Deterministic and Stochastic MDPs in Robot Navigation: An Overview of Planning Frameworks
This overview discusses the frameworks for robot planning in both deterministic and stochastic environments, detailing the principles of Markov Decision Processes (MDPs) and partially observable Markov decision processes (POMDPs). It references foundational works by Bellman, Sutton, Barto, and others, explaining value iteration, the greedy policy, and the complexities of planning under uncertainty. The impact of state observability and action outcomes on navigation strategies is emphasized, providing insights into navigating complex environments influenced by uncertainty.

Deterministic and Stochastic MDPs in Robot Navigation: An Overview of Planning Frameworks
E N D
Presentation Transcript
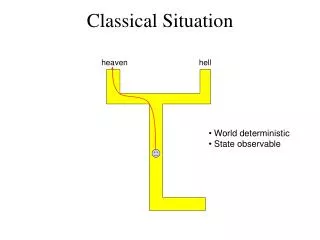
Classical Situation heaven hell • World deterministic • State observable
MDP-Style Planning • Policy • Universal Plan • Navigation function [Koditschek 87, Barto et al. 89] heaven hell • World stochastic • State observable
Stochastic, Partially Observable heaven? hell? sign [Sondik 72] [Littman/Cassandra/Kaelbling 97]
Stochastic, Partially Observable heaven hell hell heaven sign sign
Stochastic, Partially Observable start 50% 50% heaven hell ? ? hell heaven sign sign sign
MDP-Style Planning • Policy • Universal Plan • Navigation function [Koditschek 87, Barto et al. 89] heaven hell • World stochastic • State observable
Markov Decision Process (discrete) r=1 0.1 s2 0.9 0.7 0.1 0.3 0.99 r=0 s3 0.3 s1 r=20 0.3 0.4 0.2 s5 s4 r=0 0.8 r=-10 [Bellman 57] [Howard 60] [Sutton/Barto 98]
Value Iteration • Value function of policy p • Bellman equation for optimal value function • Value iteration: recursively estimating value function • Greedy policy: [Bellman 57] [Howard 60] [Sutton/Barto 98]
Value Iteration for Motion Planning(assumes knowledge of robot’s location)
Continuous Environments From: A Moore & C.G. Atkeson “The Parti-Game Algorithm for Variable Resolution Reinforcement Learning in Continuous State spaces,” Machine Learning 1995
Approximate Cell Decomposition [Latombe 91] From: A Moore & C.G. Atkeson “The Parti-Game Algorithm for Variable Resolution Reinforcement Learning in Continuous State spaces,” Machine Learning 1995
Parti-Game [Moore 96] From: A Moore & C.G. Atkeson “The Parti-Game Algorithm for Variable Resolution Reinforcement Learning in Continuous State spaces,” Machine Learning 1995
Stochastic, Partially Observable ? ? heaven hell ? ? hell heaven start start sign sign sign sign 50% 50%
A Quiz 3 perfect deterministic 3 perfect stochastic 3 abstract states deterministic 2-dim continuous*: p(S=s1), p(S=s2) 3 stochastic deterministic 3 none stochastic -dim continuous 1-dim continuous 1-dim continuous stochastic stochastic stochastic stochastic deterministic stochastic *) countable, but for all practical purposes # states sensors actions size belief space? 3: s1, s2, s3 3: s1, s2, s3 23-1: s1, s2, s3,s12,s13,s23,s123 2-dim continuous*: p(S=s1), p(S=s2) -dim continuous* -dim continuous* aargh!
Introduction to POMDPs (1 of 3) action b 100 -100 100 -40 80 0 a b a b action a -100 action b action a s1 s2 s1 s2 p(s1) [Sondik 72, Littman, Kaelbling, Cassandra ‘97]
Introduction to POMDPs (2 of 3) c 80% 20% s2’ p(s1’) s1’ s1 s2 p(s1) 100 -100 100 -40 80 0 a b a b -100 s1 s2 s1 s2 p(s1) [Sondik 72, Littman, Kaelbling, Cassandra ‘97]
Introduction to POMDPs (3 of 3) 30% 50% A A B B 70% 50% s2 p(s1’|B) p(s1’|A) s1 s1 s2 p(s1) 100 -100 100 -40 80 0 a b a b -100 c 80% s1 s2 s1 s2 p(s1) 20% [Sondik 72, Littman, Kaelbling, Cassandra ‘97]
Value Iteration in POMDPs Substitute b for s • Value function of policy p • Bellman equation for optimal value function • Value iteration: recursively estimating value function • Greedy policy:
Missing Terms: Belief Space • Expected reward: • Next state density: Bayes filters! (Dirac distribution)
Value Iteration in Belief Space state s next state s’, reward r’ observation o . . . . . . . . belief state b next belief state b’ Q(b, a) max Q(b’, a) value function
Why is This So Complex? ? State Space Planning (no state uncertainty) Belief Space Planning (full state uncertainties)
Augmented MDPs: uncertainty (entropy) conventional state space [Roy et al, 98/99]
Path Planning with Augmented MDPs information gain Conventional planner Probabilistic Planner [Roy et al, 98/99]