Memory-Based Recommender Systems: A Comparative Study
Comparative study of user-user vs. item-item ratings using Slope One algorithm and Pearson's Correlation to evaluate accuracy. Analysis includes MAE results, trend charts, new user problems assessment, and precision analysis. Challenges faced and solutions implemented in the project.


Memory-Based Recommender Systems: A Comparative Study
E N D
Presentation Transcript
CSCI 572 PROJECT RECOMPARATOR Memory-Based Recommender Systems : A Comparative Study Aaron John Mani SrinivasanRamani
Problem definition • This project is a comparative study of two movie recommendation systems based on collaborative filtering. • User-User Rating vs Item-Item Rating • Slope-One algorithm - Prediction engine. • Pearson’s Correlation – Calculate similarity of users/items • The aim of the experiment is to study the accuracy of the two algorithms when applied on the same dataset under similar conditions
Sample graphs showing the data you will collect and how it will be presented. • Mean Absolute Error (MAE) – Sample error difference of approx.100 Users. This is a standard metric which is essentially used to measure how much deviation a particular algorithm will show against original ratings.
Results - MAE • Fifty movie combinations where chosen at random as the sample set for calculating the MAE. • The results are presented in the form of a trend chart in the next slide. • The Mean Absolute Error was calculated as the average of the difference between the actual and predicted ratings for both algorithms. • Slope One user-user algorithm performs slightly better than the Slope One item-item algorithm. • We presume that this is mostly because of the slice of the NetFlix dataset that was used in calculations and the fact that the available user data is far greater than the item data in the data slice. Consequently, user similarity generated predictions will be more focused as compared to item similarity generated predictions
Trend Chart – Actual Ratings of a sample set versus Predicted Ratings
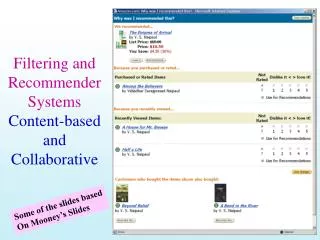
New User Problems Analysis Results • New User Problem – Conduct a survey among 10 human testers to gauge how relevant the top n predictions are compared to the selected movie and rate their accuracy on a scale of 1-10. These users will be new user rows in the User-Item Matrix with a single rating. The mean of this test data will provide a human perspective on the Precision of machine-generated suggestions for new users introduced into the system. • Results - • We found that for users with very few ratings, the predictions are mostly inaccurate in the case of the User-User algorithm. However, as the Item-Item algorithm provides reasonable predictions as expected. • The following slide shows an example of a New User prediction. Note the difference between the User-User recommendations of a New User and the recommendations of a User who has rated a considerable amount of movies as shown in the previous snapshot.
Average Precision Analysis Results • Average Precision Analysis – Create similar test conditions as before. Each human tester logs the relevancy of the top-n predictions of each algorithm to the selected movie. The average across each category of algorithms should provide some insight into the # of relevant predictions generated as compared to the total predictions generated.
Average Precision Analysis • We conclude that the recommendations generated are not very precise as compared to the recommendations for popular websites like NetFlix and IMDB. This is directly related to a user’s perception of precision. • This metric is not entirely reliable as we have taken a slice of the NetFlix dataset as our sample set of data to run tests on. There are bound to be anomalies in this result set due to the lack of similarity among certain items and users. • Average Precision analysis cannot be used to make a judgment on the quality of the recommendations.
PROBLEMS FACED AND SOLUTION • Loading the DataSet – The size of the dataset was too large to load into the database directly. • Solution – The java code was optimized to handle memory overflow problems caused due to the enormous number of files in the dataset. • Selecting a sizable dataset to work on – After loading the entire dataset, we found that the size was just too large to handle and queries were taking too much time to run. • Solution – We reduced the size of the dataset and indexed the main tables. • UI –User input led to various exceptions • Solution – Created a popup which enables the user to select a movie from a list. • Query Optimization – The underlying prediction engine initially returned extremely vague results. • Solution – The logic at the back end was tweaked to improve the recommendation accuracy.
ACCOMPLISHMENTS AND CONCLUSION • GOAL - We have successfully implemented and compared two forms of algorithms belonging to the Slope ONE family. • We managed to optimize our system to a certain extent by moving the computation to the database instead of inside the server/servlet. • RESULT - Our analysis shows that the User-User algorithm performs better than the Item-Item algorithm under the specific dataset. • NEW USER PROBLEM - The Item-Item algorithm provides better recommendations when a new User is taken into account • FUTURE WORK – • Efficiency can be improved by optimizing the back end database. • The presently existing static user selection can be made dynamic. • A Distributed system can be considered in order to account for scalability of data.