Download

1 / 19
320 likes | 1.35k Vues
THE INTEL X86 PIPELINE VS THE MIPS PIPELINE. Introduction to Pipeline. A processor without pipelining executes instructions sequentially The next instruction can’t begin until the current instruction is completed Ex: Laundry analogy without pipelining. Introduction to Pipeline (cont.).

E N D
Introduction to Pipeline • A processor without pipelining executes instructions sequentially • The next instruction can’t begin until the current instruction is completed • Ex: Laundry analogy without pipelining
Introduction to Pipeline (cont.) • Processors with pipelining work on multiple instructions at once. • Each stage of the pipeline does a certain “job” on the instruction (such as fetching the instruction or loading necessary data) • Laundry analogy with pipelining
Introduction to Intel x86 processors • x86 family started with 8086 processor • 16 bit, no pipelining • First processor in Intel family to have pipelining was the Intel 386 with 6 stages (we will focus on this processor) • Current processor (Pentium IV) has a 20 stage pipeline
More details about Intel pipelining • Intel’s philosophy on pipelining is the longer the pipeline, the better • Advantages: • More stages allows for faster cpu cycle because each stage is doing less work • Disadvantages: • Misprediction on branch jumps causes a greater loss of time than a shorter pipeline • Stalling also causes a greater loss of time • Faster cpu cycle is misleading to the average customer
The Intel386 pipeline • 6 parallel units (stages): • Bus Interface Unit – accesses memory and I/O for other units • Code Prefetch Unit – receives object code from Bus Interface Unit and places it in a 16 byte queue • Instruction Decode Unit – decodes object code from queue into microcode • Execution Unit – Executes the microcode instruction • Segment Unit – translates logical addresses to linear addresses and does protection checks • Paging Unit – translates linear addresses to physical addresses
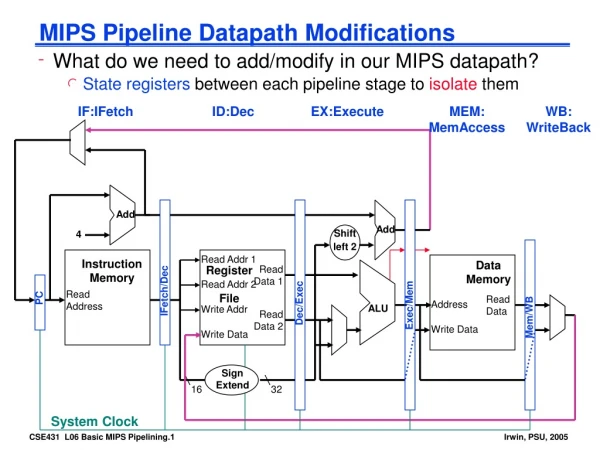
The MIPS Pipeline • 5 stages: • IF – fetches the instruction and stores it in the if / id pipeline register • ID – Decodes the instruction and obtains necessary registers and stores it in ID/EX • EX – reads the content of register 1 and the sign extended immediate from the ID/EX pipeline register, and adds them using the ALU. The sum is places in the EX/mem pipeline register • Mem – reads the data memory using the address from the Ex/ MEM register , and moves the data into the MEM/WE register • WB – Places result into the register file in the middle of the data path
INTEL CONTROL HAZARDS • Jump processing • Continues pipeline assuming branch not taken • Resolves the branch condition in the execution unit • Fetches jump target • If branch not taken • Allows pipelining to continue • Total of 1 cycle for instruction • If branch is taken • Flushed instruction in the pipeline and starts at the code prefetch unit with the target it previously found for the execution unit • Total of 3 cycles for instruction • (current Intel has 32 bit branch prediction register)
MIPS CONTROL HAZARDS • Early MIPS processors assumes branch not taken, then flushes pipeline if branch was taken • A loss of at most 1 cycle if mispredict • Later mips processors have branch prediction register using 2 bit branch history register
Structural Hazards • MIPS • Separate caches and ALU for each stage • Only read on first half of cycle and only write on second half • Intel • Prefetch unit waits until the needed hardware is available
Compare and contrast mips, Intel pipelining • Type of instructions • Mips uses RISC (Reduced Instruction Set Computer) • Intel uses CISC (Complex Instruction Set Computer) • Intel is harder to decode. It has 2 decoding stages. • Intel combines the mem and EX stage which avoids loads and stalls, but does create stalls for address computation • All stages in mips takes one cycle, where as Intel may take more than one for certain stages. This creates asymmetric performance
conclusion • The Intel and the Mips instruction pipelining both use the same basic concept of pipelining. They differ only on subtleties of handling the problems that occur when pipelining such as data and structural hazards, and also on the specific way in which the instructions are actually executed due to the different instruction set.Both the Intel and Mips accomplish the same result of dramatically reducing the execution time of a program threw the use of pipelining, and each has their own facilities and pitfalls of the technique they use.
Sources referenced • www.intel.com • Computer Organization and Design • by John L. Hennessy, and David A. Patterson • http://www.cs.jmu.edu/common/coursedocs/Adamses/Spring%202003%20-%20CS%20350%20Student%20Papers%20and%20Slides/History%20of%20the%20Intel%20Pentium%20Processor-Topp-Schulze.doc • http://www.vannattabros.com/history6.html • http://www.pcmag.com/article2/0,1759,1513577,00.asp