Advanced Pipeline Issues
This document details the complexities and methodologies of handling exceptions in advanced pipeline architectures. It explores the dual nature of exceptions—interrupts and traps—and explains how systems manage control transfers during abnormal program execution. Various types of exceptions are discussed, including I/O requests and arithmetic errors, along with their corresponding handling strategies. Furthermore, the text delves into pipelining complications that arise during simultaneous instructions and provides insights into superscalar architectures that maximize instruction-level parallelism, ultimately enhancing performance.


Advanced Pipeline Issues
E N D
Presentation Transcript
Computer Organisatie 2005/06 - Andy D. Pimentel Advanced Pipeline Issues
Exceptions System Exception Handler user program • Exception = unprogrammed control transfer • system takes action to handle the exception • must record the address of the offending instruction • record any other information necessary to return afterwards • returns control to user • must save & restore user state Exception: return from exception normal control flow: sequential, jumps, branches, calls, returns
Two Types of Exceptions • Interrupts • caused by external events • asynchronous to program execution • may be handled between instructions • simply suspend and resume user program • Traps (or Exceptions) • caused by internal events • exceptional conditions (overflow) • invalid instruction • faults (non-resident page in memory) • internal hardware error • synchronous to program execution • condition must be remedied by the handler • instruction may be retried or simulated and program continued or program may be aborted
Exception Examples • I/O request: device requests attention from CPU • System call or Supervisor call from software • Breakpoint or instruction tracing: software debugging, single-step • Arithmetic: Integer or FP, overflow, underflow, division by zero • Page fault: requested virtual address was not present in main memory • Misaligned address: bus error • Memory protection: read/write/execute forbidden on requested address • Invalid opcode: CPU was given an wrongly formatted instruction • Hardware malfunction: CRC errors, component failure
Exception Handling • Table of Interrupt vector addresses • Base register of this table stored in CPU by OS • Addresses of Interrupt handling routines are stored in table • On interrupt, CPU jumps to: base + 4 * int_num • Usually 16 or 32 interrupts • Physical pins on CPU, as well as software calls
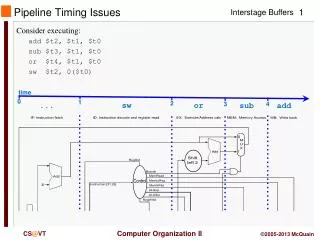
Pipelining Complications • Exceptions: 5 instructions executing in 5-stage pipeline • How to stop the pipeline? • How to restart the pipeline? • Who caused the exception? • StageProblem exceptions occurring IF Page fault on instruction fetch; misaligned memory access; memory-protection violation ID Undefined or illegal opcode EX Arithmetic interrupt MEM Page fault on data fetch; misaligned memory access; memory-protection violation
Pipelining Complications • Simultaneous exceptions in more than one pipeline stage, e.g., • Load with data page fault in MEM stage • Add with instruction page fault in IF stage • Add fault will happen BEFORE load fault • Solution #1 • Interrupt status vector per instruction • Defer check till last stage, kill state update if exception • Solution #2 • Interrupt ASAP • Restart everything that is incomplete • Another advantage for state update late in pipeline!
Stopping and Starting Execution • Most difficult exception occurrences have 2 properties • They occur within instructions • They must be restartable • The pipeline must be shut down safely and the state must be saved for correct restarting • Restarting is usually done by saving PC of instruction at which to start • Branches and delayed branches require special treatment • Precise exceptions allow instructions just before the exception to be completed, while restarting instructions after the exception
Superscalar Proposal • Go beyond single instruction pipeline, achieve IPC > 1 • Dispatch multiple instructions per cycle • Geared for sequential code that is hard to parallelize otherwise • Exploit fine-grained or instruction-level parallelism (ILP)
Classifying ILP Machines • Baseline scalar RISC • Issue parallelism = IP = 1 • Operation latency = OP = 1 • Peak IPC = 1
Classifying ILP Machines • Superpipelined: cycle time = 1/m of baseline • Issue parallelism = IP = 1 inst / minor cycle • Operation latency = OP = m minor cycles • Peak IPC = m instr / major cycle (m x speedup?)
Classifying ILP Machines • Superscalar: • Issue parallelism = IP = n inst / cycle • Operation latency = OP = 1 cycle • Peak IPC = n instr / cycle (n x speedup?)
Classifying ILP Machines • VLIW: Very Long Instruction Word • Issue parallelism = IP = n inst / cycle • Operation latency = OP = 1 cycle • Peak IPC = n instr / cycle = 1 VLIW / cycle
Classifying ILP Machines • Superpipelined-Superscalar • Issue parallelism = IP = n inst / minor cycle • Operation latency = OP = m minor cycles • Peak IPC = n x m instr / major cycle
Superscalar vs. Superpipelined • Roughly equivalent performance • If n = m then both have about the same IPC • Parallelism exposed in space vs. time
Superpipelining “Superpipelining is a new and special term meaning pipelining. The prefix is attached to increase the probability of funding for research proposals. There is no theoretical basis distinguishing superpipelining from pipelining. Etymology of the term is probably similar to the derivation of the now-common terms, methodology and functionality as pompous substitutes for method and function. The novelty of the term superpipelining lies in its reliance on a prefix rather than a suffix for the pompous extension of the root word.” - Nick Tredennick, 1991
Out-of-Order (OoO) execution • Nowadays, most general-purpose processors are superscalar with out-of-order execution • Instructions are dynamically scheduled to one of the parallel pipelines • Instructions • enter the processor in-order • are executed out-of-order • write-back their results in-order again • Requires substantial hardware support, e.g. • OoO control : find dependencies and adhere to them • Using solutions from the 1960’s! • Additional physical registers • Pentium 4 has only 8 “architectural registers” but 128 physical registers
Out-of-Order execution (cont’d) • ReOrder Buffer (ROB) is a popular mechanism to control OoO execution d d head (first entry) tail (next instruction to write-back) d = dispatched instruction x = executing instruction f = finished instruction x f d x
Microarchitecture: where are we coming from and where are we heading? Instruction Supply Execution Mechanism Data Supply Highest performance means generating the highest instruction and data bandwidth you can, and effectively consuming that bandwidth in execution – paraphrased from M. Alsup, AMD Fellow
Microarchitecture, 1990 • Short pipelines • On-chip I and D Caches, blocking • Simple prediction
Microarchitecture, 2000 • Mechanisms to find parallel instructions • dynamic scheduling • static scheduling • On-chip cache hierarchies, with non-blocking, higher-bandwidth caches • Sophisticated branch prediction
Where are we heading? • More ILP : Even wider, deeper • enabling technology: speculation, predication, compiler transformations, binary re-optimization, complexity effective design • Multithreading • enabling technology: speculation, subordinate threads, discovery of thread-level parallelism • Chip Multiprocessors • enabling technology: speculation, discovery of thread-level, course-grained parallelism
More ILP • Instruction Supply • Branches, cache misses, partial fetches • Data Supply • Higher bandwidth, lower latency, memory ordering, non-blocking caches • Execution • Reduction of redundant work, design complexity and partitioning • Tolerating Latency • Can some things just take a long time?
Multithreading[Burton Smith, 1978] WriteBack Execute Fetch • This is a snapshot of the pipeline during a single cycle. • Each color represents instructions from a different thread. • B. Smith’s original concept was for a single-wide pipeline, but extends naturally to a multiple issue pipeline.
Simultaneous Multithreadiing[W. Yamamoto, 1994/D. Tullsen, 1995] WriteBack Execute Fetch
Simultaneous Multithreading,possible implementation Front End Back End • Intel Hyperthreading in Pentium 4 is first realization with two threads • Small ISA register file minimizes effect of replication • Replicated retirement logic • Minimal hardware overhead but major increase in verification cost
Chip Multiprocessor[K. Olukotun, 1996] WriteBack Execute Fetch Single processor die contains multiple CPUs all of which share some amount of resources, such as an L2 cache and chip pins Shared L2 Cache ProcA ProcC ProcB ProcD
MPEG VIDEO ARM ACCESS CTL. Philips Nexperia (Viper) Intel IXP1200 Network Processor MSP VLIW MICRO- MIPS ENGINES Existing Solutions… … what’s next? … IBM Cell