Download
1 / 1
20 likes | 464 Vues
User Selection of Clusters and Classifiers in Behavior Based Access Control. This work was sponsored by the Air Force Research Laboratory (AFRL). DISTRIBUTION A : Approved for public release; distribution unlimited (Case Number 88ABW-2013-1041).

E N D
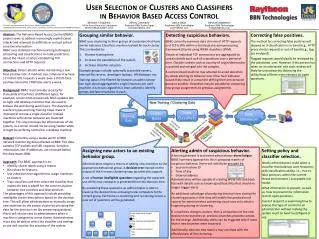
User Selection of Clusters and Classifiers in Behavior Based Access Control This work was sponsored by the Air Force Research Laboratory (AFRL). DISTRIBUTION A: Approved for public release; distribution unlimited (Case Number 88ABW-2013-1041) • Abstract: The Behavior-Based Access Control (BBAC) project seeks to address increasingly sophisticated attacks and attempts to exfiltrate or corrupt critical sensitive information. • BBAC uses statistical machine learning techniques (clustering and classification) to make predictions about the intent of actors establishing TCP connections and HTTP requests. • Objective: Detect attacks while maintaining a low false positive rate. A medium size company may have 17 million URL requests a week. Even a 0.01% false positive rate led to 1700 false alerts a week. • Background: BBAC must provide security for thousands of machines of different types, for example, servers that occasionally fetch updates late at night and desktop machines that are used to browse the web during work hours. The diversity of machine types and long training times make it impractical to have a single classifier. Instead machines with similar behavior are clustered together. This also increases the effectiveness of the system, as a server should not be using Twitter while it might be perfectly normal for a desktop machine. • Dataset: Currently using a weeks worth of BRO network monitor log data collected at BBN. This data samples TCP packets and URL requests. Sensitive information, like IP addresses, are removed before the data leaves BBN. • Approach: The BBAC approach is to: • Identify cluster labels using k-means • Bin values for features • Use a decision tree algorithm to assign machines to clusters • Train classifiers and then select the classifier that makes the best tradeoff for the current situation between true positives and false positives • The advantages of this approach include providing intelligible cluster descriptions based on the decision tree. This will allow administrators to manually assign new machines to the proper cluster by providing the data for the decision tree (by answering questions). Alerts will also be sent to administrators when a machine is assigned to a new cluster. Administrators must also be able to select the classifier and settings to use and monitor the accuracy of the system. Grouping similar behavior. BBAC uses clustering to form groups of computers that have similar behavior. Classifiers are then trained for each cluster. This is intended to: Shorten training time Increase the parallelism of the system Increase classifier accuracy Example groups include: externally accessible servers, internal file servers, developer laptops, HR desktops, etc. Training data is first filtered for features an administrator can logic about aggregated to single instances per each machine. A k-means algorithm is then utilized to identify groups and label machines in each. Correcting false positives. The method for correcting false positives will depend on if classification is in-band (e.g., HTTP proxy checks request) or out-of-band (e.g., logs are analyzed). Flagged requests would ideally be reviewed by the associated user. However, if this person has taken on an adversarial role such reviews will likely be untrustworthy. Balancing the utility/trust of these users remains an open questions. Detecting suspicious behaviors. BBAC currently examines data streams of HTTP requests and TCP traffic within a distributed stream processing framework (Storm) using WEKA classifiers (SVM). Details of individual TCP connections are aggregated to contain details such as # of connections over a period of time. Outside context such as country of origin/destination is queried and merged into the samples. A compromised machine may attempt to avoid detection by slowly altering its behavior over time. Such behavior would likely result in a machine drifting from one behavior group to another. Detection may be possible by comparing new group assignments to previous assignments. Is this machine a server? Yes No Is this machine using DHCP? Yes No Is this a shared machine? Yes No New Training / Clustering Data Training Data Data Streams in Train Classifiers Cluster Roles User traffic Suspicious clustering changes Classification results Admin Alerts Modifying classifier Assigning new machines to cluster Assigning new actors to an existing behavior group. Administrators require a means of adding new machines to the appropriate behavioral group. A decision treetrained on the output of the k-means clustering step provides this support. A set of human intelligible questions regarding the expected use of the new computeris generated from this decision tree. By answering these questions an administrator is able to traverse the decision tree and assign new computers to the correct group. Each time re-clustering and re-training occurs a new set of questions will be generated. • Alerting admin of suspicious behavior. • A key requirement is to prevent administrator alarm fatigue. BBAC’s primary approach to this is grouping reports of suspicious behavior. Alerts will initially be grouped by: • Source machine ID • Time of day • External address • Administrators will be capable of creating white lists and black lists with details such as known good/bad URLs that should no longer trigger alerts. • An additional advantage of producing decision trees during the clustering process is that they will enable the production of reports for administrators containing visual cues as to what is happening during re-clustering. • If a machines changes clusters, then a comparison of the new decision tree branches vs. previous branches provides context for the change. Additionally, alerts can be triggered only if more than n new branches were traversed. • Additionally, decision tree metrics may correlate with the effectiveness of the clustering. Setting policy and classifier selection. Ideally administrators could select a classifier that balances alert frequency with classification ability, i.e., true vs. false positives, within the current threat environment / acceptable risk model. What information to present, as well as, how to present this information remain open questions. Current research is examining how to expose this type of control to an administrator without making the system much to hard to configure or use. Server? Yes No Weekly connections Shared? <5 ≥5 Yes No





















