Enhancing Join Processing Efficiency for Uncertain Data in Databases
110 likes | 241 Vues
This paper addresses the challenge of efficiently joining databases with uncertain attributes, extending traditional join techniques. It emphasizes the need for improved algorithms to handle complexities inherent in uncertain data, particularly in applications like GPS, real-time sensor data, and scientific weather data. By introducing innovative pruning techniques based on uncertainty intervals, the authors propose methods such as page and index level joins that enhance I/O throughput and overall performance. Experimental results demonstrate the effectiveness of these new approaches in managing uncertain data.

Enhancing Join Processing Efficiency for Uncertain Data in Databases
E N D
Presentation Transcript
Efficient Join Processing over Uncertain Data - By Reynold Cheng, et all. Presented By Lydia & Usha
Main Idea The main key point addressed in this paper is extending traditional join techniques to DBs with uncertain attributes. Improving the efficiency of join based algorithms to address some of the complexities faced by DB management in handling joins over uncertain data. Efficient pruning techniques involving both uncertainty interval and uncertainty pdf.
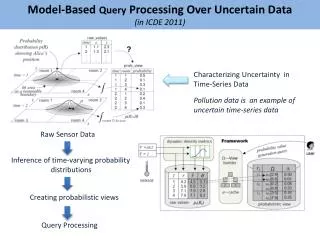
Importance of the problem • Often spatial DB applications have to deal with uncertain data. For example • GPS data which calculates nearest neighbour • Sensor data from realtime applications • Scientific data corresponding to weather.
Key concepts Addresses the semantic complexities of uncertain data Using probabilistic threshold joins. Define uncertainty comparison operators & probabilistic join queries. Proposes novel techniques like page and index level joins which incorporates efficient pruning techniques and evaluating the performance of those algorithmsover uncertain data.
Probabilistic uncertainty model Uncertainty interval & uncertainty pdf.
Index level Join Used to improve IO throughput When combined with node level pruning technique, this improves performance as well as IO throughput. In this pages are organized in an ordered tree structure, allowing one to use MBR which tightly encloses the interval within the subtree.