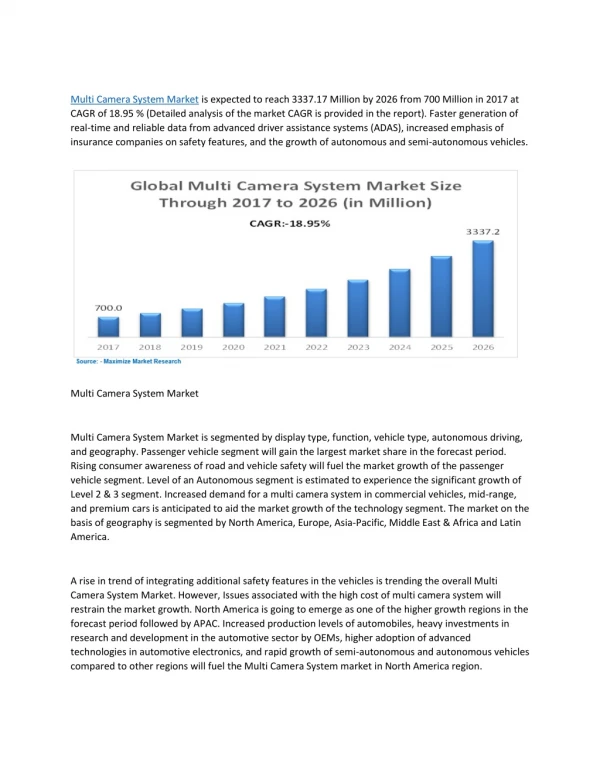
Download

1 / 19
190 likes | 222 Vues
This project explores speech recognition in a moving car using an innovative setup with 8 microphones and 4 cameras mounted strategically. The AVICAR system records diverse talkers in various noise conditions for testing speech recognition models. The experiments involve audio and video analysis, focusing on features like facial tracking, noise reduction, and fusion models for improved accuracy. Results showcase the effectiveness of multi-channel estimation and beamforming techniques. Additionally, the project delves into audio-visual asynchrony studies, highlighting the significance of gesture-phonology-based models in understanding speech processing mechanisms. The dataset is open for public use, offering valuable insights for future research in this domain.

E N D
Multi-Camera, Multi-Microphone Speech Recognition in a Moving Car Mark Hasegawa-Johnson Thanks to the Motorola Communications Center And to Tom Huang, Ming Liu, Bowon Lee, Laehoon Kim, Camille Goudeseune, Michael McLaughlin, Sarah Borys, Jonathan Boley, Suketu Kamdar, Karen Livescu, and Partha Lal.
8 Mics, Pre-amps, Wooden Baffle. Best Place= Sunvisor. 4 Cameras, Glare Shields, Adjustable Mounting Best Place= Dashboard AVICAR Recording Hardware(Bowon Lee et al., ICSLP 2004) System is not permanently installed; mounting requires 10 minutes.
AVICAR Database • 100 Talkers • 4 Cameras, 7 Microphones • 5 noise conditions: Engine idling, 35mph, 35mph with windows open, 55mph, 55mph with windows open • Three types of utterances: • Digits & Phone numbers, for training and testing phone-number recognizers • Phonetically balanced sentences, for training and testing large vocabulary speech recognition • Isolated Letters, to test the use of video for an acoustically hard recognition problem • Open-IP public release to 15 institutions, 5 countries
Experiments with AVICAR Data • Audio • Multi-microphone voice activity detection • Multi-microphone spectral estimation • Video • Facial feature tracking & segmentation • Head pose and facial feature normalization • Fusion • Models of audio-visual asynchrony • Gestural-phonology based models of constriction state asynchrony
Noise from the Perspective of the Brainstem • Something happened!! • What does the new thing look/sound like? • What is it?
A Conservative Computational Audio(-ish) Model x(t) Lexical Access (Networks With Feedback) Average Background Loudness lN Auditory Nerve Carries The Loudness Spectrum ~ |X(f)|2/3 (Fletcher) Video Change Detection Basilar Membrane Variable Threshold Synapses = Amplitude Compression (Ghitza, 1986) Loudness To Phonetic Features (“tandem”) MMSE Estimator of “New Event” E[ |S(f)|2/3 | X ] Signal from the other ear
Optimal Multi-Channel Audio Estimation(Balan and Rosca, 2002; Laehoon Kim, ICASSP 2006) • Goal: MMSE estimate of clean speech loudness spectrum (|S(f)|2/3) given multichannel reverberant noisy measurement (X=HS+V, H = reverberant channel, V = noise) • Given a good channel estimate, the probability density p(|S(f)|2/3 | X) factors into two stages: • p(Ŝ | X), the PDF given X of the MMSE estimate of the time-domain speech signal • p(|S(f)|2/3 | Ŝ), the PDF given Ŝ of any function of S (e.g., of its loudness spectrum).
Results: MMSE-optimal beamformer followed by MMSE log spectral amplitude estimator
Word Error Rate with Beamformers Ten-digit phone numbers; trained and tested with 50/50 mix of quiet (engine idling) and very noisy (55mph, windows open); MLLR
WER with Spectral Estimation Ten-digit phone numbers; trained and tested with 50/50 mix of quiet (engine idling) and very noisy (55mph, windows open); MLLR
AVICAR “Constellation” • Four face rectangles provide information about head pose (useful for normalization) • Positions of lip within faces provide information about head pose (useful for normalization) • Lip height, width provide information about speech (useful for speech recognition) • DCT of pixels within all four lip rectangles provide information about speech (useful for speech recognition)
Facial Feature Variability • … tends to result in large changes in the feature mean (e.g., different talkers have different average lip-rectangle sizes) • Changes in the class-dependent feature mean can be compensated by maximum likelihood linear regression
Video-Only Phone Number Recognition LR = linear regression Model = model-based head-pose compensation LLR = log-linear regression 13+d+dd = 13 static features 39 = 39 static features All systems have mean and variance normalization and MLLR
Audio-Visual Asynchrony For example, tongue touches the teeth before acoustic speech onset in the word “three;” lips are already round in anticipation of the /r/.
Audio-Visual Asynchrony: Coupled HMM is a typical Phoneme-Viseme Model(Stephen Chu and Tom Huang, 2001)
Asynchrony in Gestural Phonology(Browman and Goldstein, 1992) “three” Round Spread Lips Dental Critical Retroflex Narrow Palatal Narrow Tongue Unvoiced Voiced Glottis time
Modeling Asynchrony Using Constriction State Variables in a DBN(Livescu and Saenko, 2005) Wordt Wordt+1 Glottist Glottist+1 Tonguet Tonguet+1 Lipst Lipst+1 Audiot Audiot+1 Videot Videot+1
Summary of Results • 100-talker audiovisual speech database was recorded in moving automobiles, is available free. • MMSE multichannel estimate of cepstral features. Best current WER in multi-noise condition: 3.5%. • Stereo video features: DCT+lip size, with lighting & head-pose normalization. Best current WER: 47% • Audiovisual fusion: goal is to test a DBN model based on articulatory phonology.