Introduction to Integer Arithmetic
Introduction to Integer Arithmetic. Suggested Reading. Computer Arithmetic – Behrooz Parhami – Oxford Press, pages 211-224 (Basic Division Schemes); pages 261- 272 (Division by Convergence) and pages 345-356 (Square-Rooting Methods)


Introduction to Integer Arithmetic
E N D
Presentation Transcript
Suggested Reading • Computer Arithmetic – Behrooz Parhami – Oxford Press, pages 211-224 (Basic Division Schemes); pages 261- 272 (Division by Convergence) and pages 345-356 (Square-Rooting Methods) • Computer Arithmetic – Digital Computer Arithmetic – Joseph F. F. Cavanagh – McGraw-Hill • Computer Arithmetic Simulator by Israel Koren.
Topics • Numeric Encodings • Unsigned & Two’s complement • Programming Implications • C promotion rules • Basic operations • Addition, negation, multiplication • Programming Implications • Consequences of overflow • Using shifts to perform power-of-2 multiply/divide
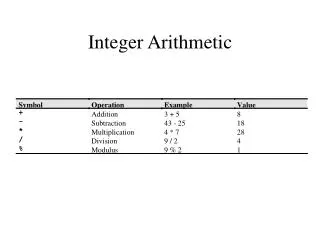
Number Range Xmin Xmax(check!) Number system Decimal X = (xk-1xk-2 … x1x0.x-1 … x-l)10 0 10k - 10-l Binary X = (xk-1xk-2 … x1x0.x-1 … x-l)2 2k - 2-l 0 Conventional fixed-radix X = (xk-1xk-2 … x1x0.x-1 … x-l)r 0 rk - r-l Notation: Unit in the least significant position Unit in the last position ulp = r-l
Representations of signed numbers Biased Signed-magnitude Complement [-8, +7] -> [0,15] F.P. Exponent Diminished-radix complement (Digit complement) Radix-complement r = 2 r = 2 Two’s complement One’s complement Most Used Representation
Two’s complement One’s complement Signed- magnitude Biased 7 0111 1111 0111 0111 6 0110 1110 0110 0110 5 0101 1101 0101 0101 4 0100 1100 0100 0100 3 0011 1011 0011 0011 2 0010 1010 0010 0010 1 0001 1001 0001 0001 0 0000 1000 0000 0000 -0 1000 1111 -1 1001 0111 1111 1110 -2 1010 0110 1110 1101 -3 1011 0101 1101 1100 -4 1100 0100 1100 1011 -5 1101 0011 1011 1010 -6 1110 0010 1010 1001 -7 1111 0001 1001 1000 -8 0000 1000
Encoding Integers • C short 2 bytes long • Sign Bit • For 2’s complement, most significant bit indicates sign • 0 for nonnegative (or positive) • 1 for negative Unsigned Two’s Complement short int x = 15213; short int y = -15213; Sign Bit
Encoding Example (Cont.) x = 15213: 00111011 01101101 y = -15213: 11000100 10010011
Unsigned Values UMin = 0 000…0 UMax = 2w – 1 111…1 Two’s Complement Values TMin = –2w–1 100…0 TMax = 2w–1 – 1 011…1 Other Values Minus 1(-1) 111…1 Numeric Ranges Values for W = 16
Values for Different Word Sizes • Observations • |TMin | = TMax + 1 • Asymmetric range • UMax = 2 * TMax + 1 • C Programming • #include <limits.h> • K&R App. B11 • Declares constants, e.g., • ULONG_MAX • LONG_MAX • LONG_MIN • Values platform-specific
Unsigned & Signed Numeric Values X B2U(X) B2T(X) 0000 0 0 0001 1 1 0010 2 2 0011 3 3 0100 4 4 0101 5 5 0110 6 6 0111 7 7 1000 8 –8 1001 9 –7 1010 10 –6 1011 11 –5 1100 12 –4 1101 13 –3 1110 14 –2 1111 15 –1 • Equivalence • Same encodings for nonnegative values • Uniqueness • Every bit pattern represents unique integer value • Each representable integer has unique bit encoding
Casting Signed to Unsigned • C Allows Conversions from Signed to Unsigned • Resulting Value • No change in bit representation • Nonnegative values unchanged • ux = 15213 • Negative values change into (large) positive values ! ! • uy = 50323 short int x = 15213; unsigned short int ux = (unsigned short) x; short int y = -15213; unsigned short int uy = (unsigned short) y;
Signed vs. Unsigned in C • Constants • By default are considered to be signed integers • Unsigned if have “U” as suffix 0U, 4294967259U • Casting • Explicit casting between signed & unsigned same as U2T and T2U int tx, ty; unsigned ux, uy; tx = (int) ux; uy = (unsigned) ty; • Implicit casting also occurs via assignments and procedure calls tx = ux; uy = ty;
Sign Extension w X • • • • • • X • • • • • • w k • Task: • Given w-bit signed integer x • Convert it to w+k-bit integer with same value • Rule: • Make k copies of sign bit: • X = xw–1 ,…, xw–1 , xw–1 , xw–2 ,…, x0 k copies of MSB
Sign Extension Example Decimal Hex Binary 15213 x 3B 6D 00111011 01101101 15213 ix 00 00 3B 6D 00000000 00000000 00111011 01101101 -15213 y C4 93 11000100 10010011 -15213 iy FF FF C4 93 11111111 11111111 11000100 10010011 • Converting from smaller to larger integer data type • C automatically performs sign extension short int x = 15213; int ix = (int) x; short int y = -15213; int iy = (int) y;
Negating with Complement & Increment x -1 1 1 0 1 0 1 1 1 1 1 1 1 0 1 1 1 + ~x 0 1 1 0 0 0 1 0 • Claim: Following Holds for 2’s Complement ~x + 1 == -x • Complement • Observation: ~x + x == 1111…112 == -1 • Increment • ~x + x + (-x + 1) == -1 + (-x + 1) (Adding (-x +1) on both sides of equation ) • ~x + 1 == -x
Comp. & Incr. Examples x = 15213 0
Unsigned Addition • • • • • • • • • • • • • Standard Addition Function • Ignores carry output u Operands: w bits + v True Sum: w+1 bits u + v Discard Carry: w bits UAddw(u , v)
Class Exercise - 1 • Suppose that you have a number (positive or negative) represented in two´s complement, using 4 bits of word length. • Specify the steps which are necessary to perform fast division by 2 and obtain the correct result for positive and negative numbers. • Remember that arithmetic shift operations are shifts where the sign bit is propagated from right to left. • Think about 4-bit numbers in two’s complement, that is they are in the range [-8 to +7].
Carry and Overflow Detection in Software for Two´s Complement Arithmetic • OVERFLOW Sign Sign Carry-in Overflow A i-1 B i-1 Cyin i-1 Ovf i 0 0 0 0 0 0 1 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 1 0 1 1 1 1 0 Ovf i = Ai-1.Bi-1.Cyini-1 + A i-1 B i-1. Cyin i-1 (hardware method of detection) or the software method of detection: Numbers have equal signs and resulting sign is different from number’s signs It is possible to have a CARRY out and not have an OVERFLOW !!!!!!!!!!!! • Detection in Hardware is slightly Different because the result (Sum) bit is not used – Cyi-1 and Cyi-2 bits are used instead. • CARRY (Addition or Subtraction) Sign Sign Carry In Carry Out A i-1 B i-1 Cyin i-1 Cyouti 0 0 0 0 0 0 1 0 0 1 0 0 0 1 1 1 1 0 0 0 1 0 1 1 1 1 0 1 1 1 1 1 Cyouti=A i-1.B i-1 + (A i-1Θ B i-1). Cyin i-1
Basic Operations in Two´s Complement: Addition and Subtraction Have the Same Treatment • A = -7 ; B= +8 A – B = A + (-B) = ? (4 bits) 1001 (-7) + 1000 (-8) (CY=1) 0001 (-15) (Borrow=0) OVERFLOW • A = +7 ; B = + 8 A - B = A + (-B) = ? 0111 (+7) + 1000 (-8) (CY= 0) 1111 (-1) ( Borrow = 1) NO OVERFLOW • A= +7 ; B = +6 A - B = A + (-B)? 0111 (+7) + 1010 (-6) (CY= 1) 0001 (+1) ( Borrow = 0) NO OVERFLOW NOTES: 1 – Multi operand arithmetic (eg. a 16-bit subtraction on a 8-bit microcontroller) demands the use of arithmetic operations which use the CARRY FLAG. 2 – The Hardware has only one flag, which is usually termed CARRY and instructions are usually termed ADDc, SUBc (or SUBnc). 3- Looking to the left side of this slide we can see that actually in subtraction, it has to be SUBTRACT on BORROW (propagate borrow then there is no CARRY). 4 – OVERFLOW (hardware detection) Overflow occurs when the sign bits are zero and there is a carry from the previous bits or when the sign bits are one and there is no carry from the previous bits: Ov = Xn-1.Yn-1.CY´n-1 + X´n-1.Y´n-1.CYn-1 5 – OVERFLOW (Software detection) If both numbers have the same signs and the result of the addition is of a different sign then an overflow occurred !!!
Multiplication in Two´s Complement • It can be easily performed in software by a sequence of multiply-add operations, but it takes many clock cycles. The number of clock cycles is directly proportional to the number of bits of the operands. • The software algorithm can be improved as it will be seen in the next slide. • If the Microprocessor has a Parallel Combinational Multiplier it can be done in one clock cycle (for single operands) or approximately 6 clock cycles for double-word operands (DSPs and other modern microprocessors have such a multiplier) 1 0 1 0 0 0 1 1 1 0 1 1 0 1 X 1 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 + 0 0 0 0 0 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 1 1 0 0 1 0 0 1 1 1 1 1 0 1
Optimized Multiplication in Software (http://www.convict.lu/Jeunes/Math/Fast_operations.htm) The algorithm is based on a particularity of binary notation. Imagine the multiplying of the base 10 numbers x10 = 7 and y10 = 5 x2 = 111 y2 = 101, which signifies y10 = 1*22 + 0*21 + 1*20 = 1*1002 + 0*102 + 1*12 The distributive rule gives us: 111 * 101 = 111 * (1*100 + 0*10 + 1*1) = 111*(1*100) + 111*(0*10) + 111*(1*1) The associative and commutative rules give us: = (111*100)*1 + (111*10)*0 + (111*1)*1 In binary notation, multiplying by factors of 2 is equivalent to shifting the number: = 11100*1 + 1110*0 + 111*1 = 11100 + 111 = 100011 = 3510 Thus a simple algorithm may be written for multiplication: Operate the muliplication z = x * y z := 0 while y <> 0 do is the least significant bit of y 1 ? yes: z := z + x; no: continue; shift x one digit to the left; shift y one digit to the right; Let's now analyze the function MULV8which may be accessed from within a program by preparing the temporary variables TEMPX and TEMPY, calling the function and finally retrieving the product from the variable RESULT. For example, we want our program to compute: z := x * y In PIC-assembler this will sound: MOVF x,WMOVWF TEMPXMOVF y,WMOVWF TEMPYCALL MULV8MOVF RESULT,WMOVWF z O tempo da Multiplicação (ou número de ciclos) vai depender da configuração dos bits do multipliando e do multiplicador. Por exemplo, a multiplicação por 3 é bastante rápida, pois “y” logo valerá zero e ele sai do loop.
Optimized Multiplication in Software – 8 bits here is what the computer will do: clrf means 'clear file' (in PIC-language a file is an 8-bit register) movf'transfer value from file to itself (F) or the accumulator (W)‘ btfsc means 'skip next instruction if the designed bit is clear') bcf'bit clear at file' Status,C = CLEAR THE CARRY-FLAG rrf'rotate right file and store it to itself or the accumulator‘ rlf 'rotate left file and store...‘ movlw 'fill accumulator with litteral value‘ movwf'transfer value from accumulator to file‘ btfss 'skip next instruction if designed bit is set' Status,Z = ZERO-FLAG SET? MULV8 CLRF RESULTMULU8LOOP MOVF TEMPX,W BTFSC TEMPY,0 ADDWF RESULT BCF STATUS,C RRF TEMPY,F BCF STATUS,C RLF TEMPX,F MOVF TEMPY,F BTFSS STATUS,Z GOTO MULU8LOOP RETURN
Multiplication for 16 bits ADD16 MOVF TEMPX16,W ADDWF RESULT16 BTFSC STATUS,C INCF RESULT16_H MOVF TEMPX16_H,W ADDWF RESULT16_H RETURNMULV16 CLRF RESULT16 CLRF RESULT16_HMULU16LOOP BTFSC TEMPY16,0 CALL ADD16 BCF STATUS,C RRF TEMPY16_H,F RRF TEMPY16,F BCF STATUS,C RLF TEMPX16,F RLF TEMPX16_H,F MOVF TEMPY16,F BTFSS STATUS,Z GOTO MULU16LOOP MOVF TEMPY16_H,F BTFSS STATUS,Z GOTO MULU16LOOP RETURN
Fixed-Point Arithmetic 0000000000001 1111111111111 • Representation Using 2’s Complement: Integer Part: 2m-1 positive values 2m negative values Fractional Part: [ 2-n, 1), with n bits Smallest Number: 2-n = Largest Number: ~ 1 Let us Suppose a Fractional Part with 10 bits The smallest fraction is: 2-10 = 1/ 1024 ~ 0.0009765 ~ 0.001 The largest fraction is: 1/21 + 1/22 + . . . + 1/210 = (210 –1)/210 = 1023/1024 ~ 0.99902 Where is the position of the decimal point ? Depends on the Application S m bits n bits 2 m-1 . . .. . . . 21 20 2-1 2-2 2-3 . . . . . 2-n
Class Exercise - 2 • Let us suppose an application (a software for construction engineers) that requires objects as small as 1mm, or as large as one medium size building, to be represented on the screen. Consider that the computer has a word length of 16 bits. • Suppose also that the image used by the application can be rotated by very small degrees (in fractions or radians) to give the illusion of continuous movement (The viewer can navigate inside the building like in a video game). • Devise and justify one possible fixed-point representation for this application that would be capable of satisfying the restrictions above. • Now suppose a flight simulator. What distances and object sizes can be represented using the same word partition above ?
Class-Exercise 3 - Represent the following real numbers (in base 10) in two’s complement fixed-point arithmetic, with a total of eight bits, being four bits in the fractional part and perform the following operations: A= + 4.75 = B= + 2.375 = A + B = A – B = WHAT IF ?: A =+ 5.5 = B = +7.5 = A + B =
Addition and Subtraction Using Fixed-Point Arithmetic • Addition: It all happens as if the number being added was an integer number. The integer unit of the ALU is used. Let us consider a number in two’s complement with a total of 8 bits and 4 bits in the fractional part: A= +4.75 = 0100.1100 B= +2.375= 0010.0110 A+B= +7.125= 0111.0010 => (propagates from the fractional part into the integer part) A-B=A+(-B) = > A= +4.75 = 0100.1100 -B=-2.375= 1101.1010 A+(-B)=+2.375= 0010.0110 WHAT IF ?: A =+ 5.5 = 0101.1000 B = +7.5 = 0111.1000 A + B =+13.0= 1101.0000 OVERFLOW !!!!!!!!!!!!!!!!!!!
Class-Exercise 4 - Represent the following numbers in two’s complement fixed-point arithmetic, with a total of eight bits and four bits in the fractional part and obtain their product. The result has to fit into 8 bits using the same representation: A= + 2.75 = B= + 2.375 = A * B =
Fixed-Point Multiplication Integer Integer Integer Fraction Fraction Fraction Underflow Overflow • Fixed-Point Arithmetic, together with Scaling, is Used to Deal with Integer and Fractional Values. • Overflow can Occur and has to be Treated by Software • Multiplication Example: A= +2.75 = 0010.1100 B= +2.375= 0010.0110 A * B = ? NOTES: If x = (0000 0000 . 0000 0011) Small Number x2 UNDERFLOW !! y = (0101 0000 . 0000 0000) Large Number y2 OVERFLOW !! 15 0 A = B = 31 0 (A * B)32 = Integer H Integer L Fraction H Fraction L SCALING 15 0 (A * B)16 =
Loosing Precision Because of Truncation • Consider an Application that uses two’s complement with a word length of 16 bits, 5 bits for the integer part and 10 bits for the fractional part. • Consider that we have to multiply a distance of 5.675 meters by the cosine of 450 (0.707). • The correct value should be: 5.675 * 0.707 = 4.012 A= 5.675 = 000101 .1000101011 (16 bits) B= 0.707 = 000000 .1011000011 (16 bits) A * B = 0000000000111101 001110 0011000001 (32 bits) A * B = 000011 .1101001110 (scaled to 16 ) A * B = 3.918 Because of Truncation, The result Differs by 2.3%
Does the Order of Computation Matter? • Let us consider: a = 48221; b = 51324 and c = 33600, three values that we want to add and scale so that the result is translated into a domain with a 10-bit fractional part. Should we scale before and add afterwards, or vice-versa? • Scaling Operands Before Performing Computations • Result1 = int[a:1024] + int[b:1024] + int [c:1024] = 129 • Scaling after adding the three values: • Result2 = int[(a + b + c) : 1024] = 130 • Result2 is more accurate than Result1 !! • CONCLUSION: Sometimes we have to change the order of the operations to obtain better results.
Some Comments About Arithmetic Operations on Embedded Systems • Many Arithmetic Operations can be Speeded Up by using tables. E.g. trigonometric functions, division • Software tricks (which would be very hard to implement in hardware) can be used in software to speed up arithmetic operations in embedded systems. • One of the techniques is to analyse the operands and take a decision about how many loops to iterate.
Floating-Point x Fixed-Point • Floating-Point - provides large dynamic range and Fixed-point does not. What about precision ? • A Floating-Point co-processor is very convenient for the programmer because he(she) does not have to worry about data ranges and alignment of the decimal point, neither overflow or underflow detection. In Fixed-Point, the programmer has to worry about all these problems. • However, a floating-point unit demands a considerable silicon area and power, which is not commensurate with low-power embedded devices. In fact, most DSP processors have avoided floating-point units because of these restrictions. • When there is no Floating-Point unit, most arithmetic and trigonometric functions have to be done in software.
Class Exercise 5 • Consider the following problem where numbers are in two’s complement, 8 bits total and 4 bits in fractional part. A = 7.5 B = 0.25 C = 6.25 We want to do: (A + B + C) / 3.25 1 – Can I perform the addition and then divide the result – does the result of the addition fit into the word length? What can I do? • What if: A = 0.25 B = 0.5 C = 0.125 We want to do: (A + B + C) / 1.25 * 6.0 2 – What happens if I perform the operations from left to right ? What can I do to avoid loosing significant bits during my operations ?
Block Floating Point Operations - I • Block Floating Point Provides Some of the Benefits of Floating Point Representation, but by Scaling Blocks of Numbers Rather than each Individual Number. • Block Floating Point Numbers are Represented by the Full Word Length of a Fixed Point Number. • If Any One of a Block of Numbers Becomes Too Large for the Available Word Length, the Programmer Scales Down all the Numbers in the Block, by Shifting Them to the Right. Example with word length = 8 bits. In the example, variables A, B, and C are the result of some computation and bits 8 and 9 do not fit into the original word length (overflow). To continue use them and maintain their relative values, they have to be scaled as a group (as a block), and undo the scaling operation later. • Example: A =10| 0001 . 1000 B = 00 | 0110 . 0000 C = 01 | 1001 . 0001 • Similarly, if the Largest of a Block of Numbers is Small, the Programmer Scales up all the Numbers in the Block to Use the Full Available word length of the Mantissa. Example with word length = 8 bits. A, B and C are the result of some previous computation (where there was an underflow – in yellow). If we scale up the block of variables we do not loose the least significant bits. We have to undo the scale up later to bring the result to its proper domain. • Example: A =0000 . 0100 | 1101 B = 0000 . 0010 | 1000 C = 0000 . 0011 | 1100 7654 3210
Block Floating Point Operations - II 0 0 0 1 1 0 0 0 0 0 0 1 1 0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 • This Approach is Used to Make the Most of the Mantissa of the Operands and also to Minimize Loss of Significant Bits During Arithmetic Operations with Scaling (Truncation). • EXAMPLE: Normalize Operands (Left shift until MSB=1) Values Before Values Afterwards S S 0 0 0 0 1 0 1 0 Shared Exponent 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1
Example 16-Bit word processor After converting our Floating-Point Representation into a Fixed-Point Representation, suppose that we have: A = 5000 B = 9000 C = 8000 Suppose that we have to perform: (-B + SQRT (B * B - 4 * A * C) ) / (2 * A) The Intermediate results of (B*B) and (4*A *C) are too big to fit into a 16-bit word. However, it is expected that the result fits into a 16-bit word. Thus, we can use a block floating-point representation by shifting the data by the same amount and then perform the operations. A = (5000 >> 10) (divide by 210 or 1024) => Thus, exponent = 10 B = (9000 >> 10) C = (8000 >> 10) After the operation the result is shifted back by the amount of bits specified by the exponent
Normalization Operations for 2´s Complement Numbers • To use Block Floating Point (and also other arithmetic operations) Normalization Operations are Required • Let us suppose 5-bit 2´s complement numbers. I have to calculate the normalization factor. How do I calculate it ? • Let us try with the numbers +2 (00010)2 and –2 (11110)2. • For positive numbers I do left shift 2 positions (x4) • For negative numbers I do left shift 3 positions (x8) • So I have two different normalization factors ? Does this work ? • It works because after the arithmetic operations, the resulting number is right shifted by the same amount. • Thus, calculate the number of left-shift positions (up to sign bit) for the most significant “1” for positive numbers and for the most significant “0” for negative numbers
Division It is much more Difficult to Accelerate than Multiplication Some Existing Methods of Implementation Are: • Shift and Subtract, or Programmed Division (Similar to Paper and Pencil Method) • Restoring Method • Non-Restoring Method • Division By Convergence – Obtain the Reciprocate (inverse) of the Divisor by some Convergence Method and Multiply it by the Dividend – Also a software method but it assumes that the Microprocessor has a hardware (very fast) multiplier. • Successive Approximation Methods to Obtain the Reciprocate of the Divisor. • Look-up table for the Reciprocate (Partial or Total) • High-Radix Division – Mostly Methods for Implementing in Hardware
Programmed (Restoring) Division Example – Integer Numbers ======== INTEGER DIV ===== z (dend) 0 1 1 1 0 1 0 1 = (117)10 24d 1 0 1 0 = (10)10 ========================= s(0) 0 1 1 1 0 1 0 1 2s(0) 0 1 1 1 0 1 0 1 -q3.24d 1 0 1 0 {q3=1} -------------------------------------------- s(1) 0 1 0 0 1 0 1 2s(1) 0 1 0 0 1 0 1 q2.24d 0 0 0 0 {q2=0} -------------------------------------------- s(2) 1 0 0 1 0 1 2s(2) 1 0 0 1 0 1 -q1.24d 1 0 1 0 {q1=1} -------------------------------------------- s(3) 1 0 0 0 1 2s(3) 1 0 0 0 1 q0.24d 1 0 1 0 {q0=1} -------------------------------------------- s(4) 0 1 1 1 s 0 1 1 1 = 7 (remainder) q 1 0 1 1 = 11 (quotient) This method assumes that the dividend has 2n bits and the divisor has n bits. The method is similar to the “paper and pencil” method. Negative numbers have to be converted to positive first. Firstly, compare the value of the divisor with the higher part of the dividend. If the divisor is larger, shift the dividend, subtract the divisor from the higher part and set the corresponding quotient bit to “1”. If the higher part of the shifted dividend is lower than the divisor, do not subtract anything from the higher part of the dividend and set the corresponding quotient bit to “0”. The number of iterations is equal to number of bits of the divisor. The remainder is left in the higher part of the dividend
Programmed (Restoring) Division Example – Fractional (Real) Numbers ======== FRACTIONAL DIV ===== z frac .0 1 1 1 0 1 0 1 = d frac .1 0 1 0 = ========================= s(0) . 0 1 1 1 0 1 0 1 2s(0) 0 .1 1 1 0 1 0 1 -q-1d .1 0 1 0 {q-1=1} -------------------------------------------- s(1) .0 1 0 0 1 0 1 2s(1) 0 .1 0 0 1 0 1 -q-2d .0 0 0 0 {q-2=0} -------------------------------------------- s(2) .1 0 0 1 0 1 2s(2) 1 .0 0 1 0 1 -q-3d .1 0 1 0 {q-3=1} -------------------------------------------- s(3) .1 0 0 0 1 2s(3) 1 . 0 0 0 1 -q-4d .1 0 1 0 {q-4=1} -------------------------------------------- s(4) .0 1 1 1 sfrac .0 0 0 00 1 1 1 (remainder) qfrac .1 0 1 1 (quotient) For Fractional, or Real, Numbers, the procedure is exactly the same as for integer numbers. The only difference is that the remainder, which is left in the higher part of the shifted dividend, has to be transferred to the lower part of it to be correct. Them main problem with this method is that it requires a comparison (can be done by subtraction) operation on each step. This implies in more clock cycles than necessary. The next slide shows NonRestoring Division, which is simpler to implement, either in software or in Hardware.
Nonrestoring Unsigned Division ========================= z 0 1 1 1 0 1 0 1 = (117)10 No overflow since in higher part: 24d 0 1 0 1 0 = (10)10 (0111)two < (1010)two -24d 1 0 1 1 0 ========================= s(0) 0 0 1 1 1 0 1 0 1 2s(0) 0 1 1 1 0 1 0 1 Positive, +(-24d) 1 0 1 1 0 so subtract -------------------------------------------- s(1) 0 0 1 0 0 1 0 1 2s(1) 0 1 0 0 1 0 1 Positive, so set q3=1 +(-24d) 1 0 1 1 0 and subtract -------------------------------------------- s(2) 1 1 1 1 1 0 1 2s(2) 1 1 1 1 0 1 Negative, so set q2=0 +24d 0 1 0 1 0 and add -------------------------------------------- s(3) 0 1 0 0 0 1 2s(3) 1 0 0 0 1 Positive, so set q1=1 +(-24d) 1 0 1 1 0 and subtract -------------------------------------------- s(4) 0 0 1 1 1 Positive, so set q0=1 s 0 1 1 1 = 7 (remainder) q 1 0 1 1 = 11 (quotient) z = Dividend s = Remainder d = Divisor The big Advantage of this Method is that it is easy to test and decide if we have to add or subtract the quotient on each iteration. This means a simple implementation.
Programmed Division Using Left Shifts – Pseudo ASM Rs(p.rem)Rq(rem/quot) Rd(divisor)000 . . . 000 Using left shifts, divide unsigned 2k-bit dividend, z_high | z_low, storing the k-bit quotient and remainder. Registers: R0 holds 0 Rc for Counter Rd for divisor Rs for z_high & rem Rq for z_low & quotient } {Load operands into regs Rd, Rs and Rq } div: load Rd with divisor load Rs with z_high load Rq with z_low {Check for exceptions } branch d_by_0 if Rd=R0 branch d_ovfl if Rs > Rd {Initialize Counter} load k into Rc {Begin division loop} d_loop: shift Rq left 1 {zero to LSB, MSB to cy} rotate Rs left 1 {cy to LSB, MSB to cy} skip if carry=1 branch no_sub if Rs < Rd sub Rd from Rs {2´s compl. Subtract} incr Rq {set quotient digit to1} No_sub: decr Rc {decrement counter by 1} branch d_loop if Rc 0 {Store the quotient and remainder } store Rq into quotient store Rs into remainder d_by_0: - - - - - d_ovfl: - - - - - d_done: - - - - - Even though it is an unsigned division, a 2’s complement subtraction instruction is required. Ignoring operand load and result store instructions, the function of a divide instruction is accomplished by executing between 6k+3 and 8k+3 machine instructions. For a 16-bit divisor this means well over 100 instructions on average.
Division Algorithm - 1 (http://www.sxlist.com/techref/microchip/math/div/24by16.htm )
Division Algorithm – 2 http://www.convict.lu/Jeunes/Math/Fast_operations2.htm Fast divisionfor PICs If you went through our fast multiplying, now try the fast division if you dare. The algorithm that has been applied here belongs to the CORDIC family. Also have a look at our CORDIC square-root function. Normally division-algorithms follow the way, children are tought to operate. Let's take an example: • 16546 is the numerator, 27 the divisor • z: start with the left-most digit: • if 1 < 27 then add the second digit • if 16 < 27 then add the third digit • 165 > 27, so integer-divide 165 div 27 = 6 • get the remainder, which is 165 - 6 * 27 = 3 • now restart at z with the remainder With RISC-technology, at assembler level, the tests are operated with substractions, checking whether the results are negative, zero or positive. The integer-division is done by successive substractions until the result is negative. A counter then indicates how often substractions were made. As already pointed out, CORDIC has a very different approach to mathematical operations. The incredible speed of the algorithms are the result from a divide and conquer approach. Practically let's have see how our CORDIC division works: Suppose you want to integer-divide 8710 = 10101112 through 610 = 1102. numerator 01010111 base_index := 00000001 = 1 divisor 00000110result:=0 • rotate divisor and base_index until the most significant bits of numerator and divisor are equal: 00001100 00000010 = 2 00011000 00000100 = 4 00110000 00001000 = 8 01100000 00010000 = 16 • now substract both numerator and altered divisor: 01010111- 01100000 ---------- < 0 • if negative -which is the case here- rotate back divisor and base_index one digit to the right: 00110000 00001000 = 8 • substract again rotated divisor from numerator: 01010111- 00110000 ---------- 00100111, positive remainder • now replace the divisor by the remainder: new numerator:= 00100111 • this time add the base_index to result: result:= result(0) + 8 = 8 • now rotate to the right divisor and base_index one digit: 00011000 00000100 = 4 • substract again: 00100111- 00011000 ---------- 00001111, remainder positive, so • new numerator:=00001111 • result:=result + base_index = 8+4 = 12 • rotate: 00001100 00000010 = 2 • substract : 00001111- 00001100 ---------- 00000011, remainder positive, so • new numerator:=00000011 • result:=result + base_index = 12+2 = 14 • rotate: 00000110 00000001 = 1 • substract : 00000011- 00000110 ---------- < 0, so do nothing • stop Here PIC 16F84 and 628 code: DIVV8 MOVF TEMPY8,F BTFSC STATUS,Z ;SKIP IF NON-ZERO RETURN CLRF RESULT8 MOVLW 1 MOVWF IDX16 SHIFT_IT8 BCF STATUS,C RLF IDX16,F BCF STATUS,C RLF TEMPY8,F BTFSS TEMPY8,7 GOTO SHIFT_IT8DIVU8LOOP MOVF TEMPY8,W SUBWF TEMPX8 BTFSC STATUS,C GOTO COUNT8 ADDWF TEMPX8 GOTO FINAL8 COUNT8 MOVF IDX16,W ADDWF RESULT8 FINAL8 BCF STATUS,C RRF TEMPY8,F BCF STATUS,C RRF IDX16,F BTFSS STATUS,C GOTO DIVU8LOOP RETURN SUB16 MOVF TEMPY16_H,W MOVWF TEMPYY MOVF TEMPY16,W SUBWF TEMPX16 BTFSS STATUS,C INCF TEMPYY,F MOVF TEMPYY,W SUBWF TEMPX16_H RETURNADD16BIS MOVF TEMPY16,W ADDWF TEMPX16 BTFSC STATUS,C INCF TEMPX16_H,F MOVF TEMPY16_H,W ADDWF TEMPX16_H RETURNDIVV16 MOVF TEMPY16,F BTFSS STATUS,Z GOTO ZERO_TEST_SKIPPED MOVF TEMPY16_H,F BTFSC STATUS,Z RETURNZERO_TEST_SKIPPED MOVLW 1 MOVWF IDX16 CLRF IDX16_H CLRF RESULT16 CLRF RESULT16_HSHIFT_IT16 BCF STATUS,C RLF IDX16,F RLF IDX16_H,F BCF STATUS,C RLF TEMPY16,F RLF TEMPY16_H,F BTFSS TEMPY16_H,7 GOTO SHIFT_IT16DIVU16LOOP CALL SUB16 BTFSC STATUS,C GOTO COUNTX CALL ADD16BIS GOTO FINALX COUNTX MOVF IDX16,W ADDWF RESULT16 BTFSC STATUS,C INCF RESULT16_H,F MOVF IDX16_H,W ADDWF RESULT16_H FINALX BCF STATUS,C RRF TEMPY16_H,F RRF TEMPY16,F BCF STATUS,C RRF IDX16_H,F RRF IDX16,F BTFSS STATUS,C GOTO DIVU16LOOP RETURN... somewhere in the code CALL DIVV16 Note that these programs work only for unsigned variables. Worst case for DIVV8 is about 144 cycles, which at 20 MHz is about 30 microseconds. The interest of this algorithm appears more clearly, if larger variables should be used.
CORDIC – Square Root http://www.convict.lu/Jeunes/Math/square_root_CORDIC.htm Square-root based on CORDIC We explained the CORDIC basics for trig-functions earlier. The solution of exercise 2 of that page will be shown here. But some preliminary explanations. Perhaps you know the following card-game: You tell a candidate to select and remind a number from 1 to 31. Then you show him the following five cards one by one. He must answer the question whether the number is yes or no written on that card. By miracle you can tell him the number he chose. The card-order is irrelevant. The trick is to mentally add the first number of each card where he answered YES. Let's take an example: the candidate chooses 23 • card 1: Yes, so mind 1 • card 2: Yes, so add 2 -->3 • card 3: Yes, add 4 -->7 • card 4: No, do nothing • card 5: Yes, add 16 -->23 How does this game work? By answering yes or no, the candidate is simply converting the decimal number 23 in a binary number: 2310 = 111012 = [Yes, Yes, Yes, No, Yes], where Yes=1 and No=0 Each card shows all the numbers with the same binary-digit set to 1. The quiz-master computes the reconversion to decimal by calculating the base-polynomial: 1 x 24 + 0 x 23 + 1 x 22 + 1 x 21 + 1 x 20 = 1 x 16 + 0 x 8 + 1 x 4 + 1 x 2 + 1 x 1 = 23 In fact CORDIC-algorithms are based on this sort of computing. The interest is of course the proximity of the binary-system to computer-systems. Multiplying by 2 is equivalent of shifting the binary number 1 digit to the left. Dividing by 2 is the same as rotating 1 digit to the right: 111012 x 210 = 1110102 111012 DIV 210 = 1110.12 These shift-operations are extremely quick. NOTE: in only one of our examples this shift-trick is used, for only few higher computer-languages allow access to these low-level functions. But CORDIC has another speed-advantage which comes from the exponential approach. Multiplying and dividing may be reduced to additions and substractions. To compute a square-root with CORDIC the number is yielded by multiplying, adding and testing. L 2^L y x= 12056 0 initial value 71280128 x 128 > 12056do nothing6646464 x 64 < 12056add 64 to yinitial --> 6453296(64 + 32)2< 12056add 32 to last y --> 9641696(96 + 16)2> 12056 do nothing 38104(96 + 8)2< 12056add 8 to last y --> 10424108(104 + 4)2< 12056add 4 to last y --> 10812108(108 + 2)2> 12056 do nothing 01109(108 + 1)2< 12056add 1 to last y --> 109-10.5a.s.o.and so on and so on Here a C-routine for integer-square-rooting for numbers between 0 and 65536: • int sqrt (int x) • { • int base, i, y ; • base = 128 ; • y = 0 ; • for (i = 1; i <= 8; i++) • { • y + = base ; • if ( (y * y) > x ) • { • y -= base ; // base should not have been added, so we substract again • } • base >> 1 ; // shift 1 digit to the right = divide by 2 • } • return y ; • } Here a Robolab-version: (you may use our text-based modifiers or use the variable numbers of your choice)