Central Processing Unit Architecture
Central Processing Unit Architecture. Architecture overview Machine organization von Neumann Speeding up CPU operations multiple registers pipelining superscalar and VLIW CISC vs . RISC. Computer Architecture. Major components of a computer Central Processing Unit ( CPU ) memory


Central Processing Unit Architecture
E N D
Presentation Transcript
Central Processing Unit Architecture • Architecture overview • Machine organization • von Neumann • Speeding up CPU operations • multiple registers • pipelining • superscalar and VLIW • CISC vs. RISC
Computer Architecture • Major components of a computer • Central Processing Unit (CPU) • memory • peripheral devices • Architecture is concerned with • internal structures of each • interconnections • speed and width • relative speeds of components • Want maximum execution speed • Balance is often critical issue
Computer Architecture (continued) • CPU • performs arithmetic and logical operations • synchronous operation • may consider instruction set architecture • how machine looks to a programmer • detailed hardware design
Computer Architecture (continued) • Memory • stores programs and data • organized as • bit • byte = 8 bits (smallest addressable location) • word = 4 bytes (typically; machine dependent) • instructions consist of operation codes and addresses oprn addr 1 oprn addr 1 addr 2 oprn addr 1 addr 2 addr 3
Computer Architecture (continued) • Numeric data representations • integer (exact representation) • sign-magnitude • 2’s complement • negative values change 0 to 1, add 1 • floating point (approximate representation) • scientific notation: 0.3481 x 106 • inherently imprecise • IEEE Standard 754-1985 s magnitude s exp significand
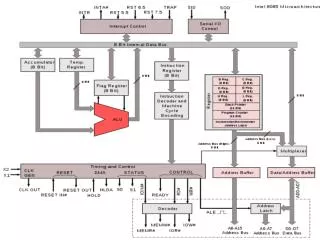
Simple Machine Organization • Institute for Advanced Studies machine (1947) • “von Neumann machine” • ALU performs transfers between memory and I/O devices • note two instructions per memory word Arithmetic - Logic Unit main memory Input- Output Equipment Program Control Unit 0 8 20 28 39 op code address op code address
Simple Machine Organization (continued) • ALU does arithmetic and logical comparisons • AC = accumulator holds results • MQ = memory-quotient holds second portion of long results • MBR = memory buffer register holds data while operation executes
Simple Machine Organization (continued) • Program control determines what computer does based on instruction read from memory • MAR = memory address register holds address of memory cell to be read • PC = program counter; address of next instruction to be read • IR = instruction register holds instruction being executed • IBR holds right half of instruction read from memory
Simple Machine Organization (continued) • Machine operates on fetch-execute cycle • Fetch • PC MAR • read M(MAR) into MBR • copy left and right instructions into IR and IBR • Execute • address part of IR MAR • read M(MAR) into MBR • execute opcode
Architecture Families • Before mid-60’s, every new machine had a different instruction set architecture • programs from previous generation didn’t run on new machine • cost of replacing software became too large • IBM System/360 created family concept • single instruction set architecture • wide range of price and performance with same software • Performance improvements based on different detailed implementations • memory path width (1 byte to 8 bytes) • faster, more complex CPU design • greater I/O throughput and overlap • “Software compatibility” now a major issue • partially offset by high level language (HLL) software
Multiple Register Machines • Initially, machines had only a few registers • 2 to 8 or 16 common • registers more expensive than memory • Most instructions operated between memory locations • results had to start from and end up in memory, so fewer instructions • although more complex • means smaller programs and (supposedly) faster execution • fewer instructions and data to move between memory and ALU • But registers are much faster than memory • 30 times faster
Multiple Register Machines (continued) • Also, many operands are reused within a short time • waste time loading operand again the next time it’s needed • Depending on mix of instructions and operand use, having many registers may lead to less traffic to memory and faster execution • Most modern machines use a multiple register architecture • maximum number about 512, common number 32 integer, 32 floating point
Pipelining • One way to speed up CPU is to increase clock rate • limitations on how fast clock can run to complete instruction • Another way is to execute more than one instruction at one time
Pipelining • Pipelining breaks instruction execution down into several stages • put registers between stages to “buffer” data and control • execute one instruction • as first starts second stage, execute second instruction, etc. • speedup same as number of stages as long as pipe is full
Pipelining (continued) • Consider an example with 6 stages • FI = fetch instruction • DI = decode instruction • CO = calculate location of operand • FO = fetch operand • EI = execute instruction • WO = write operand (store result)
Pipelining Example • Executes 9 instructions in 14 cycles rather than 54 for sequential execution
Pipelining (continued) • Hazards to pipelining • conditional jump • instruction 3 branches to instruction 15 • pipeline must be flushed and restarted • later instruction needs operand being calculated by instruction still in pipeline • pipeline stalls until result ready
Pipelining Problem Example • Is this really a problem?
Real-life Problem • Not all instructions execute in one clock cycle • floating point takes longer than integer • fp divide takes longer than fp multiply which takes longer than fp add • typical values • integer add/subtract 1 • memory reference 1 • fp add 2 (make 2 stages) • fp (or integer) multiply 6 (make 2 stages) • fp (or integer) divide 15 • Break floating point unit into a sub-pipeline • execute up to 6 instructions at once
Pipelining (continued) • This is not simple to implement • note all 6 instructions could finish at the same time!!
More Speedup • Pipelined machines issue one instruction each clock cycle • how to speed up CPU even more? • Issue more than one instruction per clock cycle
Superscalar Architectures • Superscalar machines issue a variable number of instructions each clock cycle, up to some maximum • instructions must satisfy some criteria of independence • simple choice is maximum of one fp and one integer instruction per clock • need separate execution paths for each possible simultaneous instruction issue • compiled code from non-superscalar implementation of same architecture runs unchanged, but slower
Superscalar Example 0 1 2 3 4 5 6 7 8 clock • Each instruction path may be pipelined
Superscalar Problem • Instruction-level parallelism • what if two successive instructions can’t be executed in parallel? • data dependencies, or two instructions of slow type • Design machine to increase multiple execution opportunities
VLIW Architectures • Very Long Instruction Word (VLIW) architectures store several simple instructions in one long instruction fetched from memory • number and type are fixed • e.g., 2 memory reference, 2 floating point, one integer • need one functional unit for each possible instruction • 2 fp units, 1 integer unit, 2 MBRs • all run synchronized • each instruction is stored in a single word • requires wider memory communication paths • many instructions may be empty, meaning wasted code space
Instruction Level Parallelism • Success of superscalar and VLIW machines depends on number of instructions that occur together that can be issued in parallel • no dependencies • no branches • Compilers can help create parallelism • Speculation techniques try to overcome branch problems • assume branch is taken • execute instructions but don’t let them store results until status of branch is known
CISC vs. RISC • CISC = Complex Instruction Set Computer • RISC = Reduced Instruction Set Computer
CISC vs. RISC (continued) • Historically, machines tend to add features over time • instruction opcodes • IBM 70X, 70X0 series went from 24 opcodes to 185 in 10 years • same time performance increased 30 times • addressing modes • special purpose registers • Motivations are to • improve efficiency, since complex instructions can be implemented in hardware and execute faster • make life easier for compiler writers • support more complex higher-level languages
CISC vs. RISC • Examination of actual code indicated many of these features were not used • RISC advocates proposed • simple, limited instruction set • large number of general purpose registers • and mostly register operations • optimized instruction pipeline • Benefits should include • faster execution of instructions commonly used • faster design and implementation
CISC vs. RISC • Comparing some architectures
CISC vs. RISC • Which approach is right? • Typically, RISC takes about 1/5 the design time • but CISC have adopted RISC techniques