1. 순차검색 (Sequential Search, Linear Search) - 첫번째 또는 마지막 레코드를 시작으로 특정 레코드의 탐색 작업이 순차적으로 처리
2.6 탐색 (Search). 1. 순차검색 (Sequential Search, Linear Search) - 첫번째 또는 마지막 레코드를 시작으로 특정 레코드의 탐색 작업이 순차적으로 처리 - 프로그램 작성이 쉽고 , 정렬되지 않은 레코드 검색이 가능 - 파일이 크면 탐색 시간 증가 - 평균비교횟수 : (n+1)/2 평균검색시간 : O(n) 2. 이진검색 (Binary Search)

1. 순차검색 (Sequential Search, Linear Search) - 첫번째 또는 마지막 레코드를 시작으로 특정 레코드의 탐색 작업이 순차적으로 처리
E N D
Presentation Transcript
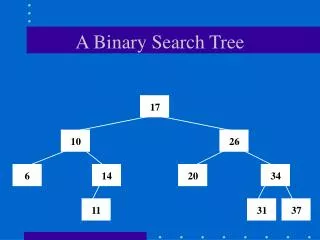
2.6 탐색(Search) 1. 순차검색 (Sequential Search, Linear Search) - 첫번째 또는 마지막 레코드를 시작으로 특정 레코드의 탐색 작업이 순차적으로 처리 - 프로그램 작성이 쉽고, 정렬되지 않은 레코드 검색이 가능 - 파일이 크면 탐색 시간 증가 - 평균비교횟수 : (n+1)/2 평균검색시간 : O(n) 2. 이진검색 (Binary Search) - 상한 값(F)과 하한 값(L)을 설정하고 그 중간 값(M)을 구한 후 키와 중간 값을 계속 비교 하면서 검색 (순차적으로 정렬되어 있는 파일에서만 수행 가능) - 파일의 탐색 대상을 ½씩 줄여가면서 탐색하므로 효율적 - 레코드 수가 많을 수록 효과적 (최악의 경우라도 비교횟수는 평균횟수보다 한 번 더 많다.) - 평균검색시간 : O(log2n)
1 2 3 4 5 6 7 8 9 10 12 23 28 42 55 61 73 87 95 100 1 2 3 4 5 6 7 8 9 10 상한값 F key 중간값 M 하한값 L 12 23 28 42 55 61 73 87 95 100 1 2 3 4 key 12 23 28 42 F M L 3 4 28 42 F,M L - 이진검색법의 예 key 28을 찾기 위한 알고리즘 중간 값 M = (상한값 F + 하한값 L) / 2 ① 중간 값 M (1+10)/2 = 5.5 ≒ 5 ② 중간 값 M (1+4)/2 = 2.5 ≒ 2 ③ 중간 값 M (3+4)/2 = 3.5 ≒ 3
3. 피보나치검색 (Fibonacci Search) - 피보나치 순열을 이용하여 서브 파일을 형성해 가면서 검색 (레코드가 반드시 정렬되어 있어야 한다.) - 이진검색은 나눗셈을 이용하나, 피보나치 검색은 덧셈과 뺄셈만으로 검색 가능 (속도 빠름) - 평균검색시간 : O(log2n) - 알고리즘 Fk-1를 인덱스로 하여 인덱스가 가진 값과 K를 비교 ① K < KFk-1 일 경우 : 인덱스 1부터 Fk-1–1까지의 서브 파일을 재귀적으로 탐색 ② K=KFk-1 이면 탐색 성공 ③ K > KFk-1 일 경우 : 인덱스 Fk-1 +1부터 Fk-1 -1까지의 서브파일을 재귀적으로 탐색 재귀적으로 탐색할 인덱스 범위가 결정되면 ①의 경우 다음 탐색될 레코드의 인덱스는 Fk-2 이며 ③의 경우 탐색될 레코드의 인덱스는 Fk-1 + Fk-3 이 된다.
Fk-3 Fk-2 Fk-1 인덱스 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 2 3 6 7 8 12 15 18 20 23 24 27 33 41 45 49 55 66 75 89 K - 피보나치 검색의 예) 피보나치 수는 0,1,1,2,3,5,8,13,21,…이 되고, 입력파일은 20개의 값을 가지므로 Fk =21 ⅰ) Fk-1=13이므로 인덱스 13의 값 33과 비교. K=15, KFk-1=33 이므로 K < KFk-1 탐색 레코드는 인덱스1~인덱스12 사이에 위치 ⅱ) Fk-2=8이므로 인덱스 8의 값 18과 비교. K=15, KFk-2=18 이므로 K < KFk-2 탐색 레코드는 인덱스1~인덱스7 사이에 위치 ⅲ) Fk-3=5이므로 인덱스 5의 값 8과 비교. K=15, KFk-3=5 이므로 K > KFk-3 탐색 레코드는 인덱스6~인덱스7 사이에 위치 ⅳ) Fk-1 + Fk-3 = 5 + 2 = 7이므로 인덱스 7의 값 15와 비교. K = K(Fk-1+Fk-3)
X : 특정 키 A(max), A(min) : 키의 최대값과 최소값 n : 레코드의 총수 X – A(min) i = * n A(max) – A(min) 1 2 3 4 5 6 7 8 9 10 11 20 25 35 43 48 56 60 69 72 75 78 4. 보간검색 (Interpolation Search) - 탐색 대상이 있을 것으로 예상되어지는 위치를 선택하여 탐색 (레코드가 반드시 정렬되어 있어야 한다.) - 사전, 전화번호, 색인명 검색 - - 예) ⅰ) (56-20) / (78-20) * 11 = 6.82 ≠ 7 인덱스 7의 값 60과 비교 -> 찾는 레코드는 인덱스 1부터 6사이에 존재 ⅱ) (56-20) / (56-20) * 6 = 6 인덱스 6의 값 56과 비교 -> 탐색 성공
대표인덱스 2 7 11 14 인덱스 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 레코드 1 9 5 7 31 27 40 20 99 67 105 77 50 59 55 52 5. 블록검색 (Block Search) - 블록간에는 정렬되어 있어야 하나, 블록내에는 정렬되어 있을 필요 없음. - 인덱스 구성은 블록의 최대 값에 대한 주소로만 구성 - 예) ⅰ) 첫번째 인덱스 2가 갖는 값 9와 77비교 ⅱ) 두번째 인덱스 7이 갖는 값 40과 77비교 ⅲ)세번째 인덱스 11이 갖는 값 105와 77비교 -> 77은 세번째 블록에 있음 ⅳ)세번째 블록의 값들을 순차적으로 탐색
6. 해싱 (Hashing) - 해싱 함수를 이용하여 레코드가 저장되어 있는 주소를 직접 구하여 검색 (키를 비교하지 않고 계산에 의해 검색하는 방법) - 삽입과 삭제가 빈번한 자료에 적합 - 용어) 해싱표(hashing table) : 레코드 위치 저장을 위한 기억공간 테이블은 버켓으로 구성되고, 버켓은 여러 개의 슬롯으로 구성 버켓(bucket) : 해싱 주소법에 삽입 가능한 키의 개수 슬롯(slot) : 한 개의 레코드를 저장할 수 있는 공간 충돌(collision) : 두개 이상의 레코드가 동일한 버켓 주소를 갖는 경우 동거자(synonym) : 동일한 버켓 주소를 갖는 서로 다른 레코드의 집합 - 오버플로우 처리방법 개방주소지정(open addressing) 충돌발생시 해싱테이블에 비어 있는 다른 버켓을 찾아 주소 저장 (주소 재계산) 체인(chain) 기법 : 포인터를 이용하여 비어 있는 버켓을 지정 폐쇄주소지정(close addressing) 오버플로우 발생시 링크로 연결하여 해결
◆ 다시 한 번 1. 순차검색(Linear Search, Sequential Search) - 기억장소의 처음부터 차례대로 탐색하는 방법이다. - 가장 간단하나 속도가 느리다. - 자료가 정렬되어 있을 필요가 없다. 2. 이진검색(Binary Search) - 처음값과 마지막값에 대한 중간값을 계산한 후 키 값과 비교하여 검색한다. - 이미 자료가 정렬되어 있어야 한다. - 자료가 많을 수록 효과적이다. 3. 피보나치검색(Fibonacci Search) - 피보나치 순열을 이용해서 탐색한다. - 자료가 정렬되어 있어야 한다. - 덧셈과 뺄셈만으로 탐색이 가능하다. - 알고리즘 구현이 복잡하고, 초기에 피보나치 수열화되어 있어야 한다. 4. 보간검색(Interpolation Search) - 자료가 있을만한 위치의 키를 선택하여 탐색한다. (자료가 정렬되어 있어야 한다.) - 파일이나 키의 분포 상황에 따라 영향을 받는다. - 곱하기와 나누기 연산을 많이 하므로 자주 사용하지 않는다. 5. 블록검색(Block Search) - 파일을 몇 개의 블록으로 나누어 찾는 레코드가 어느 블록에 있는가 찾는 방법이다. - 어느 블록에 있는지 판단되었으면 그 블록내에서 선형검색한다. - 자료가 어느 정도 정렬되어 있을 경우 효과적이 방법이다.
기출 . 예상 문제 1. 다음 탐색(Search) 방법 중 가장 빠른 것은? ① Binary Search Tree ② Sequential Search ③ Block Search ④ Linear Search 2. 블록 탐색은 어느 경우에 특히 유용한가? ① 자료가 네 가지 범주에 정리되어 있지 않을 때 ② 출력량이 많을 때 ③ 알파벳 코드를 사용할 때 ④ 자료가 거의 올바른 순서로 정리되어 있을 때 3. 이진탐색(Binary Search)의 특징이 아닌것은? ① 작은 리스트에 적합하다. ② 전체 레코드를 찾는 시간은 증가한다. ③ 원하는 레코드를 신속히 찾을 수 있다. ④ 약간의 계산이 필요하다.
기출 . 예상 문제 4. 정렬되어 있지 않은 자료를 탐색하기 위하여 가장 효과적인 방법은? ① 순차탐색(Sequential Search) ② 2진탐색(Binary Search) ③ 확률탐색(Probabilistic Search) ④ 피보나치탐색(Fibonacci Search) 5. 정렬되어 있는 N개의 요소를 가진 파일에서 하나의 요소에서 순차적 탐색을 할 때 평균 search 길이는? ① {N(N+1)} / 2 ② (N+1) / 2 ③ (N+1) /2N ④ (2N+1) /2 6. 해싱(Hashing) 기법에 대한 설명으로 옳은 것은? ① 버킷(bucket)이란 한 개의 레코드를 저장할 수 있는 공간으로 N개의 버킷이 모여 슬롯을 이룬다. ② 충돌(collision)이란 두개 이상의 레코드가 동일한 버켓 주소를 갖는 경우를 말한다. ③ 동거자(synonym)란 서로 다른 버켓 주소를 갖는 레코드의 집합. ④ 개방주소법(open addressing)이란 오버플로 발생시 이를 별도의 기억공간에 두고 링크로 연결하여 사용하는 방법을 말한다.