Enhancing Hash Join Performance with Intrinsic Data Skew Exploitation
470 likes | 571 Vues
Improve database query performance by leveraging skew data to optimize hash joins, presented with Histojoin algorithm and experimental results in Java and PostgreSQL.

Enhancing Hash Join Performance with Intrinsic Data Skew Exploitation
E N D
Presentation Transcript
Improving Hash JoinPerformance By ExploitingIntrinsic Data Skew by Bryce Cutt supervised by Dr. Ramon Lawrence
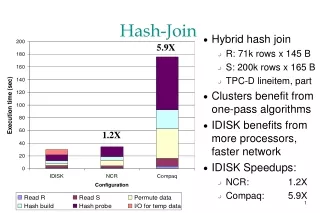
Introduction • Databases are part of our lives • Hash Join is a core database algorithm • Very I/O intensive for large databases • Queries may take hours • Any performance improvement is significant • Real datasets contain skew • Skew is when some values occur more frequently • Skew can greatly reduce hash join performance • Skew traditionally considered a bad thing for join algorithms • Try to mitigate negative effects of skew • Adapt hash join • No longer just mitigate • Use foreknowledge of skew • Improve performance
Example Relations Probe Relation Build Relation Part Purchase
DHJ Algorithm Build Phase Hash Function: modulo 5
Statistics and Hash Joins • Modern database systems maintain statistics such as histograms for query optimization • What if hash join could use the statistics to choose the best build tuples to keep in memory? • Does not have to generate own statistics
Histojoin Algorithm General Idea • Same basic form as DHJ • Determines best build tuples from histogram • In this case the tuples with partid 2 and 3 • Create partitions for the best build tuples • In addition to regular partitions • Freeze regular partitions first • Perform a highly optimized multi-stage check • To determine the partition tuples belong in
Implementation Details • Avoided in algorithm description • General enough to fit any database system • But ultimately important • Core of algorithm implementation specific • Implemented in • Stand alone Java app • Optimistic implementation • PostgreSQL • HHJ • Conservative implementation
Inaccurate Statistics • Selections • Multi-join plans • Sampling • SITs • Handling dependent on implementation • PostgreSQL conservative memory usage
Experimental Results • TPC-H • Database commonly used to test database system performance • Skewed versions • 1GB dataset used in Java tests • 10GB dataset used in PostgreSQL tests
Experimental Results, cont. Java, Lineitem/Part, skewed, 1GB Approx. 20% faster
Experimental Results, cont. Java, Lineitem/Part,high skew, 1GB Approx. 60% faster
Experimental Results, cont. Java, Various Joins, Percent Improvement, 1GB Approx. 20% for skewed and 60% for high skew
Experimental Results, cont. Java, Lineitem/Part, Inaccurate Histogram, 1GB
Experimental Results, cont. Java, Lineitem/Part/Supplier,high skew, 1GB Approx. 75% faster
Experimental Results, cont. PostgreSQL, Lineitem/Part,skewed, 10GB Approx. 10% faster
Experimental Results, cont. PostgreSQL, Lineitem/Part, high skew, 10GB Approx. 60% faster
Experimental Results, cont. PostgreSQL, Various Joins, Percent Improvement, 10GB 5-10% for skewed and 50-60% for high skew
Conclusion • Histojoin • significantly outperforms standard hash joins in the presence of skew • Smart implementation mitigates pitfalls • Two papers have been published from this work • PostgreSQL patch currently in review • Will be used by millions of users
Thank you Thank you Dr. Lawrence