End-to-End Data Exchange and Compression Overview
From the network's perspective, data travels as a stream of bytes. Application programs process these bytes with specific meaning and structure that needs encoding. Understand presentation formatting, taxonomy, and data compression like lossless algorithms. Learn about handling different data types, conversions, and encoding strategies. Discover examples like XDR, ASN.1, and NDR. Explore compression techniques such as Huffman coding and information measures like entropy.

End-to-End Data Exchange and Compression Overview
E N D
Presentation Transcript
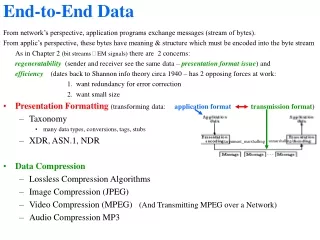
End-to-End Data From network’s perspective, application programs exchange messages (stream of bytes). From applic’s perspective, these bytes have meaning & structure which must be encoded into the byte stream As in Chapter 2 (bit streams EM signals) there are 2 concerns: regeneratability (sender and receiver see the same data – presentation format issue) and efficiency (dates back to Shannon info theory circa 1940 – has 2 opposing forces at work: 1. want redundancy for error correction 2. want small size • Presentation Formatting (transforming data: application formattransmission format) • Taxonomy • many data types, conversions, tags, stubs • XDR, ASN.1, NDR • Data Compression • Lossless Compression Algorithms • Image Compression (JPEG) • Video Compression (MPEG) (And Transmitting MPEG over a Network) • Audio Compression MP3 unmarshalling/ /argument_marshalling
Presentation Formatting Taxonomy /encoder Application data types supported by argument marshalling. Base types(int, float, char, ordinal, boolean) Encode-decode process must be able to convert from one representation to another eg, big-endian (most significant bit in a word is in high-addr byte) to little-endian: Flat types (structures, arrays…) complicate argument_marshalling e.g. marshalling must remove word-boundary padding inserted by compilers… Complex types(e.g., tree, etc - containing pointers from one structure to another) Marhalling process must serialize (flatten) for transmission e.g., Motorola 68x0 e.g., Intel 80x86 Byte orders for integer: 34,677,374
Presentation Formatting Taxonomy continued Conversion Strategy(for argument_marshalling/encoding)2 strategies: canonical intermediate(Settle on an external representation for each type sender translates to / receiver translates from) receiver-makes-right(Sender uses its own format - does not convert. Every receiver must be prepared to decode any format.) Tagged Data(tags are any additional structure that helps the receiver decode the data) type/length-tags (usually keyword tags e.g., type=INT, len=4) Stubs (code that implements arugment_marshalling) Can be interpreted or compiled (generated by a stub-compiler) Presentation Formatting Examples XDR (eXternal Data Representation) used by SunRPC supports C type system (but not ptrs); uses a canonical inermediate form; no tags (except for array length); uses compiled stubs. ASN.1 (Abstract Syntax 1) ISO standard; (BER = Basic Encoding Rules) supports C type system (but not ptrs); uses a canonical inermediate form; uses type tags; interpreted or compiled stubs; used in SNMP. NDR (Network Data Representation) DCE (Distributed Computing Environment of the OSF) standard; uses receiver-makes-right; compiles stubs from IDL (C-like Interface Description Language)
Compression Overview (in many inseparable from encoding) • Coding: • A code word is a sequence of bits. • A code is a mapping of source symbols (bits, characters, bytes, …) into code words. • A code is distinct if all its code words are distinct (different). • A distinct code is uniquely decodable if all its code words are identifiable when immersed in any sequence of code words from the code. • A uniquely decodable code is instantaneously decodable if its code words are identifiable when their final digits are received (eg, if no codeword is a prefix of another codeword). • Coding serves a wide variety of functions • Source coding converts a source signal to a form which minimizes demand on channel. • Line coding (e.g., NRZ, NRZI, Manchester, 4B/5B…) matches a signal to the propagation properties of the channel (timing, etc). • Channel coding detects (and sometimes corrects) errors (e.g., CRC, etc). • Huffman Encoding (source code) • Source codes which encode and compress. • Code words are listed in descending order of their probabilities (of occurrence). • Least probable code words are combined to give a new probability (sum of the two) recursively • 0 assigned to upper division and 1 is assigned to the lower division at each combination step. • Used in group-3 FAX
Huffman coding example Assume • 5 symbol information source: {a,b,c,d,e} • symbol probabilities: {1/4, 1/4,1/4,1/8,1/8} 1/1 0 1 4th low pair Symbol Codeword 1/2 1/2 a 00 b 01 c 10 d 110 e 111 0 1 0 1 1/4 00 01 1 10 0 2nd low pair c a b 110 111 1/4 1/4 1/4 e d 1/8 1/8 3rd low pair 1st low pair aedbbad.... is mapped into 00 111 110 01 01 00 110 ... Note: decoding can be done without commas or spaces – I.e., instantaneously decodable 17 bits
Information measures (info content & entropy) • Consider symbols x1, …, xn with probabilities, P(x1), ..,P(xn) • Let the information content conveyed by xi be I(xi) (the amount of uncertainty removed by the arrival of xi ). Then the relationships desired of this definition are: • If P(xi) = P(xj) then I(xi) = I(xj) . • If P(xi) < P(xj) then I(xi) > I(xj) (as the likelihood of a value goes up, the amount of uncertainty that value will remove goes down). • If P(xi) = 1 then I(xi) = 0. Many functions satisfy these conditions: I(x)=log(1/P(x)) (1/P(x))-1 (1/P(x)2)-1 … • I(x1x2x3) = I(x1) + I(x2) + I(x3) (Info content of a message= sum of info content of its symbols) The only smooth function that also satisfies this additive condition is: I(xi) = log(1/ P(xi)). • Entropy of a code is the average info content of all symbols in the code. Entropy(x1, x2,…, xn) = ni=1 P(xi) * I(xi) bits per symbol (here bits does not mean binary digits but “bits” of information)
Involve production of check bits by adding (Mod2: =XOR) different groups of info bits. Hamming(7,4) code has 3 check bits (c1, c2, c3) and 4 info bits (k1, k2, k3, k4) where c1 = k1 k2 k4 c2 = k1 k3 k4 c3 = k2 k3 k4 The set of code words is: k1k2k3k4c1c2c3 0000000 0100101 0001111 0101010 0010011 0110110 0011100 0111001 1000110 1100011 1001001 1101100 1010101 1110000 1011010 1111111 Hamming coding (channel code which detects and corrects errors) If any bit is added to itself the result is 0 so 0 = c1 c1= k1 k2 k4 c1 0 = c2 c2 = k1 k3 k4 c2 0 = c3 c3 = k2 k3 k4 c3 Considering the matrix multiplication: 1 1 0 1 1 0 0 x1 s1 1 0 1 1 0 1 0 x2 = s2 HX=S 0 1 1 1 0 0 1 x3 s3 S=0 iff X is valid code word. x4 s4 x5 s5 Method fails if S=0 but there x6 s6 is an error, E0 (Let B be the x7 s7 code word sent, i.e., X=B+E) If part. Only if follows from dim(HX=0)=4. S, the syndrome For any errantly received codeword, X=B+E, there are 16 possible sent code words, B. Hamming correction uses probabilities of occurrence to pick among them. (not perfect). Check matrix, H X, transpose of received codeword X = (x1…x7) Weight = 1-count If 0=S=HX=H(B+E)=HB+HE=0+HE = HE So the method fails iff E is a nonzero codeword. Hamming distance, d(X1,X2) = # positions where they differ = w(X1X2). By sum of codewords is a codeword minimum distance, dmin, between 2 codewords= smallest w of a nonzero codeword Which implies transmissions with fewer than dmin errors are detectable.
Compression Overview continued • Lossless:data received = data sent (used for executables, text files, numeric data...) • Lossless Algorithms • Run Length Encoding (RLE) e.g., AAABBCDDDD encoding as 3A2B1C4D • good for scanned text (8-to-1 compression ratio) • can increase size for data with variation (e.g., some images) • Differential Pulse Code Modulation (DPCM) e.g., e AAABBCDDDD encoding as A0001123333 • change reference symbol if delta becomes too large • works better than RLE for many digital images (1.5-to-1) • Dictionary-based Methods • Build dictionary of common terms (variable length strings) • Transmit index into dictionary for each term (e.g., the word “compression” is the 4978th entry in the dictionary, /usr/share/dict/words – has 25K words, so 15 bit indicies) • Lempel-Ziv (LZ) is the best-known example (e.g., UNIX compress command) • Commonly achieve 2-to-1 ratio on text • Variation of LZ used to compress GIF images • first reduce 24-bit color to 8-bit color (pick 256 closest, map using nearest nbr) • not uncommon to achieve 10-to-1 compression (x3) • Lossy • data received data sent (used for images, video, audio…)
JPEG compression Source Compressed image image DCT Quantization Encoding Image Compression JPEG: Joint Photographic Expert Group (ISO/ITU) is lossy still-image compression Three phase process Process in 8x8 block chunks (macroblock) Discrete Cosine Transform (DCT) transforms signal from spatial domain into an equivalent signal in the frequency domain (loss-less). Apply a quantization to the results (lossy) following the pattern: Quantization Table is used to give a different divisor (Qij) 3 5 7 9 11 13 15 17 for each coefficient. 5 7 9 11 13 15 17 19 7 9 11 13 15 17 19 21 Coefficients are rounded as follows: 9 11 13 15 17 19 21 23 QVij = IntRnd(DCTij)/ Qij 11 13 15 17 19 21 23 25 IntRnd(x)= x +.5 if x 0 13 15 17 19 21 23 25 27 x -.5 if x 0 15 17 19 21 23 25 27 29 and for decompressing, DCT ij = Qvij * Qij 17 19 21 23 25 27 29 31 • RLE-like encoding (loss-less) Encoding pattern
Input Frame 1 Frame 2 Frame 3 Frame 4 Frame 5 Frame 6 Frame 7 stream MPEG compression Forward prediction Compressed I frame B frame B frame P frame B frame B frame I frame stream Bidirectional prediction MPEG (Motion Picture Expert Group) MP3 is the audio standard of MPEG. (interleave and/or compress audio of a movie) Lossy compression of video 1st approx: JPEG on each frame Also remove inter-frame redundanc Briefly, the scheme involves: Frame types • I frames: intrapicture • P frames: predicted picture • B frames: bidirectional predicted picture B and P frames detail the delta (changes) from I frame to I frame (details in the text) Effectiveness • typically 90-to-1 • as high as 150-to-1 • 30-to-1 for I frames • P and B frames get another 3 to 5x