Download
1 / 31
320 likes | 590 Vues
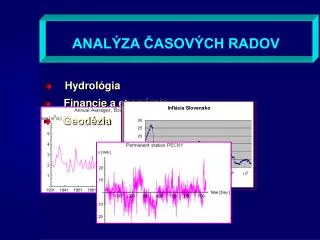
ANALÝZA ČASOVÝCH RADOV. Hydrológia. Financie a ekonómia. Geodézia. Množinu náhodných premenných {X( , t), , t T } kde je výberový priestor a T R + je indexová množina nazývame stochastický proces. Mnohorozmerný stochastický proces je množina náhodných vektorov

E N D
ANALÝZA ČASOVÝCH RADOV • Hydrológia • Financie a ekonómia • Geodézia
Množinu náhodných premenných {X(, t), , t T } kde je výberový priestor a T R+ je indexová množina nazývame stochastický proces. Mnohorozmerný stochastický proces je množina náhodných vektorov {X(, t), , t T }. Pre každé t T je X(., t) náhodná premenná definovaná na výberovom priestore . Pre každé je X(, .) jedna realizácia stochastického procesu definovaná na indexovej množine T, t. j. usporiadaná postupnosť čísiel, z ktorých každé odpovedá jednej hodnote indexovej množiny. V prípade, že T obsahuje len konečne, resp. spočitateľne veľa hodnôt, hovoríme o stochastickom procese s diskrétnym časom. Diskrétny časový rad tvorí množina pozorovaní {x1,x2,…,xn}, získaných v rovnakých časových intervaloch. Je to jedna realizácia stochastického procesu{X1, X2, …, Xt, ...}. Počet pozorovaní sa nazýva dĺžka časového radu n. Hlavnou úlohou analýzy časových radov je nájsť model dostatočne priliehavo aproximujúci pozorované údaje a potom (podľa možnosti) predpovedať budúce hodnoty.
Stredná hodnota: Rozptyl (druhý centrálny moment): Šikmosť (tretí centrálny moment): Špicatosť (štvrtý centrálny moment): Kovariančná funkcia (r, s): Korelačná funkcia (r, s): Charakteristiky stochastického procesu {Xt, t 0}
Stochastický proces je striktnestacionárny, ak sa jeho štatistické vlastnosti v čase nemenia (t. j. rozdelenia pravde-podobnosti sú invariantné v čase). Stochastický proces je striktnestacionárny, ak pre každú podmnožinu (t1, t2, ..., tn) indexovej množiny T a každé reálne číslo h R také, že tj + h T, j = 1, 2, ..., n sú združené distribučné funkcie vektorov rovnaké. • Stochastický proces je slabo (kovariančne) stacionárny, • ak: • t = E(Xt) = , 2t = D(Xt) =E(Xt - t )2 = 2 • pre t = 1, ..., n • (s, r) = cov(Xs, Xr) = E[(Xs - s)(Xr - r)] je len funkciou (s – r), t. j. ako sú od seba Xs, Xr v čase vzdialené a nie od toho, na akom úseku časovej osi sa nachádzajú. • Rozdiel s – rnazývame posunutie a budeme ho označovať k STACIONÁRNE STOCHASTICKÉ PROCESY Stacionárny proces s = 0 nazývame centrovaný.
Výberový priemer (odhad strednej hodnoty): Výberový rozptyl (odhad disperzie 2): Výberová šikmosť (odhad šikmosti (3)): Výberová špicatosť (odhad špicatosti (4)): Výberové charakteristiky stacionárneho stochastického procesu {Xt, t 0}
Príkazy na výpočet výberových charakteristík v systémeMathematica Ako prvé nahráme súbory na analýzu časových radov: <<timeseri\\datasmoo.m <<timeseri\\timeseri.m <<timeseri\\userfunc.m Výberový priemer (odhad strednej hodnoty): Mean[rad] Výberový rozptyl (odhad disperzie 2): Variance[rad] Štandardná odchýlka(odhad ):StandardDeviation[rad] Výberová šikmosť (odhad šikmosti (3)): Skewness[rad] Výberová špicatosť (odhad špicatosti (4)): Kurtosis[rad]
Výberová autokovariančná funkcia (k) Výberová autokorelačná funkcia rk= Vlastnosti (k) a rk 1. r0 = 1 2. | (k) | (0); | rk | 1 3. (k) = (-k); rk = r-k k Z V systéme Mathematica počítame autokovariančnú funkciu až do k-teho stupňa príkazom: CovarianceFunction[rad, k] V systéme Mathematica počítame autokorelačnú funkciu až do k-teho stupňa príkazom: CorrelationFunction[rad, k] Graf autokorelačnej funkcie pre k ≥ 0 sa nazýva korelogram.
Tvar autokorelačnej funkcie je veľmi dôležitý, pretože identifikuje príslušný lineárny model. Významná je predovšetkým hodnota k0, po ktorej už môžeme autokorelačnú funkciu považovať za nulovú. Ak existuje také k0, že pre všetky k > k0 je (k) = 0, potom je rozptyl výberovej autokorelačnej funkcie rk pre k > k0 daný Bartlettovou aproximáciou (za predpokladu normality uvažovaného procesu): D(rk) = Rozptyly autokorelácií r1, r2, ..., rk, ...
Parciálna autokorelačná funkcia Koreláciu premenných Xt a Xt-k očistenú o vplyv premenných medzi nimi Xt-1, …, Xt-k+1 nazývame parciálna autokorelačná funkcia. Počítame ju ako podmienenú strednú hodnotu : k, k = E[ (Xt - ) (Xt-k - ) | Xt-1, …, Xt-k+1] Výberová parciálna autokorelačná funkcia rk,ks posunutím k vyjadruje parciálny regresný koeficient k, k v autoregresii k-teho rádu: Xt = k, 1Xt-1 + … + k, kXt-k + et kde et je premenná nekorelovaná s náhodnými premennými Xt-j, j 1. V systéme Mathematica počítame parciálnu autokorelačnú funkciu až do k-teho stupňa príkazom: PartialCorrelationFunction[rad, k]
Z definície vyplýva, že proces bieleho šumu je stacionárny s autokorelačnou funkciou • a parciálnou autokorelačnou funkciou Proces bieleho šumu (White Noise) • Náhodný proces {Zt, t Z} tvorený nekorelovanými náhodnými premennými rovnakého pravdepodobnostného rozdelenia s konštantnou strednou hodnotou E(Zt) = (obyčajne = 0) a konštantným rozptylom D(Zt) = 2 sa nazývaproces bieleho šumu. Poznámka: Často budeme používať pojem postupnosť nezávislých rovnako rozdelených náhodných premenných (i. i. d), čo nie je ekvivalentné procesu bieleho šumu.
Nech Zt je proces bieleho šumu s nulovou strednou hodnotou, t. j. (k) = 0, k 0. Potom sú rozptyly výberovej autokorelácie aproximované hodnotami. Ak chceme rozhodnúť, či je (k) = 0, k 0, porovnáme hodnotu |rk| s číslom . Využíva sa pritom asymptotická normalita odhadu rk a pravidlo, že normálna náhodná premenná s nulovou strednou hodnotou prekročí v absolútnej hodnote dvojnásobok svojej smerodajnej odchýlky s približne 5%-nou pravdepodobnosťou. . Proces bieleho šumu sa nazýva Gaussovský, ak je jeho združené rozdelenie pravdepodobnosti normálne rozdelenie. Pokiaľ nepovieme ináč, budeme vždy uvažovať gaussovský biely šum.
DEKOMPOZÍCIA ČASOVÉHO RADU ØTrend Tt ØSezónna zložka St ØCyklická zložka Ct ØReziduálna zložka et
Trend Trendzachycuje dlhodobé zmeny v priemernom správaní sa časového radu (napr. dlhodobý rast alebo dlhodobý pokles). Vzniká ako dôsledok síl, ktoré systematicky pôsobia v rovnakom smere. • Izolovanie trendu - vyrovnávanie (smoothing) časového radu • Subjektívne metódy: • pre dlhé časové rady môžeme tvar trendu určiť z grafického zná- zornenia časového radu. Tieto metódy sú nedostačujúce, pretože nedávajú postačujúci základ pre konštrukciu predpovedí. Mali by sa však použiť pri predbežnej analýze časového radu, kedy je nutné rozhodnúť o výbere nejakej inej, objektívnejšej metódy 2) opis trendu matematickými funkciami (analytický popis trendu) : Pri takto odhadnutom trende môžeme ľahko vypočítať jeho budúce hodnoty (t. j. konštruovať predpovede budúcich hodnôt trendovej zložky, ak sa jej charakter v čase nezmení). Výber vhodnej funkcie závisí predovšetkým od grafického priebehu pôvodných empirických hodnôt časového radu a od výsledkov rozboru prvých, druhých, resp. ďalších diferencií v časovom rade.
Trend- pokračovanie b) Mechanické vyrovnávanie časových radov: Používame adaptívny prístup k trendovej zložke. Vo všeobecnosti ho používame pri takých trendoch, ktoré menia v čase globálne svoj charakter, takže pre ich opis nemôžeme použiť žiadnu matematickú funkciu s nemennými parametrami. Na druhej strane sa však predpokladá, že v krátkych časových úsekoch časového radu je vyrovnanie pomocou matematických kriviek možné, aj keď tieto krivky majú obyčajne v rôznych časových úsekoch odlišné parametre. Výhodou adaptívnych metód je, že proces eliminácie trendovej zložky sa adaptuje na okamžitý lokálny priebeh radu, konštrukcia predpovede pružne reaguje na časové zmeny v charaktere radu a v neposlednom rade je výhodou adaptívnych metód aj výpočtová jednoduchosť.
5 prvkov 12 prvkov 3 prvky Trend- pokračovanie 1) Metóda kĺzavých priemerov Využívajú sa pri nej kĺzavé priemery, čo sú priemery počítané vždy z obdobia určitej dĺžky (z určitého počtu hodnôt), pričom toto obdobie sa posunuje (“kĺže”). Pri vhodnej voľbe dĺžky kĺzavého obdobia sa dá ich aplikáciou odstrániť sezónnosť. Použitím kĺzavých priemerov strácame časť hodnôt na začiatku a na konci časového radu, pretože pre krajné pozorovania nemáme z čoho počítať priemery. Pri voľbe dĺžky kĺzavého obdobia treba brať do úvahy periódu sezónnych alebo cyklických fluktuácií, ktoré chceme z radu vyhladiť. Teda pri mesačných pozorovaniach sa odporúča dĺžka kĺzavého obdobia 12, pri kvartálnych 4 a pod.
W = 0,2 W = 0,8 Trend- pokračovanie 2) Exponenciálne vyrovnávanie Dĺžka kĺzavých priemerov podstatne ovplyvňuje trendovú zložku, určuje sa však väčšinou subjektívne. Metóda exponenciálneho vyrovnávania tento problém odstraňuje - výpočet každej vyrovnanej hodnoty je založený na všetkých dostupných minulých pozorovaniach časového radu. Každá staršia hodnota sa pritom berie s menšou váhou, pričom hodnoty váh smerom do minulosti exponenciálne klesajú. • Postup pre výpočet exponenciálneho vyrovnania je nasledovný: • Zvolíme váhu w (0, 1). Táto voľba je veľmi dôležitá. Obyčajne sa volí w 0.7, 1). Pri menšom w metóda rýchlo reaguje na zmeny v charaktere časového radu, pri väčšom w sa zosilní vyrovnávacia schopnosť metódy. • Exponenciálne vyrovnaný časový rad Ft vypočítame z pôvodného časového Yt nasledovne: • F1 = Y1; • F2 = (1 - w) * Y2 + w * F1; • . • . • . • Ft = (1 - w) * Yt + w * Ft-1.
Trend- pokračovanie Budeme používa analytický popis trendu (t. j. matematickými funkciami). Pri tomto prístupe sa obyčajne predpokladá, že analyzovaný časový má tvar Xt = Tt + et alebo bol na tento tvar upravený (predovšetkým sezónnym očistením). Tento predpoklad nám umožní použiť na odhad parametrov trendovej krivky lineárnu, resp. nelineárnu regresiu. V ďalšom nech n je dĺžka časového radu.
Trend - pokračovanie a) Konštantný trend: Pre tento trend typu Tt = 0, t = 1, …, n dostávame jednoduchý odhad b0 parametra 0 pomocou vzťahu: . Konštantný trend používame, ak xt+1 - xt 0.
Trend - pokračovanie b) Lineárny trend: Tt = 0 + 1t, t = 1, …, n kde odhady koeficientov 0, 1 dostaneme použitím lineárnej regresie. Lineárny trend používame, ak sú prvé diferencie xt+1 - xt približne konštantné. .
Trend - pokračovanie c) Kvadratický trend: Tt = 0 + 1t + 2 t2 , t = 1, …, n Odhady koeficientov 0, 1, 2 dostaneme opäť použitím lineárnej regresie. Kvadratický trend používame, ak sú druhé diferencie, t. j. xt+2 - 2 xt+1 + xt približne konštantné. .
Tento typ trendu sa používa na opísanie modelu rastu nových produktov, spoločností alebo priemyslu. Model trendu je rozdelený do troch častí: začiatok, rast, stav nasýtenia. Čas je reprezentovaný od dní cez mesiace až do rokov, v závislosti od stavu trhu. Je zrejmé, že tento model nemôžeme opísať ani lineárnym ani kvadratickým trendom. Vtedy používame exponenciálny trend, ktorý je opísaný funkciou: = 0.1, = 0.8 = 0.1, = 1.1 Trend - pokračovanie d) Exponenciálny trend: . Ak je 0, potom pre 1 dochádza k rastu, zatiaľ čo pre 0 1 nastáva pokles. Parametre a odhadneme pomocou nelineárnej regresie. Exponenciálny trend používame, ak sú podiely po sebe idúcich členov časového radu xt+1 / xt približne konštantné.
Trend - pokračovanie e) Logistický trend: Tento trojparametrový trend je opísaný funkciou: Schematicky je znázornený (pre = 1, = 30, = 0.95) Logistický trend má inflexný bod (t. j. zmenu konvexného priebehu na konkávny) v bode t = - log / log a je asymptoticky ohraničený hodnotou . . Kritérium pre jeho použitie je, aby podiely (1/xt+2 - 1/xt+1) / (1/xt+1 - 1/xt) boli približne konštantné.
KORELOGRAM Sezónna zložka Sezónna zložkaopisuje periodické zmeny v časovom rade, ktorých perióda sa rovná určitej štandardnej jednotke času alebo jej konštantnému násobku (zachycuje zmeny, ktoré sa pravidelne opakujú). Dĺžka periódy sa určuje z korelogramu. Rozbor eliminovanej sezónnej zložky môže podstatne rozšíriť naše vedomosti o zákonitostiach správania sa určitého javu a prispieť ku konštrukcii dokonalejších predpovedí u uvažovaného časového radu. Ďalším dôležitým cieľom je tiež získanie sezónne očisteného časového radu, z ktorého bola sezónna zložka odstránená alebo aspoň potlačená na maximálne možnú mieru. Sezónne očistený časový rad zbavený sezónnych a náhodných fluktuácií umožňuje efektívnejšie štúdium dlhodobých tendencií, ktorým je priebeh časového radu podriadený.
pre i = 2, 3, …, L. Sezónna zložka - pokračovanie Na určenie sezónnej zložky budeme používať regresné metódy založené na teórii lineárneho regresného modelu. 1.Metóda kvalitatívnych premenných. Ak na každý rok pripadne L pozorovaní (sezón) príslušného časového radu (napr. pri mesačných časových radoch L = 12, pri kvartálnych L = 4), potom pri tejto metóde vyjadrujeme sezónnu zložku v tvare: St = 2 Y2t + 3 Y3t + … + L YL t kde Y2t, Y3t, …, YL t sú kvalitatívne premenné, ktoré sú definované nasledujúcim spôsobom:
Sezónna zložka - pokračovanie V systéme Mathematica realizujeme model sezónnej zložky s periódou L (a počtom opakovaní M) metódou kvalitatívnych premenných nasledujúcou postupnosťou príkazov: f[i_, k_, t_] := If [(i – 1 + k*L) t < (i + k*L), 1, 0] x[i_, t_] := Sum[f[i, k, t], {k, 0, M - 1}] funkcie = Table[ x[i, t], {i, 2, L}]; regkp = Regress[dáta, funkcie, t]
Kvalitatívne premenné Goniometrické funkcie Sezónna zložka - pokračovanie 2.Pomocou vhodne zvolenej matematickej funkcie.Najčastejšie sa používajú goniometrické funkcie s dĺžkou periódy L : sin(2 t/L), cos(2 t/L). Sezónna zložka môže byť napr. vyjadrená v tvare: St = 0 + 1 sin(2 t/L) + 2 cos(2 t/L).
PERIODOGRAM Cyklická zložka Cyklická zložkaje periodická zložka, ktorej perióda nezodpovedá kalendárnym jednotkám. Je to nepravidelná fluktuácia okolo trendu, v ktorej sa strieda fáza rastu s fázou poklesu. Odhaduje sa metódami spektrálnej analýzy. .
Reziduálna zložkaostane v časovom rade po odstránení systematických zložiek. Je tvorená fluktuáciami v priebehu časového radu, ktoré nemajú rozpoznateľný systematický charakter. Aditívna dekompozícia: Xt = Tt + St + Ct + et Multiplikatívna dekompozícia: Xt = Tt . St . Ct . et Časové rady spravidla obsahujú reziduálnu zložku. Okrem nej môžu (ale nemusia) obsahovať aj jednu, dve alebo všetky tri systematické zložky.
Postup pri analýze časových radov Vykreslíme dáta, tvoriace časový rad. Takto získame základ-nú predstavu o charaktere časového radu. V prípade nejas-ných časových radov testami náhodnosti určíme, či časový rad obsahuje trend, resp. periodické zložky. V prípade, že časový rad obsahuje trend, určíme ho regresnou analýzou. Z reziduí vypočítame autokorelačnú funkciu a z nej odčítame periódu sezónnej zložky (ak existuje). Sezónnu zložku potom určíme regresnou analýzou. Spektrálnou analýzou určíme významné frekvencie pre cyklickú zložku, ktorú potom vypočítame regresnou analýzou ako súčet sínusov a cosínusov.
Postup pri analýze časových radov Testovaním nulovosti autokorelačnej funkcie rk overíme, či môžeme reziduálnu zložku považovať za proces bieleho šumu. Ak reziduálnu zložku tvoria navzájom korelované náhodné premenné, použijeme na jej modelovanie Box – Jenkinsovu metodológiu (lineárne modely ARMA v stacionárnom prípade), integrované modely ARIMA, resp. modely sdlhou pamäťou ARFIMA (v nestacionárnom prípade) alebo moderné nelineárne modely (modely s premenlivými režimami a pod.). Výsledný model môžeme použiť na popisné účely, resp. na predpovedanie budúcich hodnôt časového radu - prognózo-vanie.
LITERATÚRA HIPEL, K. W. - McLEOD A. I. (1992) Time Series Modelling of Water Resources and Enviromental Systems. In: Handbook of Hydrology (D. R. Maidment, editor), Elsevier SALAS, J. D. - DELLEUR, J. W. - YEVJEVICH, V. - W. L. LANE (1980) Applied modelling of hydrological time series. Water Resources Publications, Littleton, Colorado CIPRA, T. (1986) Analýza časových řad s aplikacemi v ekonomii. SNTL, ALFA Praha ARTL, J. (1999) Moderní metody modelování ekonomických časových řad. GRADA Publ. ARTL, J. – ARTLOVÁ, M. (2003) Finanční časové řady – Vlastnosti, metody modelování, příklady a aplikace, GRADA Publ. FRANSES, P. H. (1998) Time series models for business and economic forecasting. Cambridge University Press. FRANSES, P. H. – VAN DIJK, D. (2000) Non – linear time series models in empirical finance. Cambridge Univ. Press