Linking
Linking. Holland, P.W., & Dorans , N.J. (2006). Linking and equating. In R.L. Brennan (Ed.), Educational measurement (4 th ed.). Westport, CT: American Council on Education and Praeger Publishers. Linking.


Linking
E N D
Presentation Transcript
Linking Holland, P.W., & Dorans, N.J. (2006). Linking and equating. In R.L. Brennan (Ed.), Educational measurement (4th ed.). Westport, CT: American Council on Education and Praeger Publishers.
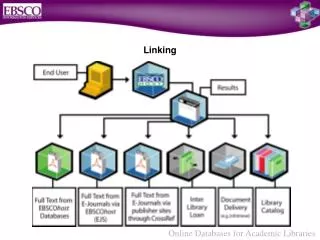
Linking • A Link is a connection made between two tests by transforming a score on one test to a score on the other test. • Linking, or transforming scores, can be done in one of three ways: • Predicting • Scale aligning (scaling) • Equating
Linking X to Y Predicting Y from X Scaling X and Y Equating X to Y Best Prediction Comparable Scales Interchangeable Scores Source: Holland & Dorans
Linking Method 1: Prediction To predict a score on one test with other information, typically including a score on another test. The prediction is E(Y | X = x, P) The error of prediction is y - E(Y | X = x, P) However, the prediction of Y from X is not the same as the prediction of X from Y
Appropriate use of Prediction One may use PSAT scores to predict (forecast) how students will perform on the SAT in the near future. Because of the sample-specific nature of this prediction, it may not hold in another sample from the population if that sample distribution differs from the original sample distribution.
Linking Method 2: Scaling • To place the scores from two different tests on a common scale through some transformation. • Scaling can be done for two cases: • Linking measures of different constructs • Linking measures with similar constructs, but different test specifications
Scaling: Different Constructs/ Common Population A common example of measures of different constructs for a common population includes battery scaling, as in the case of a large test composed of a battery of measures (reading, mathematics, language use). When the SAT-I was recentered, both the mathematics and verbal scores were given the same mean and standard deviation as a reference population from 1990.
Scaling: Different Constructs & Populations with Anchor Measures Anchor scaling can be done with measures that measure different constructs from different populations (hypothetical population), but there exists a common measure among all examinees. SAT-subject test scores are scaled using the SAT-V and SAT-M as anchor measures; enabling us to treat the subject test scores as having comparable scales. With an anchor, other measures could be placed on the same scale using a linking function (linear or equipercentile).
Scaling: Similar Constructs & Reliability; Different Difficulty & Population This case typically involves tests of the same subject that are administered to different grades or ages of individuals – often refer to this as vertical scaling. The tests change in difficulty (relatively) across different populations (grades). Typically, this scaling is done through anchor scaling, where adjacent grades have common items..
Same Construct, Different Reliability; Same Population In this case, different reliabilities typically result from test of different length. The classic example is referred to as calibration, where the scores of a short form of a test are put on the scale of the full form.
Similar Constructs, Difficulty, & Reliability; Same Population Tests are measuring similar constructs, but each one is built to different specifications. Concordance represents an attempt to place scores from similar tests on the same scale. Many colleges accept both the ACT and SAT. A concordance table links the scores on one test to the other. The revised GRE may result in a concordance table to associate new scores with old scores.
Linking Method 3: Equating A direct link is created between a score on one test and a score on a different test, creating scores that are interchangeable. Tests must measure the same construct with the same difficulty and the same accuracy. Equating is the strongest form of linking. Errors in equating have caused more problems for testing companies than flawed items.
What makes a Linking an Equating? Two or more tests and scoring rules, Scores on each test from one or more samples of examinees, Implicit or explicit population to which the linking will be applied, One or more methods of estimating the linking function; And the goal: create interchangeable scores.
Equating Requirements Tests measure the same construct Tests have equal reliability Equating function is symmetric Equity: it is a matter of indifference to the examinee which test is to be taken Equating function has the property of population invariance
Standards for Educational & Psychological Testing (1999) 4.10 A clear rationale and supporting evidence should be provided for any claim that scores earned on different forms of a test may be used interchangeably. In some cases, direct evidence of score equivalence may be provided. In other cases, evidence may come from a demonstration that the theoretical assumptions underlying procedures for establishing score comparability have been sufficiently satisfied.
Standards 4.11 When claims of form-to-form score equivalence are based on equating procedures, detailed technical information should be provided on the method by which equating functions or other linkages were established and on the accuracy of equating functions. 4.12 In equating studies that rely on the statistical equivalence of examinee groups receiving different forms, methods of assuring such equivalence should be described in detail.
Standards 4.13 In equating studies that employ an anchor test design, the characteristics of the anchor test and its similarity to the forms being equated should be presented, including both content specifications and empirically determined relationships among test scores. If anchor items are used… the representativeness and psychometric characteristics of anchor items should be presented.
Standards 4.14 When score conversions or comparisons procedures are used to relate scores on tests or test forms that not closely parallel, the construction, intended interpretation, and limitations of those conversions or comparisons should be clearly described.
Standards 4.15 When additional test forms are created by taking a subset of the items in an existing test form or by rearranging its items and there is sound reason to believe that scores on these forms may be influenced by item context effects, evidence should be provided that there is no undue distortion of norms for the different versions or of score linkage between them.
Test Equating, Scaling, and Linking: Methods and PracticesM.J. Kolen & R.L. Brennan (2004)
General Issues Equating is a statistical process that is used to adjust scores on test forms so that scores on the forms can be used interchangeably. Equating adjusts for differences in difficulty, not in content, so that scores can be used interchangeably.
General Issues Raw scores are typically converted to a scale score; raw scores on a subsequent administration are equated to raw scores on an old form, then converted to scale scores using the raw-to-scale score transformation. Equating can potentially improve score reporting and interpretation for different forms (examinees) that are evaluated at the same time or over time.
Equating Implementation Decide on purpose for equating Construct alternate forms (same specifications) Choose a data collection design Implement data collection Choose an operational definition of equating (the type of relation between forms) Choose statistical estimation method(s) Evaluate the equating results
Equating Properties: Symmetry • The Equating transformation must be symmetric • The X to Y transformation function is the inverse of the Y to X transformation function This relation can be assessed by conducting the equating in both directions, plotting the equating relations, and find the plots to be the same.
Symmetry • Same test specifications • Content • Statistical properties This is necessary if the scores on different forms are to be considered interchangeable.
Equating Properties: Equity • A matter of examinee indifference • Examinees with a given true score have the same distribution of converted scores
Equity is the true score X is a score on the new form X, Y is a score on the old form Y G is the cumulative distribution function of scores on form Y eqY is the equating function to covert X to the Y scale G* is the cum dist of eqY for the same population G*[eqY(x)| ] = G(y| ), for all
Equity Examinees with a given true score () will have the same observed score means, standard deviations, and distribution shape; SEM will be the same for a given true score. Technically, Lord’s equity property holds only if the two forms are identical – eliminating the need for equating.
Equity Morris (1982) introduced a less restrictive equity property – First Order Equity Examinees with a given true score have the same mean converted score on the two forms. E[eqY(X)| ] = E(Y| ) for all
Observed Score Properties • Equipercentile Equating • The cumulative distribution of equated scores on Form X is equal to the cumulative distribution of scores on Form Y G*[eqY(x)] = G(y) • Mean Equating • Converted scores have the same mean • Linear Equating • Converted scores have the same mean and SD
Population Invariance Equating relation is the same regardless of the sample used in the equating Methods based on observed score properties are not strictly group invariant; mediated by the degree to which alternate forms are carefully constructed.
Equating Designs: Random Groups Spiraling randomly assigns forms to examinees; large sample sizes are needed Leads to randomly equivalent groups
Single Group Counterbalancing • Each examinee takes both forms, half in the opposite order than the others. • Smaller sample size required • Requires twice the administration time • Differential order effects can still be problematic, leading to discarding the second form and unstable equating
Common Item Nonequivalent Group • Different groups are administered different forms with a common item set • Only one form can be administered at a time • Common items may (internal) or may not (external) contribute to the total score • Common item set should represent the total test • Common items should be located in the same position on each form
Random Groups • Test Administration Complications • Moderate; more than one form needs to be spiraled • Test Development Complications • None out of the ordinary • Statistical Assumptions • Minimal; random assignment to forms is effective
Single Group – Counterbalancing • Test Administration Complications • Major; each examinee must take two forms and order must be counterbalanced • Test Development Complications • None out of the ordinary • Statistical Assumptions • Moderate; order effects cancel out and random assignment is effective
Common-Item Nonequivalent Groups • Test Administration Complications • None; forms can be administered in typical manner • Test Development Complications • Representative common-item sets need to designed • Statistical Assumptions • Stringent; common items measure same construct in both groups, groups are similar, other required statistical assumptions hold NEAT: Non-Equivalent groups with Anchor Test
Common-Item to an IRT Calibrated Pool • Test Administration Complications • None; forms can be administered in typical manner • Test Development Complications • Representative common-item sets need to designed • Statistical Assumptions • Stringent; same as the common-item nonequivalent group design AND the IRT model assumptions must hold
Observed Score Equating Method 1: Mean Equating • Form X differs in difficulty from Form Y by a constant along the score scale. • Deviation scores are set to be equal: x - (X) = y - (Y) or mY(x) = y = x - (X) + (Y) mY(x) indicates a score x on Form X transformed to the scale of Form Y using mean equating.
Mean Equating Properties mY(x) = y = x - (x) + (y) E[mY(X)] = (Y) [mY(X)] = (X)
Mean Equating Example Mean on Form X = 72 Mean on Form Y = 77 mY(x) = y = x - (x) + (y) mY(x) = x - 72 + 77 = x + 5
Observed Score Equating Method 2: Linear Equating Allows for the differences in difficulty between the two forms to vary along the score scale. Standardized deviation scores are set equal. zX = zY
Linear Equating With terms rearranged: A linear equations of the form slope + intercept Slope = and Intercept =
Linear Equating Example SD(X) = 10 and SD(Y) = 9 Slope = 9/10 = .9 Intercept = 77 – .9(72) = 12.2 lY(x) = .9(x) + 12.2