Challenges and Solutions in Prototype Demonstration and Classification Approaches
This document delves into the challenges faced during the demonstration of a new prototype and explores effective classification strategies. It highlights the importance of clear expectation management from the beginning and discusses a hybrid approach to classification using multiple schemes. The report addresses issues in text extraction, stemming, and fuzzy search algorithms, focusing on how they can enhance search capabilities and improve the user experience. Solutions explored include using different classification systems and refining search techniques for optimal results.


Challenges and Solutions in Prototype Demonstration and Classification Approaches
E N D
Presentation Transcript
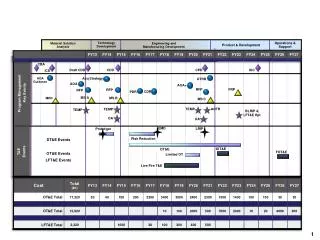
Some challenges (and some solutions…) • Classification – self selection vs. categorisation • Solution, for now, is a combination of approaches (more in a second) • Expectation Management • Might have been handled better from the outset: making our expectations clear is probably important • ‘Prototype’ status has its issues • Relating themes to specific events/projects • Have begun incorporating events & projects into the system, using the same sort of vocabulary as that used for themes & researchers
Classification – the solution (?) Mixture of controlled classification schemes: RCUK research classification scheme Cross-disciplinary Hierarchical Tied to funding - Relational MySQL version of the scheme created, and shared on the blog
Classification – the solution (?) Some of the other classification schemes we considered include: The University’s own College/School structure Lacked granularity. Recently re-structured... Eurostat’s Classifications metadata Focus on economic activity The EU’s Nomenclature for the analysis and Comparison of Scientific Programmes and Budgets (NABS) classification Largely science-based The Universal Decimal Classification Summary (udcS) Probably closest to our needs Perhaps lacked familiar nomenclature
Classification – the solution (?) ESRC National Centre for Research Methods Degree of top-down approval (Research Council) Provides an implicit hierarchy None of the potential schemes we found to be exhaustive Social Sciences focus of the NCRM scheme actually includes a pretty comprehensive list of qualitative and quantitative methods
Some technical points • Text extraction (from PDF) was less trivial than expected • Decoding streams, dealing with odd characters, etc. • Authentication was somewhat problematic • More of an institutional hurdle than a technical challenge • Search and comparison algorithms have been improved by incorporation of stemming and fuzzy search
Stemming • Using a version of the Porter stemming algorithm • Used to suggest keywords from publications and project descriptions • Much more useful (in my opinion!) when used to conflate search results • Can optionally allow for stemming in search engine
Fuzzy Search • Experimented with an implementation of Jaro–Winkler distance • Also tried PHP’s built-in similar_textfunction • Finally settled on Levenshtein distance • Wrapped up the native PHP function with some additional parameters for acceptable distances • Fuzzy search is another option in the search engine • But quite useful as another conflation tool behind the scenes