Download
1 / 1
10 likes | 176 Vues
LINEAR MODELLING AND PREDICTION OF BIOCONCENTRATION FACTOR (BCF) BY THEORETICAL MOLECULAR DESCRIPTORS Papa Ester - Gramatica Paola Dep.Struct.Funct.Biol. - QSAR Research Unit - University of Insubria ( Varese - Italy )

E N D
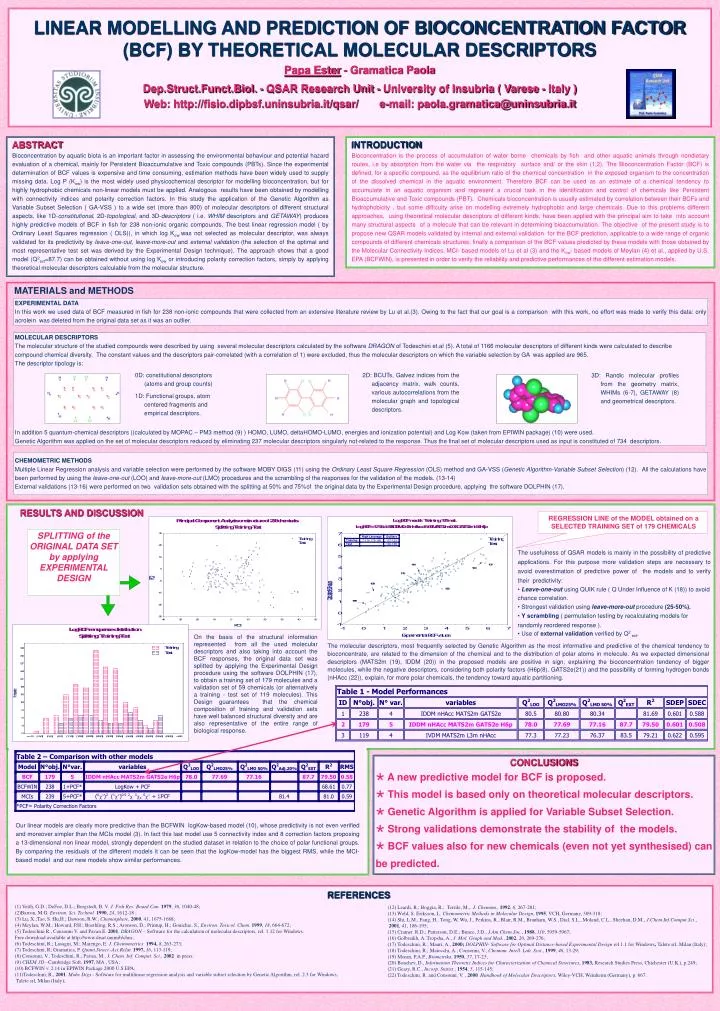
LINEAR MODELLING AND PREDICTION OF BIOCONCENTRATION FACTOR (BCF) BY THEORETICAL MOLECULAR DESCRIPTORS Papa Ester - Gramatica Paola Dep.Struct.Funct.Biol. - QSAR Research Unit - University of Insubria ( Varese - Italy ) Web: http://fisio.dipbsf.uninsubria.it/qsar/ e-mail: paola.gramatica@uninsubria.it ABSTRACT Bioconcentration by aquatic biota is an important factor in assessing the environmental behaviour and potential hazard evaluation of a chemical, mainly for Persistent Bioaccumulative and Toxic compounds (PBTs). Since the experimental determination of BCF values is expensive and time consuming, estimation methods have been widely used to supply missing data. Log P (Kow) is the most widely used physicochemical descriptor for modelling bioconcentration, but for highly hydrophobic chemicals non-linear models must be applied. Analogous results have been obtained by modelling with connectivity indices and polarity correction factors. In this study the application of the Genetic Algorithm as Variable Subset Selection ( GA-VSS ) to a wide set (more than 800) of molecular descriptors of different structural aspects, like 1D-constitutional, 2D-topological, and 3D-descriptors (i.e. WHIM descriptors and GETAWAY) produces highly predictive models of BCF in fish for 238 non-ionic organic compounds. The best linear regression model ( by Ordinary Least Squares regression ( OLS)), in which log Kow was not selected as molecular descriptor, was always validated for its predictivity by leave-one-out, leave-more-out and external validation (the selection of the optimal and most representative test set was derived by the Experimental Design technique). The approach shows that a good model (Q2ext=87.7) can be obtained without using log Kow or introducing polarity correction factors, simply by applying theoretical molecular descriptors calculable from the molecular structure. INTRODUCTION Bioconcentration is the process of accumulation of water borne chemicals by fish and other aquatic animals through nondietary routes, i.e by absorption from the water via the respiratory surface and/ or the skin (1,2). The Bioconcentration Factor (BCF) is defined, for a specific compound, as the equilibrium ratio of the chemical concentration in the exposed organism to the concentration of the dissolved chemical in the aquatic environment. Therefore BCF can be used as an estimate of a chemical tendency to accumulate in an aquatic organism and represent a crucial task in the identification and control of chemicals like Persistent Bioaccumulative and Toxic compounds (PBT). Chemicals bioconcentration is usually estimated by correlation between their BCFs and hydrophobicity , but some difficulty arise on modelling extremely hydrophobic and large chemicals. Due to this problems different approaches, using theoretical molecular descriptors of different kinds, have been applied with the principal aim to take into account many structural aspects of a molecule that can be relevant in determining bioaccumulation. The objective of the present study is to propose new QSAR models validated by internal and external validation for the BCF prediction, applicable to a wide range of organic compounds of different chemicals structures; finally a comparison of the BCF values predicted by these models with those obtained by the Molecular Connectivity Indices, MCI- based models of Lu et al (3) and the Kow- based models of Meylan (4) et al., applied by U.S. EPA (BCFWIN), is presented in order to verify the reliability and predictive performances of the different estimation models. MATERIALS andMETHODS EXPERIMENTAL DATA In this work we used data of BCF measured in fish for 238 non-ionic compounds that were collected from an extensive literature review by Lu et al.(3). Owing to the fact that our goal is a comparison with this work, no effort was made to verify this data: only acrolein was deleted from the original data set as it was an outlier. MOLECULAR DESCRIPTORS The molecular structure of the studied compounds were described by using several molecular descriptors calculated by the software DRAGON of Todeschini et.al (5). A total of 1166 molecular descriptors of different kinds were calculated to describe compound chemical diversity. The constant values and the descriptors pair-correlated (with a correlation of 1) were excluded, thus the molecular descriptors on which the variable selection by GA was applied are 965. The descriptor tipology is: In addition 5 quantum-chemical descriptors ((calculated by MOPAC – PM3 method (9) ) HOMO, LUMO, deltaHOMO-LUMO, energies and ionization potential) and Log Kow (taken from EPIWIN package) (10) were used. Genetic Algorithm was applied on the set of molecular descriptors reduced by eliminating 237 molecular descriptors singularly not-related to the response. Thus the final set of molecular descriptors used as input is constituted of 734 descriptors. 0D: constitutional descriptors (atoms and group counts) 1D: Functional groups, atom centered fragments and empirical descriptors. 2D: BCUTs, Galvez indices from the adjacency matrix, walk counts, various autocorrelations from the molecular graph and topological descriptors. 3D: Randic molecular profiles from the geometry matrix, WHIMs (6-7), GETAWAY (8) and geometrical descriptors. CHEMOMETRIC METHODS Multiple Linear Regression analysis and variable selection were performed by the software MOBY DIGS (11) using the Ordinary Least Square Regression (OLS) method and GA-VSS (Genetic Algorithm-Variable Subset Selection) (12). All the calculations have been performed by using the leave-one-out (LOO) and leave-more-out (LMO) procedures and the scrambling of the responses for the validation of the models. (13-14) External validations (13-16) were performed on two validation sets obtained with the splitting at 50% and 75%of the original data by the Experimental Design procedure, applying the software DOLPHIN (17). RESULTS AND DISCUSSION REGRESSION LINE of the MODEL obtained on a SELECTED TRAINING SET of 179 CHEMICALS SPLITTING of the ORIGINAL DATA SET by applying EXPERIMENTAL DESIGN • The usefulness of QSAR models is mainly in the possibility of predictive applications. For this purpose more validation steps are necessary to avoid overestimation of predictive power of the models and to verify their predictivity: • Leave-one-outusing QUIK rule ( Q Under Influence of K (18)) to avoid chance correlation. • Strongest validation using leave-more-outprocedure(25-50%). • Y scrambling ( permutation testing by recalculating models for randomly reordered response ). • Use of external validation verified by Q2 ext. On the basis of the structural information represented from all the used molecular descriptors and also taking into account the BCF responses, the original data set was splitted by applying the Experimental Design procedure using the software DOLPHIN (17), to obtain a training set of 179 molecules and a validation set of 59 chemicals (or alternatively a training - test set of 119 molecules). This Design guarantees that the chemical composition of training and validation sets have well balanced structural diversity and are also representative of the entire range of biological response. The molecular descriptors, most frequently selected by Genetic Algorithm as the most informative and predictive of the chemical tendency to bioconcentrate, are related to the dimension of the chemical and to the distribution of polar atoms in molecule. As we expected dimensional descriptors (MATS2m (19), IDDM (20)) in the proposed models are positive in sign, explaining the bioconcentration tendency of bigger molecules, while the negative descriptors, considering both polarity factors (H6p(8), GATS2e(21)) and the possibility of forming hydrogen bonds (nHAcc (22)), explain, for more polar chemicals, the tendency toward aquatic partitioning. • CONCLUSIONS • A new predictive model for BCF is proposed. • This model is based only on theoretical molecular descriptors. • Genetic Algorithm is applied for Variable Subset Selection. • Strong validations demonstrate the stability of the models. • BCF values also for new chemicals (even not yet synthesised) can be predicted. Our linear models are clearly more predictive than the BCFWIN logKow-based model (10), whose predictivity is not even verified and moreover simpler than the MCIs model (3). In fact this last model use 5 connectivity index and 8 correction factors proposing a 13-dimensional non linear model, strongly dependent on the studied dataset in relation to the choice of polar functional groups. By comparing the residuals of the different models it can be seen that the logKow-model has the biggest RMS, while the MCI- based model and our new models show similar performances. (1) Veith, G.D.; DeFoe, D.L.; Bergstedt, B. V. J. Fish Res: Board Can.1979, 36, 1040-48; (2)Barron, M.G. Environ. Sci. Technol.1990, 24, 1612-18 ; (3) Lu, X.;Tao, S. Hu,H.; Dawson, R.W., Chemosphere, 2000, 41, 1675-1688; (4) Meylan, W.M.; Howard, P.H.; Boethling, R.S.; Aronson, D.; Printup, H.; Gouichie, S., Environ. Toxicol. Chem. 1999, 18, 664-672; (5) Todeschini R., Consonni V. and Pavan E. 2001. DRAGON – Software for the calculation of molecular descriptors, rel. 1.12 for Windows. Free download available at http://www.disat.unimib/chm.; (6) Todeschini, R.; Lasagni, M.; Marengo, E. J. Chemometrics1994, 8, 263-273; (7) Todeschini, R; Gramatica, P. Quant.Struct.-Act.Relat.1997, 16, 113-119; (8) Consonni, V., Todeschini, R., Pavan, M., J. Chem. Inf. Comput. Sci., 2002 in press; (9) CHEM 3D –Cambridge Soft, 1997, MA , USA; (10) BCFWIN v. 2.14 in EPIWIN Package 2000 U.S.EPA; (11)Todeschini, R., 2001. Moby Digs - Software for multilinear regression analysis and variable subset selection by Genetic Algorithm, rel. 2.3 for Windows, Talete srl, Milan (Italy); REFERENCES (12) Leardi, R.; Boggia, R.; Terrile, M.,. J. Chemom., 1992, 6, 267-281; (13) Wold, S. Eriksson, L. Chemometric Methods in Molecular Design, 1995, VCH, Germany, 309-318; (14) Shi, L.M., Fang, H., Tong, W, Wu, J., Perkins, R., Blair, R.M., Branham, W.S., Dial, S.L., Moland, C.L., Sheehan, D.M., J.Chem.Inf.Comput.Sci., 2001, 41, 186-195; (15) Cramer. R.D.; Patterson, D.E.; Bunce, J.D., J.Am.Chem.Soc., 1988, 110, 5959-5967; (16) Golbraikh, A. Tropsha, A., J. Mol. Graph and Mod., 2002, 20, 269-276; (17)Todeschini, R.; Mauri, A., 2000; DOLPHIN- Software for Optimal Distance-based Experimental Design rel 1.1for Windows, Talete srl, Milan (Italy); (18) Todeschini, R.; Maiocchi, A.; Consonni, V., Chemom. Intell. Lab. Syst., 1999, 46, 13-29; (19) Moran, P.A.P., Biometrika, 1950, 37, 17-23; (20) Bonchev, D., Information Theoretic Indices for Characterization of Chemical Structures, 1983, Research Studies Press, Chichester (U.K.), p.249; (21) Geary, R.C., Incorp. Statist., 1954, 5, 115-145; (22) Todeschini, R. and Consonni, V. , 2000. Handbook of Molecular Descriptors, Wiley-VCH, Weinheim (Germany), p. 667.



















