Download
1 / 30
300 likes | 530 Vues
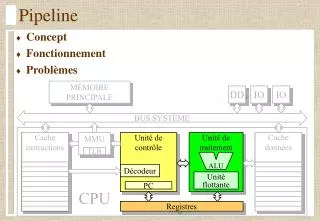
Pipeline. Concept Fonctionnement Problèmes. MÉMOIRE PRINCIPALE. DD. IO. IO. BUS SYSTÈME. Cache instructions. Cache données. MMU. Unité de contrôle. Unité de traitement. TLB. ALU. Décodeur. Unité flottante. PC. CPU. Registres. Mémoire. MDR. MAR. CK. PC. Séquenceur.

E N D
Pipeline • Concept • Fonctionnement • Problèmes MÉMOIRE PRINCIPALE DD IO IO BUS SYSTÈME Cache instructions Cache données MMU Unité de contrôle Unité de traitement TLB ALU Décodeur Unité flottante PC CPU Registres
Mémoire MDR MAR CK PC Séquenceur SLC IR Opcode Opérandes Opérandes RAM Contrôle CK Fanions Vue d'ensemble du processeur OUTPORT INPORT OEN 1 0 SEL I0 I1 AL2 AL1 AL0 Z Z≠0 SH2 SH1 SH0 SHIFTER 3 RA R0 R1 R2 R3 R4 R5 R6 R7 3 RB WEN 3 WA
Boucle de traitement Chargement (instruction) L'instruction est cherchée en mémoire et chargée dans le registre d'instruction (IR) Décodage L'instruction est décodée pour en extraire les signaux de contrôle pour l'unité de traitement Chargement (opérandes) Les opérandes demandés par l'instruction sont cherchés dans les registres ou en mémoire Exécution L'opération demandée est effectuée sur les opérandes choisis Rangement (opérandes) Le résultat de l'opération est stocké dans un registre ou en mémoire
Exécution - Timing L'exécution d'une instruction comporte donc au plus 5 phases: • le chargement de l'instruction (instruction fetch ou IF) • le décodage de l'instruction (instruction decode ou ID) • le chargement des opérandes (operand fetch ou OF) • l'exécution de l'instruction (execute ou EX) • le rangement des opérandes (operand commit ou OC) Toutes les phases d'exécution n'ont pas la même durée. CK INST 1 IF ID OF EX OC INST 2 IF ID OF EX OC INST 3 IF ID OF EX OC INST 4 IF ID OF EX OC La fréquence maximale de l'horloge est déterminée par l'instruction la plus lente (sans compter les cache miss).
Vue d'ensemble du processeur INPORT Adresse Adresse INPORT OUTPORT PC Séquenceur I0 Z IR SHIFTER Décodeur I1 REGISTRES Chargement (instruction) Décodage Chargement (opérandes) Exécution Rangement (opérandes)
Pipeline - Implémentation Les étages doivent être séparés par des registres (ou des latches). INPORT Adresse Adresse INPORT OUTPORT REGISTRES REGISTRES REGISTRES PC Séquenceur I0 Z IR SHIFTER Décodeur I1 REGISTRES Chargement (instruction) Décodage Chargement (opérandes) Exécution Rangement (opérandes)
Pipelining CK INST 1 IF ID OF EX OC INST 2 IF ID OF EX OC INST 3 IF ID OF EX OC INST 4 IF ID OF EX OC Pipelining: l'exécution de chaque instruction est divisée en étages. CK La fréquence maximale de l'horloge d'un pipeline est déterminée par l'étage le plus lent. INST 1 IF ID OF EX OC INST 2 IF ID OF EX OC INST 3 IF ID OF EX OC INST 4 IF ID OF EX OC
Timing - Définitions Latence (latency ou flow-through time) d'un pipeline: temps (en nombre de coups d'horloge) nécessaire pour produire le premier résultat. En pratique, la latence d'un pipeline correspond à sa profondeur, c'est-à-dire, au nombre d'étages. En pratique, pour la plupart des pipelines, la bande passante est d'une instruction par cycle d'horloge. Bande passante (throughput) d'un pipeline: nombre d'instructions par cycle d'horloge.
Timing - Temps d'exécution Si on ignore les cache miss, le temps d'exécution d'un programme sur un processeur sans pipeline est donné par: Texec = # instructions # cycles par instruction Tcycle Pour un processeur avec pipeline, le temps d'exécution devient: Texec = ((# instructions-1) (1 / Bande passante) + Latence) Tcycle Comme pour la plupart des processeurs avec pipeline la bande passante est d'une instruction par cycle d'horloge: Texec = ((# instructions-1) + Latence) Tcycle
Timing - Temps de cycle Le temps de cycle sur un processeur sans pipeline est donné par: C'est à dire, le temps d'exécution de l'instruction i la plus lente parmi toutes les instructions du jeu d'instructions du processeur. Pour un processeur avec pipeline, le temps de cycle devient: C'est-à-dire, le temps d'exécution de l'étage le plus lent parmi tous les étages des toutes les instructions i du jeu d'instructions. TIF TID TOF TEX TOC Total Instruction A 2ns 3ns 2ns 3ns 2ns 12ns Instruction B 2ns 4ns 2ns 1ns 2ns 11ns Instruction C 2ns 2ns 2ns 1ns 2ns 9ns
Remarques sur la performance Remarque 1: Certaines phases sont inutiles pour certaines instructions (p.ex. un LOAD ne nécessite pas d'exécution), mais toutes les instructions doivent traverser tout le pipeline. Ce "gaspillage" est nécessaire pour simplifier le contrôle. Remarque 2: Les pipelines sont normalement associés à des architectures load/store: la complexité des accès mémoire dans une architecture "standard" demande trop de matériel et de délai supplémentaire pour les étages de lecture et d'écriture des données.
Améliorations possibles Amélioration 1: Logiquement, un meilleur résultat pourrait être obtenu en augmentant le nombre d'étages: ils seront plus simples et la fréquence d'horloge pourra ainsi être plus élevée. La décomposition fine est toutefois très difficile. La plupart des processeurs sur le marché en ce moment ont des pipelines d'une profondeur de 5 à 7 étages, même si des pipelines de 14 étages existent (Pentium Pro). Amélioration 2: En général, la performance d'un pipeline est augmentée en accélérant l'étage le plus lent (souvent, le décodage). L'optimisation des parties les plus rapides (p.ex. l'ALU) est inutile.
Aléas d'un pipeline La présence d'un pipeline (et donc le partage de l'exécution d'une instruction en plusieurs étages) introduit des aléas: • aléas de structure: l'implémentation empêche une certaine combinaison d'opérations (lorsque des ressources sont partagées entre plusieurs étages) • aléas de données: le résultat d'une opération dépend de celui d'une opération précédente qui n'est pas encore terminée • aléas de contrôle: l'exécution d'un saut introduit un délai lorsque le saut est conditionnel et dépend donc du fanion généré par une opération précédente Les aléas de structure peuvent être éliminés en agissant sur l'architecture du processeur lors de sa conception. Par contre, les aléas de données et de contrôle ne peuvent pas être éliminés.
Aléas de données Deux instructions contiguës i et j peuvent présenter des aléas de données (dépendances entres les opérandes des deux instructions). En particulier, pour notre pipeline: • RAW (read-after-write): j essaie de lire un registre avant que i ne l'ait modifié i: move R1, R2 {R2R1} j: add R2, R3 {R3R2+R3} D'autres aléas sont possibles entre deux instructions (write-after-read, write-after-write), mais ils ne sont pas possibles dans un pipeline "standard". Chargement (instruction) Décodage Chargement (opérandes) Exécution Rangement (opérandes)
Aléas de données - Solution I Une solution relativement simple pour traiter les aléas de données est de retarder l'exécution des instructions concernées (pipeline stall) en les bloquant à l'étage de chargement des opérandes. CK INST 1 IF ID OF EX OC move r1,r2 INST 2 IF ID OF EX OC add r2,r3 INST 3 IF ID OF EX OC ... INST 4 IF ID OF EX OC ... Il faut toutefois remarquer que, les aléas de données (et surtout les RAW) étant relativement fréquents, le délai introduit par cette méthode est loin d'être négligeable.
Aléas de données - Solution II La fréquence élevée d'aléas de données peut justifier l'introduction de matériel supplémentaire. Notamment, la méthode appelée forwarding ou bypassing introduit une connexion directe entre la sortie de l'étage d'exécution et l'étage de chargement des opérandes, permettant au résultat d'une instruction d'être un opérande de l'instruction suivante. INPORT Adresse Adresse INPORT OUTPORT PC REGISTRES REGISTRES REGISTRES Séquenceur I0 Z IR SHIFTER Décodeur I1 REGISTRES Cette méthode est coûteuse en logique de contrôle supplémentaire.
Aléas de données - Solution III Une troisième solution peut être fournie par le compilateur, qui peut changer l'ordre d'exécution des instructions de façon à éliminer les aléas. Si nécessaire, les instructions intercalées peuvent être des NOP. add r3,r4,r1 add r3,r4,r1 add r1,r5,r6 sub r7,r8,r9 sub r7,r8,r9 nop ... add r1,r5,r6 Malheureusement, l'utilité de cette méthode est limitée: - le compilateur n'est pas toujours en mesure de détecter les aléas (par exemple, si les aléas concernent des pointeurs). - le nombre d'instructions à intercaler dépend de la structure (nombre d'étages) du pipeline; - la complexité du compilateur en est fortement augmentée.
Aléas de données - Load delay Comme pour toute opération d'écriture, le registre cible d'un LOAD n'est pas accessible pendant un certain nombre de cycles (le load delay ou delay slot) Ce nombre est variable et peut être très grand (cache miss). Il s'agit d'un cas particulier d'aléa de données. Le pipeline stall mentionné auparavant est une solution possible, mais la fréquence élevée d'instructions LOAD introduit un délai considérable dans l'exécution du programme. Une deuxième solution peut être fournie par le compilateur, qui peut "anticiper" le LOAD de façon à intercaler des instructions entre celui-ci et l'instruction qui lit le registre chargé. Si nécessaire, les instructions intercalées peuvent être des NOP. Toutefois, la taille du load delay et la structure des programmes empêchent une utilisation généralisée de cette technique pour le traitement des cache miss. En général, les cache miss sont traités indirectement: à moins qu'un seul programme ne soit en train de s'exécuter (un cas plutôt rare), le processeur arrête le programme pour le redémarrer à l’arrivée des données.
Aléas de contrôle La présence d'un pipeline introduit des complications lors de l'exécution d'un saut conditionnel: le fanion qui permet au séquenceur de déterminer si le saut est pris ou non n'est généré que lorsque l'instruction précédente arrive à l'étage d'exécution. L'étage de décodage de l'instruction n'est pas en mesure de calculer l'adresse de l'instruction suivante avant de connaître la valeur du fanion. INPORT Adresse Adresse INPORT OUTPORT PC REGISTRES REGISTRES REGISTRES Fanions Séquenceur I0 Z IR SHIFTER Décodeur I1 REGISTRES
Aléas de contrôle - Solution I Comme pour les aléas de données, une solution possible aux aléas de contrôle est de retarder l'exécution de l'instruction de saut (pipeline stall). Comme pour les aléas de données, cette opération introduit un délai qui est relativement important à cause du grand nombre d'instructions de saut dans un programme (les sauts conditionnels représentent environ 11-17% des instructions dans un programme). CK INST 1 IF ID OF EX OC cmp #0,r1 INST 2 IF ID OF EX OC beq adr INST 3 IF ID OF EX OC ... INST 4 IF ID OF EX OC ...
Aléas de contrôle - Solution II Une deuxième solution au problème des aléas de contrôle peut être fournie par le compilateur, qui peut "anticiper" l'instruction qui génère le fanion (comme auparavant pour le LOAD). Si le bon nombre (défini par l'architecture) d'instructions est intercalé entre la génération du fanion et le saut, celui-ci peut s'effectuer sans délai. Il faut toutefois remarquer que cette anticipation est souvent impossible et qu'elle est spécifique à une architecture donnée, pouvant générer des résultats erronés sur des architectures différentes. CK INST 1 IF ID OF EX OC cmp #0,r1 INST 2 IF ID OF EX OC ... INST 3 IF ID OF EX OC ... INST 4 IF ID OF EX OC beq adr
Aléas de contrôle - Solution III Une autre solution possible au problème des aléas de contrôle est l'exécution spéculative: le processeur peut essayer de "deviner" si le branchement sera pris ou pas pris (branch prediction) et commencer à exécuter les instructions correspondant à cette décision. Si le choix se révèle correct, la pénalité de branchement est éliminée. Si le choix se révèle incorrect, il faudra vider le pipeline et charger l'instruction correcte (avec la même pénalité d'un pipeline stall). Il y a deux types de prédiction de saut: • Statique: la direction du branchement est fixe, définie en matériel au moment de la conception du processeur; • Dynamique: la direction du branchement est définie au moment de l'exécution du programme, sur la base d'une analyse du code.
Prédiction statique Il y a deux choix immédiatement évidents pour la prédiction statique: • Prédit pris (predict taken) • Prédit non pris (predict not taken) Les sauts sont, en moyenne, pris environ 50% des fois. Les deux stratégies sont donc équivalentes par rapport au pourcentage de prédictions correctes. La deuxième stratégie (prédit non pris) est la plus courante (p.ex., dans la famille 486 de Intel). La raison est d'ordre pratique: dans cette stratégie, les instructions exécutées spéculativement sont les instructions qui suivent immédiatement l'instruction de saut et qui sont donc vraisemblablement déjà stockées dans le cache.
Prédiction statique CK INST 1 IF ID OF EX OC cmp #0,r1 INST 2 IF ID OF EX OC beq adr INST 3 IF ID OF EX OC ... INST 4 IF ID OF EX OC ... CK INST 1 IF ID OF EX OC cmp #0,r1 INST 2 IF ID OF EX OC beq adr INST 3 IF ID OF EX OC ... INST 4 IF ID OF EX OC ...
Prédiction statique Les sauts sont, en moyenne, pris environ 50% des fois. Par contre, les sauts en arrière (boucles) sont plus souvent pris que pas pris, et inversement pour les sauts en avant. Cette observation est à l'origine d'une troisième stratégie de prédiction: • Prédiction selon la direction: si le saut est en arrière, il est pris, s'il est en avant, il n'est pas pris. Cette stratégie donne des très bons résultats (70-80%) avec une augmentation relativement restreinte de la logique de contrôle: elle est utilisée dans plusieurs processeurs (p.ex., MicroSparc, HP-PA). Le choix de la direction du saut peut aussi être définie par le compilateur sur la base d'une analyse (statique) du code (p.ex. MIPS, PowerPC). Dans ce cas, on parle de prédiction semi-statique.
Prédiction dynamique Pour réaliser une prédiction dynamique le processeur mémorise le comportement du programme lors de l'exécution des sauts. À chaque exécution d'un branchement dans un programme, le processeur mémorise si le saut était pris ou pas pris dans un tampon de prédiction de branchement (branch prediction buffer) ou table historique de branchement (branch history table). Sur la base du comportement passé du programme pour un branchement donné, le processeur prédit son comportement pour l'exécution suivante du même saut. Par rapport à la prédiction statique, la prédiction dynamique est plus performante, mais nécessite une quantité très importante de logique de contrôle.
Tampon de prédiction de branchement Ce tampon de prédiction est simplement une mémoire (très proche en structure à un cache) adressée par le PC (c'est-à-dire par l'adresse de l'instruction de saut). PC Prédiction ADRESSES HISTOIRE = SLC = = = Les tampons de prédiction ne sont d'habitude pas très grands: la performance d'un tampon de 4K entrées est très proche de celle d'un tampon de taille infinie. Il faut aussi remarquer que, à la différence du cache, aucun traitement particulier n'est nécessaire lors d'un miss.
Prédiction dynamique L'algorithme le plus simple utilise un seul bit par saut pour mémoriser le comportement du programme lors de la dernière exécution du saut. Si la prédiction s'avère fausse, le bit est inversé. Le désavantage principal de cet algorithme est que, si un branchement est presque toujours pris (ce qui arrive assez souvent, par exemple, dans les boucles), on fera deux fausses prédictions quand il ne l'est pas. NON PRIS PRIS A prédit pris B prédit non pris PRIS NON PRIS
Prédiction dynamique Une solution pour éviter la double fausse prédiction de l'algorithme précédent est d'ajouter un bit supplémentaire au tampon de prédiction: deux bits sont alors associés à chaque instruction de saut. Les schémas de prédiction à deux bits permettent d'obtenir des pourcentages de bonnes prédictions qui peuvent varier entre 82% et 99%, ce qui le rends très populaires. Des schémas à plus de deux bits existent, mais l'amélioration de la performance est minime. NON PRIS PRIS A prédit pris B prédit pris PRIS NON PRIS PRIS NON PRIS C prédit non pris D prédit non pris PRIS NON PRIS
Interruptions La présence d'un pipeline complique le traitement des interruptions: lors du déclenchement d'une interruption non-masquable, la routine de traitement doit parfois être lancée immédiatement. Le pipeline contiendra alors des instructions partiellement exécutées. La seule solution efficace est de "vider" le pipeline. Cette opération peut toutefois compliquer le redémarrage du programme après le traitement de l'interruption (par exemple, il faut retrouver l'adresse de la première instruction dont l'exécution n'a pas été achevé). CK INST 1 IF ID OF EX OC INTERRUPTION INST 2 IF ID OF EX OC INST 3 IF ID OF EX OC INST 4 IF ID OF EX OC