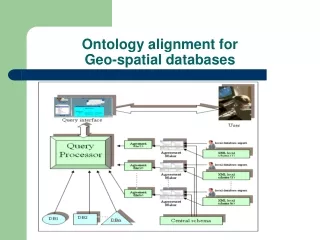
Ontology Alignment
300 likes | 480 Vues
Ontology Alignment. Problem Statement. Given N Ontologies (O 1 ,…, O n ) In a Particular Domain Different Level of Coverage Goal Evaluate Commonality of Entities Rank Entities. Challenges & Solutions. Ontology Alignments Largest Common Subgraph (LCS) Vector Space Model (TF/ IDF)

Ontology Alignment
E N D
Presentation Transcript
Problem Statement • Given N Ontologies (O1 ,…, On) • In a Particular Domain • Different Level of Coverage • Goal • Evaluate Commonality of Entities • Rank Entities
Challenges & Solutions • Ontology Alignments • Largest Common Subgraph (LCS) • Vector Space Model (TF/ IDF) • Accuracy of Entities in Aligned Concepts • Ranking Entities
LCS Algorithm for Multiple Ontologies • Find the LCS for two Ontologies • Align LCS with other Ontologies
Largest Common Subgraph (LCS) Algorithm between two Ontologies S1: Semantic Similarity • Node Similarity (NS) • Background Knowledge (i.e., WordNet/Wikipedia) • Structural Similarity (SS) • Neighbor Similarity • Properties Similarity • Instance-based Similarity (IS) S2: Total Similarity = NS + SS + IS
Data Structure for LCS Algorithm C’2 C5 C2 C’3 C1 C4 C’6 C’1 C3 C6 C’4 C7 C’5 • Similarity Measure for Corresponding Entities • Node Similarity + Structural Similarity
Node Similarity: Instance-based Representing types using N-grams* • Node Similarity (Name-Match) • Find Common N-gram (N = 2) for corresponding columns CA CB N-gram types from A.StrName = {LO, OC, CU,ST,…..} N-gram types from B.Street = {TR, RA, R4, 5/,…..} *Jeffrey Partyka, Neda Alipanah, Latifur Khan, Bhavani Thuraisingham & Shashi Shekhar, “Content Based Ontology Matching for GIS Datasets“, ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS 2008), Page: 407-410, Irvine, California, USA, November 2008.
Node Similarity: Instance-basedVisualizing Entropy and Conditional Entropy H(C) = –Σpi log pi for all x є C1 U C2 H(C | T) = H (C,T) – H(C) for all x є C1 U C2 and t є T
Node Similarity: Faults of this Method • Semantically similar columns are not guaranteed to have a high similarity score A є O1 B є O2 2-grams extracted from A: {Da, al, la, as, Ho, ou, us…} 2-grams extracted from B: {Sh, ha, an, ng, gh, ha, ai, Be, ei, ij…}
Node Similarity: Instance-based K-medoid + NGD instance similarity Step1: Extract distinct keywords from compared columns C1 C2 C1 є O1 C2 є O2 Keywords extracted from columns = {Johnson, Rd., School, 15th,…} Step2: Group distinct keywords together into semantic clusters : Column 1 “Rd.”,”Dr.”,”St.”,”Pwy”,… “Johnson”,”School”,”Dr.”…. : Column 2 C1UC2 Step3: Calculate Similarity Similarity = H(C|T) / H(C)
Node Similarity: Instance-based Problems with K-medoid + NGD* It is possible that two different geographic entities (ie: Dallas, TX and Dallas County) in the same location will have a very low computed NGD value, and thus, be mistaken for being similar: similarity = .797 *Jeffrey Partyka, Latifur Khan, Bhavani Thuraisingham, “Semantic Schema Matching Without Shared Instances,” to appear in Third IEEE International Conference on Semantic Computing, Berkeley, CA, USA - September 14-16, 2009.
NodeSimilarity: Instance-based Using geographic type information* We use a gazetteer to determine the geographic type of an instance: O1 Geotypes O2 *Jeffrey Partyka, Latifur Khan, Bhavani Thuraisingham, “Geographically-Typed Semantic Schema Matching,” to appear in ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS 2009), Seattle, Washington, USA, November 2009.
Node Similarity: Instance-based Results of Geographic Matching Over 2 Separate Road Network Data Sources
Structural Similarity • Structural Similarity Measurement • Neighbor Similarity C5 C’3 C2 C’1 C1 C3 C6 C’4 C’5
Structural Similarity Structural Similarity Measurement • Properties Similarity C5 C’2 hasDrink C2 isA subClass C’3 hasFood hasColor isA C1 C4 isA hasFlavor C’6 C’1 hasTopping subClass hasFlavor C3 C6 subclass hasFlavor C7 C’4 isA C’5 RTC1 = [3isA, 2subClass,1hasFlavor,1hasColor, 0 hasFood,1 hasTopping] RTC2 = [1isA, 1subClass,2hasFlavor,0hasColor,1hasFood]
SimilarityResults of Pairwise Ontology Matching(I3CON Benchmark) Matching using Name Similarity + (RTS and Neighbor) Matching using Name Similarity + RTS
Ontology MatchingVector Space Model (VSM) • Define the VSM for Each Entity • Collection of Words in label, edge types, comment and neighbors. C’2 hasDrink C5 C2 isA subClass C’3 hasFood isA hasColor C1 C4 C’6 C’1 isA hasFlavor isA hasFlavor subClass subclass C3 C6 hasFlavor C’4 hasTopping C7 C’5 VSM(C1)= [1C1,1C2,1C3,1C5,1C6,1isA, 2subClass,1hasFlavor] VSM(C’1)= [1C’3, C’4,1C’5, 1isA, 2hasFlavor]
Ontology MatchingVector Space Model (VSM) • Update VSM by Word Score Using TF/IDF • Calculate Cosine Similarity for corresponding entities • Cos(VSM(C1) , VSM(C2) )
Aligned Concepts • Aggregate different ontologies • Example
Aligned Concepts • Statistical Model
Aligned Concepts • Calculate the probabilities of appearance of each entity in GO • Use Maximum likelihood Estimation • Calculate and
Reification • Reification can be considered as a metadata about RDF/OWL statements. • Ontology Alignment approaches rely on probabilistic measures to find matches between concepts in different ontologies. • Reification data can be attached with the alignment information to show the 'match factor' between two concepts in OWL-2. • Advanced analytic algorithms can benefit from reification in establishing the relevance of search results.
OWL - 2 • OWL – 2 is an extension to OWL. Some of the new features in OWL 2 are as follows - • Syntactic sugar (eg. Disjoint union of classes) • Property chains • Richer datatypes, data ranges • Qualified cardinality restrictions • new constructs that increase expressivity • simple metamodeling capabilities • extended annotation capabilities • Following link lists all the new features in OWL 2http://www.w3.org/TR/2009/REC-owl2-new-features-20091027/
Problem Statement • Our solution for ontology construction of documents • Use hierarchical clustering algorithm to build a hierarchy for documents • Hierarchical Agglomerative Clustering (HAC) • Modified Self-Organizing Tree (MSOT) • Hierarchical Growing Self-Organizing Tree (HGSOT) • Assign concept for each node in the hierarchy • Usage of the WordNet
Concept Assignment • Concept Assignment to document • LVQ1: topic vector (t) is built by training with the training documents. • Clusters in LVQ are predefined. Each topic cluster is represented by a node in the output map, and the LVQ use pre-labeled data for training. • Only the best match node’s vector (winning vector) will be updated, rather than its neighbors. Vector updating rule will use following equations: If data x and best match node c belong to the same class, If data x and best match node c belong to the different class.
Concept Assignment • Concept sense disambiguation • One keyword associated with more than one concept in WordNet. • Keyword “gold” has 4 senses in WordNet and keyword “copper” has five senses in WordNet. • For disambiguation of concepts we apply the same technique (i.e., cosine similarity measure) used in topic tracking. • To construct a vector for each sense we will use a short description that appears in WordNet.
Concept Assignment • Concept assignment for leaf node • If there are majority documents have the same concept we assign the concept to the leaf. • If there is not majority we will choose a generic concept of all concept from WordNet to the leaf. • Concept assignment for non leaf node • If there are majority children have the same concept we assign the concept to the internal node. • If there is not majority we will choose a generic concept of all concept from WordNet to the internal node.