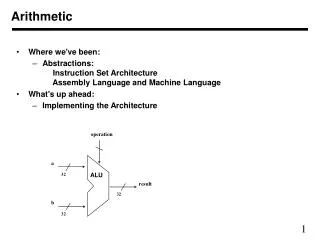
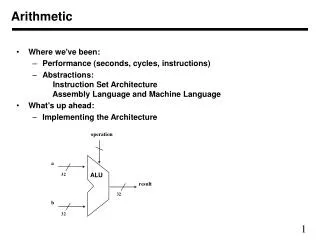
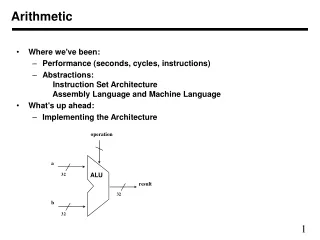
Exploring Distributed Arithmetic for Efficient Computation
Discover the potential of Distributed Arithmetic (DA) for highly efficient inner-product computation in digital signal processing hardware designs. Delve into how DA, despite being bit-serial, can significantly reduce gate count and speed up data-path circuit designing. Uncover the practical applications and advantages of utilizing DA in modern circuit design processes. Learn how DA works through bit-level rearrangement of multiply-and-accumulate operations, enhancing computational efficiency through ROM look-ups in FPGA implementations.


Exploring Distributed Arithmetic for Efficient Computation
E N D
Presentation Transcript
Definition • DA is basically (but not necessarily) a bit-serial computational operation that forms an inner (dot) product of a pair of vectors in single direct step. • Why is it called DA? DA is so named because the arithmetic operations that appear in single processing (+,-,*) are not “lumped” in a comfortable familiar fashion , but in an often unrecognizable fashion.
Motivation The extreme computational efficiency is the most important factor and that factor can be best exploited in circuit design. By careful design one may reduce the total gate count in a signal processing arithmetic unit by a number seldom smaller than 50 percent and often larger than 80 percent.
Is DA slow? Although it seems to be slow because of the bit-serial natural, but that is not real. 1- if the number of elements in each vector is commensurate with the number of bits in each vector element, e.g., the time required to input eight 8-bits words one at a time in parallel fashion is exactly the same as the time required to input all eight words serially 2-Other modifications to increase the speed may be made by employing techniques such as bit pairing or partitioning the input words into the most significant half and least significant half, the least significant half of the most significant half, etc.
So Why Use DA? • The advantages of DA are best exploited in data-path circuit designing • Area savings from using DA can be up to 80% and seldom less than 50% in digital signal processing hardware designs • An old technique that has been revived by the wide spread use of Field Programmable Gate Arrays (FPGAs) for Digital Signal Processing (DSP) • DA efficiently implements the MAC using basic building blocks (Look Up Tables) in FPGAs
Inner-product(DA example): • The following expression represents an inner-product (multiply and accumulate) operation • A numerical example 6
A FEW POINTS ABOUT THE INNER-PRODUCT • Consider this Note a few points • A=[A1, A2,…, AK] is a matrix of “constant” values • x=[x1, x2,…, xK] is matrix of input “variables” • Each Ak is of M-bits • Each xk is of N-bits • y should be able large enough to accommodate the result
A Possible Hardware for Inner-product 8-bits Adder 8-bits Multiplier
The realization of multiplier in Hardware • Add and shift method to realize a multiplier. • Example of 4 bits multiplier: (1011 * 0101) << + and 0000,0000 0000,0000 << and + 0000,1011 0000,0000 << and + 0001,0110 0001,0110 << and + 0010,1100 0011,0111
A POSSIBLE HARDWARE (NOT DA YET!!!) • Let, Shift right Registers to hold sum of partial products Multi-bit AND gate Each scaling accumulator calculates Ai X xi Adder/Subtractor Shift registers
How does DA work? • The “basic” DA technique is bit-serial in nature • DA is basically a bit-level rearrangement of the multiply and accumulate operation • DA hides the explicit multiplications by ROM look-ups an efficient technique to implement on Field Programmable Gate Arrays (FPGAs)
MOVING CLOSER TO DISTRIBUTED ARITHMETIC • Consider once again • Where Akare fixed coefficients, and Xk are the input data words. Xkis N-bits fraction signed number → | xk | < 1 xk: {bk0, bk1, bk2……, bk(N-1) } where bk0 is the sign bit We can express xkeither as signed and magnitude or as 2’s complement …(2)
CONTINUE …. • For two’s complement representation: From this point, the distributed arithmetic (DA) can be define Because this made the summation has only Instead of compute these value on line, we may precompute the values and store them in ROM with size . The input data (X) can be used to directly address the memory and the result can be dropped into an accumulator. This term represent the negative value of X, Therefore, we need a ROM of size to cover all the negative and positive value of X
By using the Rearrange equation The ROM comes Here
The ROM Construction • has only 2K possible values i.e. • (5) can be pre-calculated for all possible values of b1n b2n …bKn • We can store these in a look-up table of 2Kwordsaddressed byK-bits i.e. b1n b2n …bKn
Example: The memory must contain all possible combination (16 values). What about negative value?
Address 5 bits Data Continue…. It is a single-bit timing signal. During the sign-bit time the control signal Ts=1, otherwise Ts=0. 18
Adder and full Memory The input data (2’s-complement number) is delivered in a one-bit-at-a-time (1BAAT) fashion During the sign-bit time Ts= 1, otherwise, Ts=0 When SWA in position: 1- Add and Shift, during the accumulation time. 2- Pass the final result to y (output).
Key Issue: ROM Size • The size of ROM is very important for high speed implementation as well as area efficiency • ROM size grows exponentially with each added input address line • The number of address lines are equal to the number of elements in the vector plus one i.e. K+1 • Elements up to 16 and more are common => 217=128K of ROM!!! • We have to reduce the size of ROM
Solution of the memory size: • First solution is to reduce the size of memory to 2K instead of 2K+1 by modify the adder to adder/ subtractor and using Ts as add/sub-control line .
Solution of the memory size: • Second reduction can lead to reduce the ROM size to 2K-1. 2‘s-complement=1’s-complement+1
THE NEW FORMULATION IN OFFSET CODE Constant
THE BENEFIT: ONLY HALF VALUES TO STORE +ve Normal -ve Inverse symmetry inv
Hardware Using Offset Coding x1 selects between the two symmetric halves The rest of input data Ts indicates when the sign bit arrives
Increasing the Speed of DA • Because the data enter in serial ;One Bit At A Time (1 BAAT) • No. of Clock Cycles Required = N • If K=N, then essentially we are taking N clock cycle per dot product. • If K>N the DA processor is faster than single parallel multiplier/accumulator. • The speed can be increase interring L bit instead of one. • We could have 2 BAAT or up to N BAAT in the extreme case • N BAAT One complete result/cycle
Two bit at a time The same contain in both memories We can increase the parallelism as much as we want, but that will lead to increase the number of need gate. Two bits shift 29
INCREASE SPEED BY REDUCING THE CARRY PROPAGATION OF ADDER • The speed in the critical path is limited by the width of the carry propagation • Speed can be improved upon by using techniques to limit the carry propagation • Carry Save adder. • Carry-Skip adder • Carry-lookahead adder
Conclusion • DA is a very efficient means to mechanize computations that are dominated by inner products. • By using DA instead of traditional way, a huge reduction in area can be happened. • DA is not slow cause of it serial nature, yet sometimes it is faster than parallel one.