Summary and Future Work
X2. X3. X1. PVSAT. ANAPHYLAXIS. ARTCO2. X2. X3. X1. EXPCO2. SAO2. TPR. H. X2. X3. X1. HYPOVOLEMIA. LVFAILURE. CATECHOL. LVEDVOLUME. STROEVOLUME. ERRCAUTER. HR. ERRBLOW. HISTORY. Y1. Y2. Y3. H. CO. CVP. PCWP. HREKG. HRSAT. HRBP. Y1. Y2. Y3. BP. X2. X3. X 1.

Summary and Future Work
E N D
Presentation Transcript
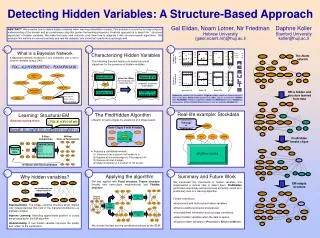
X2 X3 X1 PVSAT ANAPHYLAXIS ARTCO2 X2 X3 X1 EXPCO2 SAO2 TPR H X2 X3 X1 HYPOVOLEMIA LVFAILURE CATECHOL LVEDVOLUME STROEVOLUME ERRCAUTER HR ERRBLOW HISTORY Y1 Y2 Y3 H CO CVP PCWP HREKG HRSAT HRBP Y1 Y2 Y3 BP X2 X3 X1 X1 X1 X2 X2 X2 X3 X3 X3 X1 H Gal Elidan, Noam Lotner, Nir Friedman Hebrew University {galel,noaml,nir}@huji.ac.il Daphne Koller StanfordUniversity koller@huji.ac.il Y1 Y2 Y3 H Y1 Y2 Y1 Y1 Y1 Y2 Y2 Y2 Y3 Y3 Y3 Y3 H H Y1 Y2 Y3 X2 X3 X1 Stock Stock Tuberculosis Tuberculosis HR HR Summary and Future Work We introduced the importance of hidden variables and implemented a natural idea to detect them. FindHidden performed surprisingly well and proved extremely useful as a preliminary step to a learning algorithm. Further extensions: • Experiment with multi-valued hidden variables • Explore additional structural signatures • Use additional information such as edge confidence • Detect hidden variables when the data is sparse • Explore hidden variables in Probabilistic Relational Models X2 X3 X1 H Y1 Y2 Y3 H HR X3 Y1 Y2 Y3 X2 X1 Detecting Hidden Variables: A Structure-Based Approach ABSTRACT: We examine how to detect hidden variables when learning probabilistic models. This problem is crucial for for improving our understanding of the domain and as a preliminary step that guides the learning procedure. A natural approach is to search for ``structural signatures'' of hidden variables. We make this basic idea concrete, and show how to integrate it with structure-search algorithms. We evaluate this method on several synthetic and real-life datasets, and show that it performs surprisingly well. 1 4 7 What is a Bayesian Network 1200 600 600 120 Original Characterizing Hidden Variables The Alarm network 400 Hidden 800 400 80 A Bayesian network represents a joint probability over a set of random variables using a DAG : Naive Logloss on test data 200 400 200 40 0 This following theorem helps us to detect structural signatures for the presence of hidden variables: -200 0 0 0 P(X1,…Xn)=P(V)P(S)P(T|V) … P(X|A)P(D|A,B) A G M V H I L V H I L V 200 400 1000 150 Visit to Asia 0 Smoking RESULTS 200 Parents of H Parents of H 0 -200 100 preserve I-Map(not introducing new independencies) Score on Training data 0 -400 -1000 50 Tuberculosis Lung Cancer -200 -600 all parents connected to all children -2000 H 0 -800 -400 Bronchitis A G M V H I L V H I L V Abnormality in Chest Alarm 1k Alarm 10k Insurance 1k Clique over children of H HR is hidden and structure learned from data Children of H P(D|A,B) = 0.8 P(D|¬A,B)=0.1 P(D|A, ¬B)=0.1 P(D| ¬ A, ¬B)=0.01 Reference: network with no hidden. Original: golden model for artificial datasets; best on test data. Naive: hidden parent of all nodes; acts as a straw-man. Hidden: best FindHidden network; outperforms Naive and Reference, excels Original on training data. Efficient Frozen EM performs as well as inefficient FlexibleEM. Dyspnea X-Ray PVSAT ANAPHYLAXIS ARTCO2 EXPCO2 SAO2 2 5 8 TPR Real-life example: Stockdata The FindHidden Algorithm Learning: Structural EM HYPOVOLEMIA LVFAILURE CATECHOL • Search for semi-cliques by expansion of 3-clique seeds market trend: “Strong” vs. “Stationary” Bayesian scoring metric: LVEDVOLUME STROEVOLUME ERRCAUTER ERRBLOW HISTORY HIDDEN (MARKET TREND) Semi-Clique S with N nodes CO CVP PCWP HREKG HRSAT HRBP BP MICROSOFT DELL 3Com COMPAQ E-Step: Computation M-Step: Score & Parameterize FindHidden breaks clique Expected Counts N(X1) N(X2) N(X3) N(H, X1, X1, X3) ... Training Data PVSAT ARTCO2 + • Propose a candidate network: (1) Introduce H as a parent of all nodes in S (2) Replace all incoming edges to S by edges to H (3) Remove all inter-S edges (4) Make all children of S children of H if acyclic ANAPHYLAXIS all other nodes EXPCO2 SAO2 TPR Hidden HYPOVOLEMIA LVFAILURE CATECHOL re-iterate with best candidate LVEDVOLUME STROEVOLUME ERRBLOW HISTORY 3 6 9 CO CVP PCWP HREKG ERRCAUTER HRSAT Applying the algorithm HRBP Why hidden variables? BP EM was applied with Fixed structure, Frozen structure (modify only semi-clique neighborhood) and Flexible structure EM adapts structure not introducing new independencies PVSAT ANAPHYLAXIS ARTCO2 Structural EM Original network EXPCO2 SAO2 TPR Hidden Representation: The I-map—minimal structure which implies only independencies that hold in the marginal distribution—is typically complex Improve Learning: Detecting approximate position is crucial pre-processing for the EM algorithm Understanding:A true hidden variable improves the quality and “order” of the explanation Find Hidden HYPOVOLEMIA LVFAILURE CATECHOL LVEDVOLUME STROEVOLUME ERRCAUTER ERRBLOW HISTORY Structural EM CO CVP PCWP HREKG HRSAT HRBP BP We choose the best scoring candidate produced by the SEM