Continuous Analytics Over Discontinuous Streams
Sailesh Krishnamurthy, Michael Franklin, Jeff Davis, Daniel Farina, Pasha Golovko , Alan Li, Neil Thombre June 10, 2010 SIGMOD, Indianapolis. Continuous Analytics Over Discontinuous Streams. Founded in 2005 Roots in TelegraphCQ project from UC Berkeley HQ in Foster CIty , CA


Continuous Analytics Over Discontinuous Streams
E N D
Presentation Transcript
Sailesh Krishnamurthy, Michael Franklin, Jeff Davis, Daniel Farina, Pasha Golovko, Alan Li, Neil Thombre June 10, 2010 SIGMOD, Indianapolis Continuous Analytics Over Discontinuous Streams
Founded in 2005 Roots in TelegraphCQ project from UC Berkeley HQ in Foster CIty, CA Focus on “Continuous Analytics” Fortune 100 and web-based Big Data Customers
Stream Query Processing (Traditional View) Real-TimeAnalysis Update Display Source Data CQ Processor Data Records / “Events”
SQL Execution On Streaming Data Window Operator • Each window produces a set of records (a table) • Semantics: • Repeatedly apply generic SQL to the results of window operators • Results are continuously appended to the output stream • A stream is an unbounded sequence of records • A table is a set of records • Window operators convert streams to tables • SQL queries apply to tables
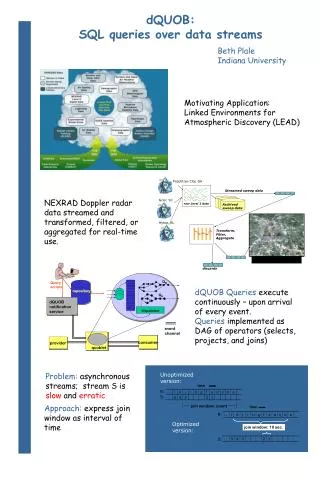
Example: SQL Queries over Streams Every 3 seconds, computethe revenue by advertiser based on impression data, over a 5 second “sliding window” Window Operator Clause SELECT I.Advertiser, SUM(I.price*I.volume) FROM Impressions I <VISIBLE ‘5 sec’ ADVANCE ‘3 sec’>, Campaigns C WHERE I.campaign_id= C.campaign_id and C.type = ‘CPM’ GROUP BY I.Advertiser “I want to look at 5 seconds worth of impressions” “I want results every 3 seconds” Window Impression Data Stream … Result(s) Result(s)
Assumptions About Streams 1, 2 3 4 7 5 8 6 Continuous sequences Arriving mostly in order
The Reality 10 5 5 6 1, 5, ? 4 9 3 4 9 3 4 2 Minutes, Hours, Days, late arriving Data Multiple streams out of sync, with gaps, … 3 2
Traditional (in Order) Solution #1: “Slack” 3-Second Slack Buffer Time Stamp Tuple # OUTPUT 1 1 1 2 2 1,2 3 3 1,2,3 4 2 1,2,2,3 5 6 6 1,2,2,3 6 5 5,6 7 1 5,6 8 9 9 5,6 9 8 8,9
Slack • Pros • Simple • Handles “jitter” (slightly out of order arrival) • Cons • Introduces delay • Permanently drops arrivals later than buffer • Unbounded buffer size • Permanently drops arrivals if lulls in multiple input streams
Traditional (in Order) Solution #2: “Drift” Source 1 Source 2 2-Second Drift Buffer OUTPUT (A,1)(a,2)(A,1) (B,2)(b,3)(a,2), (B,2) (C,3)(c,4)(b,3), (C,3) (G,4)(d,5)(c,4), (G,4) (D,6)(d,5) (E,7)(D,6),(E,7) (R,8)(E,7),(R,8)(D,6) (F,9)(x,5)(R,8),(F,9)(E,7) (z,10) (z,10)(R,8), (F,9)
Drift • Pros • Simple • Handles multiple streams with short “lulls” in arrival • Cons • Doesn’t handle streams with dramatically different arrival rates • Permanently drops data that arrives after drift window has expired
Traditional Solution #3: Order-agnostic Operators SELECT count(*), cq_close(*) ts FROM S <slices ‘5 seconds’> Slack and Drift aim to order streams before presenting them to order-sensitive operators Many operators don’t care about order
Out of Order Processing: Count Example Tuple # Time Stamp Count State Heart- Beat OUTPUT 1 1 1 2 3 2 3 2 3 4 4 4 5 5 (4,t=5) 6 6 1 7 2 1 8 9 2 9 7 3 10 3 3 11 10 (3,t=10)
Order-agnostic Operators • Pros • No buffering • No extra delays • Handles out-of-order tuples that make it before heart-beat • Cons • Some operators do care about order • Permanently drops data that arrives after heartbeat • Note: Lost data also impacts bigger “roll up queries” e.g. <slices 15 seconds> with sharing
“Stream-Relational” Architecture [CIDR 09] SQL Interface App Logic / UDFs Shared Stream Query Processor • JDBC / JMS • XML • Flat files • ETL tools • SOAP • APIs Raw Data Aggregates Integration Framework Other TrucQ’s Persistent Data Store Data Warehouse
Order-Independent Processing: Overview • Answers that have already been delivered can only be compensated • Need to preserve all arriving data • Queries return answers based on all relevant data that has arrived: • CQ’s: Continuous Queries • SQ’s: SQL queries on archived streams & answers • Approach: Leverage benefits of SQL(!): • Data-Parallel processing w/on-demand consolidation • Powerful “View” mechanisms • Basically, create parallel partitions for late data • Rewrite queries as views over partial results
Out of Order Processing: Count Example Tuple # Data TS Control Count State Partitions OUTPUT 1 1 1 2 3 2 3 2 3 4 4 4 5 2 5 6 1 6 7 5 (6,t=5) 8 6 1 9 2 1 1 10 9 2 1 11 7 3 1
Out of Order Processing: Count Example Tuple # Data TS Control Count State Partitions OUTPUT (6,t=5) 11 7 3 1 12 3 3 2 13 10 2 (3,t=10) 14 12 1 2 15 8 1 1(2,t=5) 16 4 1 1 17 3 1 2 18 9 22 19 15 22 (1,t=15) 20 flush-2 2(2,t=10) 21 flush-3(2,t=5)
Out of Order Processing: Count Example OUTPUT • Treat output as “Partial State Records” • Rewrite queries using views over PSRs • i.e., consolidate On-Demand • Paper goes into substantial detail on how rewrites work • <Slices 5 second> • Same answer as Order-Insensitive • <Slices 15 second> as roll-up • Answer contains all data • Subsequent SQs over archived results and raw data contain all data too! (6,t=5) (3,t=10) (2,t=5) (1,t=15) (2,t=10) (2,t=5)
Handles Very Late Data, Plus You Get… D U D High-bandwidth Network Interconnect U D Client Client Client D D Client D = Distributed Processing Node U = Unified Processing Node Parallel Processing – Multicore and Cluster
Other Details in the Paper • Beyond late data and parallelism, approach also is key to supporting: • Fault Tolerance using replication • High-Availability via fast restart • “Nostalgic” continuous queries that start in the past and catch up to the present • Fast concurrent creation of archives for new CQs • Algorithmic/Systems details on • Integration with overall system architecture • Interaction with Transaction Mechanism • Need for Background Reducer task • Hybrid Plans for non-parallelizable parts of queries
Conclusions For more info: sailesh@truviso.com or franklin@truviso.com • Early Stream Processing Systems were based on simplistic assumptions about ordering • Truviso’s 3.2 engine incorporates a new mechanism so no data is permanently dropped • Approach leverages strengths of SQL • Data-parallel processing models • Sophisticated and efficient view functionality • Key is On-Demand Consolidation • Of course, you can only do it if you have an integrated stream-relational system