monday], I’m going [from Boston] [to San Francisco]. • Content: [DATE=Monday, ORIGIN=Boston, DESTINATION=SFO]
Robustness and Partial Success • Controlled Speech • limited task vocabulary; limited task grammar • Spontaneous Speech • Can have high out-of-vocabulary (OOV) rate • Includes restarts, word fragments, omissions, phrase fragments, disagreements, and other disfluencies • Contains much grammatical variation • Causes high word error-rate in recognizer • Interpretation is often partial, allowing: • omission • parsing fragments
Discourse & Dialog Processing • Discourse interpretation: • Understand what the user really intends by interpreting utterances in context • Dialog management: • Determine system goals in response to user utterances based on user intention • Response generation: • Generate natural language utterances to achieve the selected goals
Discourse Interpretation • Goal: understand what the user really intends • Example: Can you move it? • What does “it” refer to? • Is the utterance intended as a simple yes-no query or a request to perform an action? • Issues addressed: • Reference resolution • Intention recognition • Interpret user utterances in context
Reference Resolution U: Where is A Bug’s Life playing in Monroeville? S: A Bug’s Life is playing at the Carmike theater. U: When is it playing there? S: It’s playing at 2pm, 5pm, and 8pm. U: I’d like 1 adult and 2 children for the first show. How much would that be? • Knowledge sources: • Domain knowledge • Discourse knowledge • World knowledge
Reference Resolution • Focus stacks: • Maintain recent objects in stack • Select objects that satisfy semantic/pragmatic constraints starting from top of stack • Take into account discourse structure • Rule-based filtering & ranking of objects for pronoun resolution
Dialog Management: Motivating Example S: Would you like movie showtime or theater playlist information? U: Movie showtime. S: What movie do you want showtime information about? U: Saving Private Ryan. S: At what theater do you want to see Saving Private Ryan? U: Carmike. S: Saving Private Ryan is not playing at the Carmike theater.
Interacting with the user Dialog manager • Guide interaction through task • Map user inputs and system state into actions Domain agent • Interact with back-end(s) • Interpret information using domain knowledge Domain agent Domain agent
Dialog Management • Goal: determine what to accomplish in response to user utterances, e.g.: • Answer user question • Solicit further information • Confirm/Clarify user utterance • Notify invalid query • Notify invalid query and suggest alternative • Interface between user/language processing components and system knowledge base
Graph-based systems Welcome to Bank ABC! Please say one of the following: Balance, Hours, Loan, ... What type of loan are you interested in? Please sayone of the following: Mortgage, Car, Personal, ... . . . .
Frame-based systems Zxfgdh_dxab: _____ askjs: _____ dhe: _____ aa_hgjs_aa: _____ . . Transition on keyword or phrase Zxfgdh_dxab: _____ askjs: _____ dhe: _____ aa_hgjs_aa: _____ . . Zxfgdh_dxab: _____ askjs: _____ dhe: _____ aa_hgjs_aa: _____ . . Zxfgdh_dxab: _____ askjs: _____ dhe: _____ aa_hgjs_aa: _____ . . Zxfgdh_dxab: _____ askjs: _____ dhe: _____ aa_hgjs_aa: _____ . .
Application Task Complexity • Examples: Weather Information ATIS Call Routing Automatic Banking Travel Planning University Course Advising Simple Complex • Directly affects: • Types and quantity of system knowledge • Complexity of system’s reasoning abilities
Dialog Complexity • Determines what can be talked about: • The task only • Subdialog: e.g., clarification, confirmation • The dialog itself: meta-dialog • Could you hold on for a minute? • What was that click? Did you hear it? • Determines who can talk about them: • System only • User only • Both participants
Dialogue Management: Process • Determines how the system will go about selecting among the possible goals • At the dialogue level, determined by system designer in terms of initiative strategies: • System-initiative: system always has control, user only responds to system questions • User-initiative: user always has control, system passively answers user questions • Mixed-initiative: control switches between system and user using fixed rules • Variable-initiative: control switches between system and user dynamically based on participant roles, dialogue history, etc.
Response Generation U: Is Saving Private Ryan playing at the Chatham cinema?
S provides elliptical response S: No, it’s not.
S provides full response (which provides grounding information) S: No, Saving Private Ryan is not playing at the Chatham cinema.
S provides full response and supporting evidence S: No, Saving Private Ryan is not playing at the Chatham cinema; the theater’s under renovation.
Communicating with the user Language Generator • Decide what to say to user (and how to phrase it) Speech synthesizer • Construct sounds and intonation Display Generator Action Generator
Response Generation • Goal: generate natural language utterances to achieve goal(s) selected by the dialogue manager • Issues: • Content selection: determining what to say • Surface realization: determining how to say it • Generation gap: discrepancy between the actual output of the content selection process and the expected input of the surface realization process
Language generation • Template-based systems • Sentence templates with variables • “Linguistic” systems • Generate surface from meaning representation • Stochastic approaches • Statistical models of domain-expert speech
Dialog Evaluation • Goal: determine how “well” a dialogue system performs • Main difficulties: • No strict right or wrong answers • Difficult to determine what features make a dialogue system better than another • Difficult to select metrics that contribute to the overall “goodness” of the system • Difficult to determine how the metrics compensate for one another • Expensive to collect new data for evaluating incremental improvement of systems
System-initiative, explicit confirmation better task success rate lower WER longer dialogs fewer recovery subdialogs less natural Mixed-initiative, no confirmation lower task success rate higher WER shorter dialogs more recovery subdialogs more natural Dialog Evaluation (Cont’d)
Speech Synthesis (Text-to-Speech TTS) • Prior knowledge • Vocabulary from words to sounds; surface markup • Recorded prompts • Formant synthesis • Model vocal tract as source and filters • Concatenative synthesis • Record and segment expert’s voice • Splice appropriate units into full utterances • Intonation modeling
Recorded Prompts • The simplest (and most common) solution is to record prompts spoken by a (trained) human • Produces human quality voice • Limited by number of prompts that can be recorded • Can be extended by limited cut-and-paste or template filling
The Source-Filter Model of Formant Synthesis • Model of features to be extracted and fitted • Excitation or Voicing Source(s) to model sound source • standard wave of glottal pulses for voiced sounds • randomly varying noise for unvoiced sounds • modification of airflow due to lips, etc. • high frequency (F0 rate), quasi-periodic, choppy • modeled with vector of glottal waveform patterns in voiced regions • Acoustic Filter(s) • shapes the frequency character of vocal tract and radiation character at the lips • relatively slow (samples around 5ms suffice) and stationary • modeled with LPC (linear predictive coding)
Concatenative Synthesis • Record basic inventory of sounds • Retrieve appropriate sequence of units at run time • Concatenate and adjust durations and pitch • Synthesize waveform
Diphone and Polyphone Synthesis • Phone sequences capture co-articulation • Cut speech in positions that minimize context contamination • Need single phones, diphones and sometimes triphones • Reduce number collected by • phonotactic constraints • collapsing in cases of no co-articulation • Data Collection Methods • Collect data from a single (professional) speaker • Select text with maximal coverage (typically with greedy algorithm), or • Record minimal pairs in desired contexts (real words or nonsense)
Signal Processing for Concatenative Synthesis • Diphones recorded in one context must be generated in other contexts • Features are extracted from recorded units • Signal processing manipulates features to smooth boundaries where units are concatenated • Signal processing modifies signal via ‘interpolation’ • intonation • duration
Intonation in Bell Labs TTS • Generate a sequence of F0 targets for synthesis • Example: • We were away a year ago. • phones: w E w R & w A & y E r & g O source: Multilingual Text-to-Speech Synthesis, R. Sproat, ed., Kluwer, 1998
What you can do with Speech Recognition • Transcription • dictation, information retrieval • Command and control • data entry, device control, navigation, call routing • Information access • airline schedules, stock quotes, directory assistance • Problem solving • travel planning, logistics
Human-machine interface is critical Speech recognition is NOT the core function of most applications Speech is afeature of applications that offers specific advantages Errorful recognition is a fact of life
Properties of Recognizers • Speaker Independent vs. Speaker Dependent • Large Vocabulary (2K-200K words) vs. Limited Vocabulary (2-200) • Continuous vs. Discrete • Speech Recognition vs. Speech Verification • Real Time vs. multiples of real time • Spontaneous Speech vs. Read Speech • Noisy Environment vs. Quiet Environment • High Resolution Microphone vs. Telephone vs. Cellphone • Push-and-hold vs. push-to-talk vs. always-listening • Adapt to speaker vs. non-adaptive • Low vs. High Latency • With online incremental results vs. final results • Dialog Management
Speech Recognition vs. Touch Tone • Shorter calls • Choices mean something • Automate more tasks • Reduces annoying operations • Available
Transcription and Dictation • Transcription is transforming a stream of human speech into computer-readable form • Medical reports, court proceedings, notes • Indexing (e.g., broadcasts) • Dictation is the interactive composition of text • Report, correspondence, etc.
SpeechWear • Vehicle inspection task • USMC mechanics, fixed inspection form • Wearable computer (COTS components) • html-based task representation • film clip
Speech recognition and understanding • Sphinx system • speaker-independent • continuous speech • large vocabulary • ATIS system • air travel information retrieval • context management • film clip(1994)
Automate services, lower payroll Shorten time on hold Shorten agent and client call time Reduce fraud Improve customer service Sample Market: Call Centers
Interface guidelines • State transparency • Input control • Error recovery • Error detection • Error correction • Log performance • Application integration
Applications related to Speech Recognition Speech Recognition Figure out what a person is saying. Speaker Verification Authenticate that a person is who she/he claims to be. Limited speech patterns Speaker Identification Assigns an identity to the voice of an unknown person. Arbitrary speech patterns