Download
1 / 56
580 likes | 692 Vues
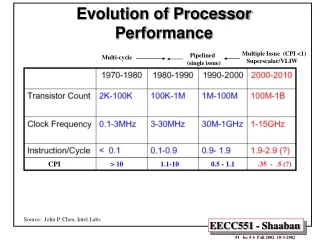
Topic 4 Processor Performance. AH Computing. Introduction. 6502 8 bit processor, 16 bit address bus Intel8086/88 (1979) IBM PC 16-bit data and address buses Motorola 68000 16-bit data and 24-bit address PowerPC (1992) Incorporated pipelining and superscaling. 8086. Introduction.

E N D
Topic 4 Processor Performance AH Computing
Introduction • 6502 • 8 bit processor, 16 bit address bus • Intel8086/88 (1979) • IBM PC • 16-bit data and address buses • Motorola 68000 • 16-bit data and 24-bit address • PowerPC (1992) • Incorporated pipelining and superscaling
Introduction Technological developments • RISC processors • SIMD • Pipelining • Superscalar processing
CISC- Complex Instruction Set Computer • Memory in those days was expensive • bigger program->more storage->more money • Hence needed to reduce the number of instructions per program • Number of instructions are reduced by having multiple operations within a single instruction • Multiple operations lead to many different kinds of instructions that access memory • In turn making instruction length variable and fetch-decode-execute time unpredictable – making it more complex • Thus hardware handles the complexity • Example: x86 ISA
CISC CISC Language Development • Increase instruction size of instruction sets (by providing more operations) • Design ever more complex instructions • Provide more addressing modes • Implement some HLL constructs in machine instruction sets
CISC • Intel 8086, 80286, 80386, 80486, Pentium • The logic for each instruction has to be hard-wired into the control unit • As new instructions developed they were added to original instructions set • Difficult and expensive to design and build • One way of solving this problem is to use microprogramming
CISC • Microprogramming – complex instructions are split into a series of simpler instructions • When a complex instruction is executed, the CPU executes a small microprogram stored in a control memory • This simplifies design of processor and allows the addition of new complex instructions
RISC • Attempt to make architecture simpler • Reduced number of instructions • Make them all the same format if poss. • Reduce the number of memory accesses required by increasing the number of registers • Reduce the number of addressing modes • Allow pipelining of instructions
RISC • The characteristics of most RISC processors are… • A large number of GP registers • A small number of simple instructions that mostly have the same format • A minimal number of addressing modes • Optimisation of instruction pipeline
RISC in the Home • Your home is likely to have many devices with RISC-based processors. • Devices using RISC-based processors include the Nintendo Wii, Microsoft Xbox 360, Sony PlayStation3, Nintendo DS and many televisions and phones. • However, x86 processors--those found in nearly all of the world's personal computers--are CISC. This is a limitation born of necessity; adopting a new instruction set for PC processors would mean that all the software used in PCs would no longer function.
Scholar Activity • Characteristics of RISC processor • Review Questions • Q6 – 7 • 2010 14a-c
Parallel Processing • At least two microprocessors handle parts of an overall task. • A computer scientist divides a complex problem into component parts using special software specifically designed for the task. • He or she then assigns each component part to a dedicated processor. • Each processor solves its part of the overall computational problem. • The software reassembles the data to reach the end conclusion of the original complex problem.
Single Instruction, Single Data (SISD) computers have one processor that handles one algorithm using one source of data at a time. The computer tackles and processes each task in order, and so sometimes people use the word "sequential" to describe SISD computers. They aren't capable of performing parallel processing on their own.
SIMD • Single Instruction, Multiple Data (SIMD) computers have several processors that follow the same set of instructions, but each processor inputs different data into those instructions. SIMD computers run different data through the same algorithm. This can be useful for analyzing large chunks of data based on the same criteria. Many complex computational problems don't fit this model.
SIMD • A single computer instruction performing the same identical action (retrieve, calculate, or store) simultaneously on two or more pieces of data. • Typically this consists of many simple processors, each with a local memory in which it keeps the data which it will work on. • Each processor simultaneously performs the same instruction on its local data progressing through the instructions in lock-step, with the instructions issued by the controller processor. • The processors can communicate with each other in order to perform shifts and other array operations.
SIMD Example • A classic example of data parallelism is inverting an RGB picture to produce its negative. • You have to iterate through an array of uniform integer values (pixels), and perform the same operation (inversion) on each one • …multiple data points, a single operation.
MMX (implementation of SIMD) • Short for Multimedia Extensions, a set of 57 multimediainstructions built into Intel microprocessors and other x86-compatible microprocessors. • MMX-enabled microprocessors can handle many common multimedia operations, such as digital signal processing (DSP), that are normally handled by a separate sound or video card.
SIMD • The Pentium III chip introduced eight 128 bit registers which could be operated on by the SIMD instructions
SIMD • The Motorola Power PC 7400 chips used in Apple G4 computers also provided SIMD instructions, which can operate on multiple data items held in 32 128-bit registers.
SIMD • Huge impact on the processing of multimedia data • Improves performance on any type of processing which requires the same instruction to be applied to multiple data items • Other examples - voice-to-text processing, data encryption/decryption
SIMD PP Questions • 2008 Q15
Pipelining • Instruction pipelining = assembly line • the processor works on different steps of the instruction at the same time, • more instructions can be executed in a shorter period of time.
fetch fetch fetch decode decode decode execute execute execute Execution of instructions without a pipeline time
fetch fetch fetch decode decode decode execute execute execute Execution of instructions with a pipeline time
Example - 5 Stage Pipeline • Instruction fetch (IF) • Instruction Decode (ID) • Execution (EX) • Memory Read/Write (MEM) • Result Writeback (WB) All modern processors operate pipelining with 5 or more stages
Problems with Pipelining • Led to an increase in performance • Works best when • all instructions are the same length and • follow in direct sequence • Not always the case!
Problems with Pipelining 3 problems that can arise during pipelining • Varying instruction lengths • Data Dependency • Branch instructions
Problems with Pipelining 1 Instruction Length • In CISC-based designs, instructions can vary in length • A long slow instructions can hold up the pipeline • Less of a problem in RISC-based designs as most instructions are fairly short
Problems with Pipelining 2 Data dependency • If one instruction relies on the result produced by a previous instruction • Data required for the 2nd instruction may not yet be available because the 1st instruction is still being executed • Pipeline must be stalled until data is ready for the 2nd instruction
Problems with Pipelining 3 Branch instructions • BCC 25 - branch 25 bytes ahead if the carry flag is clear • If the carry flag is set, the next instructions is carried out as normal • If the carry flag is clear then the instruction 25 bytes ahead is next
Instruction 3 is a Branch Instruction – requiring a jump to instruction 15 – so 4 instructions are flushed from the pipeline
Optimising the Pipeline Techniques include • Branch prediction • Data flow analysis • Speculative loading of data • Speculative execution of instructions • Predication
Optimising the Pipeline Branch prediction • Some processors predict branch "taken" for some op-codes and "not taken" for others. • The most effective approaches, however, use dynamic techniques.
Optimising the Pipeline Branch Prediction - Example Many branch instructions are repeated often in a program (e.g. the branch instruction at the end of a loop). The processor can then note whether or not the branch was "taken" previously, and assume that the same will happen this time. This requires the use of a branch history table, a small area of cache memory, to record the information. This method is used in the AMD29000 processor.
Optimising the Pipeline Data Flow Analysis • Used to overcome dependency • Processor analyses instructions for dependency • Then allocates instructions to the pipeline in an order which prevents dependency stalling the flow
Optimising the Pipeline Speculative loading of data • Processor looks ahead and processes early any instructions which load data from memory • Data stored in registers for later use (if required) • Discarded if not required
Optimising the Pipeline Speculative execution • Processor carries out instructions before they are required • Results stored in temporary registers • Discarded if not required
Optimising the Pipeline Predication • Tackles conditional branches by executing instructions from both branches until it knows which branch is to be taken
Optimising the Pipeline All of these techniques are possible due to • The increasing speeds • The increasing complexity • The increasing numbers of processors available in modern processors
Pipelining PP Questions • 2010 Q11b,c, 13a,b • 2009 13f • 2008 14c 16e • 2007 16 a,b,c,d • 2006 18a,b,d • 2011 13b,c
Superscalar Processing • More than one pipeline within the processor • Pipelines can work independently • Superscalar processors try to take advantage of instruction-level parallelism
Superscalar Processing • A superscalarCPU architecture implements a form of parallelism called instruction-level parallelism within a single processor. • It thereby allows faster CPU throughput than would otherwise be possible at the same clock rate. • A superscalar processor executes more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to redundant functional units on the processor.