Vector Space Model for Information Retrieval Course
E N D
Presentation Transcript
Vector Space Model Computational Linguistic Course Instructor: Professor Cercone Presenter: Razieh Niazi
Outline • Typical IR System Architecture • Document and Query Processing in IR • IR Evaluation • Vector Space Model (VSM) • Similarity Measure • Term Weighing • Example • Improving the Vector Space Model • Latent Semantic Analysis
What’s Information Retrieval (IR)? • The goal of IR research is to develop models and algorithms for retrieving information from document repositories • What is the difference between data search and information retrieval ? • Most of the information needs and content are expressed in natural language • – Library and document management systems • – Web (Search Engines)
Typical IR system architecture Source: https://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/nlp09.pdf
What do you Think? Is IR “Easy”? • Try “ACL 2010” with Google and you will get the conference page on the top of list. • IR is perceived as easy because[1]: • Queries can be specific and match the words in a document. • The user is usually happy with the top few relevant results (hard or no need to get the complete results).
IR is Hard !!! • Documents and queries are expressed in natural Language • Document repositories are unstructured • Highly ambiguity in Natural Language • Vague semantics of documents • Ambiguity: word sense, structural, etc. • Incomplete: requiring inferences.
Steps in Document and Query Processing • stop-word removal • rare word removal (optional) • Stemming • optional query expansion • document indexing • document and query representation; e.g. vectors
Stop Words Source: [2]
Ad hoc text retrieval • The classical problem in IR is the ad-hoc retrieval problem. • Ad hoc text retrieval: • Given a collection of textual documents (information items) • Given a query from a user (information need) • Retrieve relevant documents from the collection • Applications: library search, search engines, digital libraries, search for medical records and law legal cases. Source: This slide is borrowed from [1]
There are two main models in retrieving the information: • Exact match • Best match
Exact Match • Return documents that precisely satisfy some structured query expression, of which the best known type is Boolean queries . • Example: • Car AND Insurance OR (cost OR price) • (laser NEAR printer) AND (color OR (plain NEAR paper)) AND NOT (HP OR Hewlett-Packard) Source: https://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/03vectorspaceimplementation-6per.pdf
Pros: • Can use very restrictive search • Makes experienced users happy • Cons: • Complex query language, confusing to end users • For large and heterogeneous document collections, the result sets are either empty or huge and unwieldy • Exact-match only, no partial matches • Retrieved documents not ranked
Best Match • so most recent work has concentrated on systems which rank documents according to their estimated relevance to the query. • Given a query of t terms, • find a measure of relevance between the documents and the query. • Rank documents based on this measure.
Formalizing IR Tasks • Vocabulary: V = {w1,w2, …, wT} of a language • Query: q = q1, q2, …, qm where qi ∈V. • Document: di= di1, di2, …, dimi where dij∈V. • Collection: C = {d1, d2, …, dN} • Relevant document set: R(q) ⊆C:Generally unknown and user-dependent • Query provides a “hint” on which documents should be in R(q) • IR: find the approximate relevant document set R’(q) Source: This slide is borrowed from [1]
Evaluation measures • The quality of many retrieval systems depends on how well they manage to rank relevant documents. • How can we evaluate rankings in IR? • IR researchers have developed evaluation measures specifically designed to evaluate rankings. • Most of these measures combine precision and recall in a way that takes account of the ranking.
Precision & Recall Source: This slide is borrowed from [1]
In other words: • Precision is the percentage of relevant items in the returned set • Recall is the percentage of all relevant documents in the collection that is in the returned set.
Evaluating Retrieval Performance Source: This slide is borrowed from [1]
Cutoff Measure • All three retrieved sets have the same number of relevant and not relevant • documents. (A simple measure of precision (50% correct) would not • distinguish between them). • One measure used is precision at a particular cutoff, for example 5 • or 10 documents Source:[2]
Precision/Recall Tradeoff • There is an obvious trade-off between precision and recall. • If the whole collection is retrieved: • Recall is 100%, but low precision • If only a few documents are retrieved, then the most relevant documents will be returned • High precision, Low recall • In a good IR-system , precision decreases as recall increases and vice versa
How can we balance out precision and recall? • The two most popular ways: • Average precision is one way of computing a measure that captures both precision and recall. • Another way is the F measure, where P is the precision, R is the recall and determines the weighting of precision and recall. • The F measure can be used for evaluation at fixed cutoffs if both recall and precision are important.
Composite Measures • A composite precision-recall curve showing 11 points can be graphed. Source: This slide is borrowed from [1]
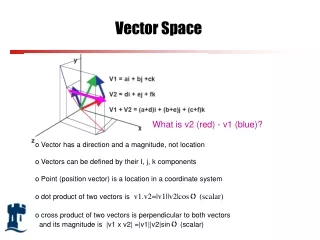
Vector Space Model (VSM) • The vector space model is one of the most widely used models for ad-hoc retrieval • used in information filtering, information retrieval, indexing and relevancy rankings. • Documents and queries are represented as vectors of weights: • Each dimension of the space corresponds to a separate term in the document collection
Document d2 has the smallest angle with q (closest vector to the query), so it will be the top-ranked document in response to the query car insurance. Source: [2]
What is the similarity measure in VSM? • To do retrieval in VCM, documents are ranked according to similarity with the query • Similarity is measured by the cosine measure or normalized correlation coefficient. Source: https://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/07models-vsm.pdf
Documents ranked by increasing cosine value • cosine (90) = 0 (completely unrelated) cosine (0) = 1 (completely related) • Cosine is a normalized dot product
Term Weighing • The success or failure of the vector space method is based on term weighting. • What is the Term Weight? • Terms: words, phrases, or any other indexing units used to identify the contents of a text. How? • if a term t appears often in a document, then a query containing t should retrieve that document
Term Weighting • Different terms have different importance in a text • A term weighting scheme plays an important role for the similarity measure. • Higher weight = greater impact on cosine • We now turn to the question of how to weight words in the vector space model.
How to weight words? • There are three components in a weighting scheme: • gi: the global weight of the ith term, • tij: is the local weight of the ith term in the jth document, • dj:the normalization factor for the jth document
Local Term -Weighting • Specifies frequency of a term within the document Source: https://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/polettini_information_retrieval.pdf
Global Term-Weighting • They are based on the dispersion of a particular term throughout the documents https://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/polettini_information_retrieval.pdf
Normalization • The normalization factor is used to correct variances in document lengths. • So, documents are retrieved independent of their lengths. • If we do not, short documents may not be recognized as relevant. Why?
Two main reasons that necessitate the use of normalization in term weights: • Higher term frequencies: • long documents usually use the same terms repeatedly • the term frequency factors may be large for long documents. • Number of terms: • long documents also have different numerous terms. • This increases the number of matches between a query and a long document
https://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/polettini_information_retrieval.pdfhttps://wiki.cse.yorku.ca/course_archive/2010-11/F/6390/_media/polettini_information_retrieval.pdf
How to weight words in the vector space • Term weighting:
Example Source: http://www.miislita.com/term-vector/term-vector-3.html
Vector Space Example • This is a basic example with a basic term vector model in which we: • do not take into account WHERE the terms occur in documents. • use all terms, including very common terms and stopwords. • do not reduce terms to root terms (stemming). • use raw frequecies for terms and queries (unnormalized data). • Based on Salton's Vector Space Model incorporates local and global information The following example is provided by Professors David Grossman and Ophir Frieder, from the Illinois Institute of Technology. Source: http://www.miislita.com/term-vector/term-vector-3.html
Suppose we have 3 documents (D=3): • Suppose we query an IR system for the query "gold silver truck". • Extract terms and calculate term weights for each term in documents and query • Calculate the similarity values • Rank the documents according to the similarity values Source: http://www.miislita.com/term-vector/term-vector-3.html
Extract terms and calculate term weights Source: http://www.miislita.com/term-vector/term-vector-3.html
Calculate the similarity values • First for each document and query, we compute all vector lengths (zero terms ignored) Source: http://www.miislita.com/term-vector/term-vector-3.html
Next, we compute all dot products (zero products ignored) Source: http://www.miislita.com/term-vector/term-vector-3.html
Now we calculate the similarity values: Source: http://www.miislita.com/term-vector/term-vector-3.html
Finally we sort and rank the documents in descending order according to the similarity values Source: http://www.miislita.com/term-vector/term-vector-3.html
VSM Advantage & Disadvantage • Advantage: • Ranked retrieval • Terms are weighted by importance • Partial matches • Disadvantage: • Assumes terms are independent • Weighting is intuitive, but not very formal
Improving the VSM Model • We can improve the model by: • Reducing the number of dimensions • eliminating all stop words and very common terms • stemming terms to their roots • Latent Semantic Analysis • not retrieving documents below a defined cosine threshold • normalized frequency of a term i in document j is given by[1]: • Normalized Document Frequencies • Normalized Query Frequencies
Latent Semantic Indexing (LSI) [3] • Reduces the dimensions of the term-document space • Attempts to solve the synonomy and polysemy • Uses Singular Value Decomposition (SVD) • identifies patterns in the relationships between the terms and concepts contained in an unstructured collection of text • Based on the principle that words that are used in the same contexts tend to have similar meanings.
LSI Process • In general, the process involves: • constructing a weighted term-document matrix • performing a Singular Value Decomposition on the matrix • using the matrix to identify the concepts contained in the text • LSI statistically analyses the patterns of word usage across the entire document collection
It computes the term and document vector spaces by transforming the single term-frequency matrix, A, into three other matrices: • a term-concept vector matrix, T, • a singular values matrix, S, • a concept-document vector matrix, D, which satisfy the following relations: • A = TSDT • The reason SVD is useful: • it finds a reduced dimensional representation of our matrix that emphasizes the strongest relationships and throws away the noise.
What is noise in a document [3]? • Authors have a wide choice of words available when they write • So, the concepts can be obscured due to different word choices from different authors. • This essentially random choice of words introduces noise into the word-concept relationship. Latent Semantic Analysis filters • out some of this noise and also attempts to find the smallest set of concepts that spans all the documents