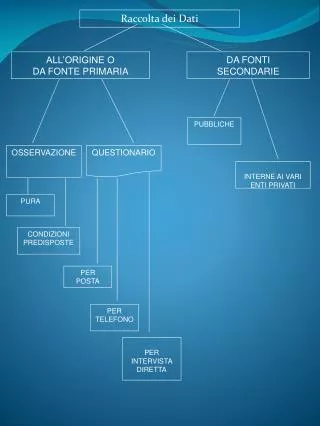
Modifica dei dati
Modifica dei dati. inserimento cancellazione modifica. Insert. insert into <NomeTabella> [(<colonna_i>, …, <colonna_j>)] values (<valore_i>, …, <valore_j>); deve essere specificato un valore per ogni colonna della lista se una colonna non è specificata , viene inserito il valore null


Modifica dei dati
E N D
Presentation Transcript
Modifica dei dati • inserimento • cancellazione • modifica SQL
Insert insertinto <NomeTabella> [(<colonna_i>, …, <colonna_j>)] values (<valore_i>, …, <valore_j>); • deve essere specificato un valore per ogni colonna della lista • se una colonna non è specificata, viene inserito il valore null • se non viene fornita la lista delle colonne, deve essere specificato un valore per ogni colonna della tabella così come appare nella istruzione create SQL
Esempio insert into PROGETTO (PNO, PNOME, COMPONENTI, BUDGET, PSTART, PMGR) values (313, 'BD', 3,150000.15, to_date('06-02-2001','dd-mm-yyyy'), 7411); insert into PROGETTO values (314, 'SI', 7411, 5, 350000.75, to_date('12-02-2001','dd-mm-yyyy'), null); SQL
Insert (2) insertinto <NomeTabella> [(<colonna_i>, …, <colonna_j>)] <querySQL>; create table VECCHI_IMP ( INO number(4) not null, ASS_DATA date); insert into VECCHI_IMP select INO, DATA_ASS from IMPIEGATI where DATA_ASS<'31-DIC-60'; SQL
Updates updates <tabella> set <colonna_i>=<espressione_i>, …, <colonna_j>=<espressione_j> [where <condizione>]; • espressione può essere • una costante, • una espressione funzionale, • una query SQL SQL
Esempio update IMPIEGATI set LAVORO='DIRIGENTE', DIPNO=20, STIPENDIO=STIPENDIO+1000 where INOME='FORD'; (Il sig. Ford ha avuto un avanzamento di carriera) SQL
Esempio update IMPIEGATI set STIPENDIO=STIPENDIO*1.15 where DIPNO in (10,30); (Gli impiegati dei dipartimenti 10 e 30 hanno avuto un aumento dello stipendio del 15%) SQL
Esempio update IMPIEGATI set STIPENDIO = (select min(STIPENDIO) from IMPIEGATI where LAVORO='DIRIGENTE') where LAVORO='VENDITORE' and DIPNO=30; (I venditori del dipartimento 30 ricevono lo stesso stipendio del manager che ha lo stipendio più basso) SQL
Delete delete from <tabella> [where <condizione>]; • senza la clausola where, vengono cancellate tutte le righe SQL
Esempio delete from PROGETTO where PEND < sysdate; (Cancella tutti i progetti terminati alla data odierna) SQL
Commit e Rollback • commit: rende permanenti le modifiche fatte durante l'ultima transazione • quit, create, drop realizzano un commit implicito • rollback: annulla le modifiche fatte durante l'ultima transazione SQL
Query su più tabelle (JOIN) select [distinct] [<alias_k>.]<colonna_i>, …, [<alias_m>.]<colonna_j> from <tabella_1>[<alias_1>], …, <tabella_n>[<alias_n>] [where <condizione>]; SQL
Alias Se colonne di tabelle diverse hanno lo stesso nome, è necessario usare la notazione <tabella>.<colonna> per eliminare ambiguità. Al posto di <tabella> si può usare l'alias SQL
Esempi select INOME, I.DIPNO, DIPNOME from IMPIEGATI I, DIPARTIMENTO D where I.DIPNO=D.DIPNO and LAVORO='VENDITORE'; select INOME, DIPNOME, PNOME from IMPIEGATI I, DIPARTIMENTO D, PROGETTO P where I.INO=P.PMGR and D.DIPNO=I.DIPNO; select I1.INOME, I2.INOME from IMPIEGATI I1, IMPIEGATI I2 where I1.CAPO=I2.INO; SQL
Query annidate • La condizione in una clausola where può contenere anche una query: select … where … (select …) subquery query annidata SQL
Interpretazione delle query annidate • viene eseguita la subquery • il risultato viene salvato in una tabella temporanea • il controllo della query esterna viene fatto sulle righe della tabella temporanea SQL
Regole per le query annidate • più condizioni possono essere combinate con gli operatori and, or • si può arrivare fino a 16 livelli di annidamento! • una query esterna non può far riferimento a tabelle della query più interna (viceversa è possibile) • se non specificato esplicitamente, i nomi di colonna fanno riferimento alle tabelle più “vicine” SQL
Subquery <espressione> [not] in (<subquery>) <espressione> <operatore_cfr> [any | all] (<subquery>) [not] exists (<subquery>) SQL
Esempio select INOME, STIPENDIO from IMPIEGATI where INO in (select PMGR from PROGETTO where PSTART < ’31-DIC-90’) and DIPNO=20; Seleziona gli impiegati del dipartimento 20 (ed il loro stipendio) che partecipano a progetti partiti prima del 31/12/90 SQL
Esempio select * from IMPIEGATI where DIPNO in (select DIPNO from DIPARTIMENTI where CITTA =‘BOSTON’); Seleziona gli impiegati dei dipartimenti di Boston Poiché la subquery ha come risposta un solo valore, si poteva usare = invece di in. SQL
Subquery correlata • Subquery che fa riferimento a colonne di tabelle utilizzate nella query principale • Non si può usare l’intepretazione vista per le query annidate!! SQL
Interpretazione delle subquery correlate • Per ogni riga della query esterna, • viene valutata la subquery • viene valutato il predicato della query esterna SQL
Esempio select * from IMPIEGATI I1 where DIPNO in (select DIPNO from IMPIEGATI [I2] where [I2.]INO=I1.CAPO); Seleziona i dipendenti che lavorano nello stesso dipartimento del loro capo SQL
any e all <espressione> <operatore_cfr> [any | all] (<subquery>) • confrontano <espressione> con ogni valore selezionato da <subquery> SQL
any • la condizione è vera se esiste almeno una riga selezionata dalla subquery per cui il confronto ha successo • se la subquery restiuisce un insieme vuoto, la condizione fallisce SQL
Esempio select * from IMPIEGATI where STIPENDIO >= any (select STIPENDIO from IMPIEGATI where DIPNO = 30) and DIPNO = 10 Seleziona gli impiegati del dipartimento 10 che hanno uno stipendio maggiore o uguale di almeno un impiegato del dipartimento 30 SQL
all • la condizione è vera se il confronto ha successo per tutte le righe selezionate dalla subquery • se la subquery restiuisce un insieme vuoto, la condizione ha successo SQL
Esempio select * from IMPIEGATI where STIPENDIO > all (select STIPENDIO from IMPIEGATI where DIPNO = 30) and DIPNO <> 30 Seleziona gli impiegati che non lavorano nel dipartimento 30 e che hanno uno stipendio maggiore di tutti gli impiegati del dipartimento 30 SQL
Equivalenze • in è equivalente a = any • not in è equivalente a <> all SQL
Exists [not] exists (<subquery>) • restituisce valore vero solo se l’interrogazione fornisce un risultato non vuoto [vuoto]. • ha senso solo per query correlate SQL
Esempio select * from DIPARTIMENTI where not exists (select * from IMPIEGATI where DIPNO=DIPARTIMENTI.DIPNO); Restituisce i dipartimenti che non hanno impiegati SQL
Operazioni su risultati di query <query_1> [union [all] | intersect | minus ] <query_2> SQL
union • Restituisce l'unione delle tuple risultato delle due query. Se non viene specificata la clausola all, i duplicati vengono eliminati select INO from IMPIEGATI union select CAPO from IMPIEGATI; SQL
intersect • Restituisce l'intersezione delle tuple risultato delle due query. select INO from IMPIEGATI intersect select CAPO from IMPIEGATI; SQL
minus • Restituisce le tuple che sono risultato della prima query ma che non sono risultato della seconda select INO from IMPIEGATI minus select CAPO from IMPIEGATI; SQL
Query con raggruppamento • Consentono di applicare le funzioni di gruppo non a tutte le righe ma a gruppi di righe che soddisfano certe proprietà select <colonna/e> from <tabella/e> where <condizione> group by <colonna/e_gruppo> [having <condizione/i_gruppo>]; SQL
Interpretazione • Le righe risultato della select che hanno gli stessi valori di <colonna/e_gruppo> vengono raggruppate. • Le funzioni di gruppo specificate nella select vengono applicate a ciascun gruppo separatamente. N.B. solo le colonne di <colonna/e_gruppo> possono essere listate nella clausola select senza funzioni di gruppo SQL
Esempi select DIPNO, min(STIPENDIO), max(STIPENDIO) from IMPIEGATI group by DIPNO; select DIPNO, min(STIPENDIO), max(STIPENDIO) from IMPIEGATI where LAVORO='VENDITORE' group by DIPNO; SQL
having • Dopo che i gruppi sono stati formati, se ne possono eliminare alcuni in base a certe condizioni select DIPNO, min(STIPENDIO), max(STIPENDIO) from IMPIEGATI group by DIPNO having count(*)>3; SQL
Accesso a tabelle di altri utenti • Per accedere a tabelle di altri utenti (sempre che se ne abbiano i privilegi) bisogna far precedere il nome di tabella dal nome dell'utente <user>.<tabella> SQL
Sinonimi • Si possono creare sinonimi sia per le proprie tabelle che per quelle di altri utenti: createsynonym <sinonimo> for [<user>.]<tabella>; SQL
Commenti alle definizioni • Si possono aggiungere commenti esplicativi alle definizioni di tabelle e alle colonne comment on table <tabella> is '<testo>'; comment on column <tabella>.<colonna> is '<testo>'; • I commenti sono inseriti nelle viste del dizionario dei dati USER_TAB_COMMENTD e USER_COL_COMMENTS SQL
Modifiche di definizioni • E' possibile modificare la struttura di una tabella • aggiungendo colonne • aggiungendo vincoli di tabella • modificando definizioni di colonne SQL
alter table alter table <tabella> add (<definizione_colonna>); alter table <tabella> add (<vincoli_di_tabella>) alter table <tabella> modify (<nuova_definizione_colonna>); SQL
Cancellazione di una tabella drop table <tabella> [cascade constraints]; Cancella le righe e la definizione di una tabella SQL
Viste Una vista è una tabella virtuale costruita selezionando righe e colonne di altre tabelle. Una vista può essere usata come le altre tabelle per la ricerca e per la modifica di dati. Una vista viene rivalutata ogni volta che vi si accede. SQL
Viste (2) createview <nome_vista> [(<colonna/e>)] as <query> [with check option [constraint <nome_vincolo>]]; • se (<colonna/e>) non viene specificato, le colonne della vista avranno lo stesso nome delle colonne selezionate • il vincolo with check option consente di rifiutare le modifiche e gli inserimenti di righe nella vista che non rispondono alla definizione, ovvero che non verrebbo selezionati dalla query SQL
Esempi create view DIP20 as select INOME, LAVORO, STIPENDIO*12 STIP_ANNUO from IMPIEGATI where DIPNO=20; create view DIP20 (INOME, LAVORO, STIP_ANNUO) as select INOME, LAVORO, STIPENDIO*12 from IMPIEGATI where DIPNO=20; SQL
Cancellazione di viste delete <nome_vista>; SQL
Vincoli di integrità • check constraint • limita i valori possibili per un attributo • foreign key constraint • specifica interdipendenze tra relazioni SQL