Inverted Index Compression and Query Processing with Optimized Document Ordering
Inverted Index Compression and Query Processing with Optimized Document Ordering. Hao Yan, Shuai Ding, Torsten Suel Department of Computer Science and Engineering, Polytechnic Institute of New York University, Brooklyn, NY 11201 Yahoo! Research.


Inverted Index Compression and Query Processing with Optimized Document Ordering
E N D
Presentation Transcript
Inverted Index Compression and Query Processingwith Optimized Document Ordering Hao Yan, Shuai Ding, Torsten Suel Department of Computer Science and Engineering, Polytechnic Institute of New York University, Brooklyn, NY 11201 Yahoo! Research
What are the best compression methods for compressing indexes of search engines? In particular, what if given a particular ordering of documents?
Outline • Motivation &Background • Our Methods • Conclusion
Search Engines – Performance Challenge •Performance challenges inlarge web search engines: - A large amount of data (>1,000,000,000 pages) - Fast! (>1,000 queries/second)
Many ways to improve performances •Caching • Early termination • Parallel processing •Data compression (inverted index compression)
After disk traffic! the required size of memory Using Compression is Better Before
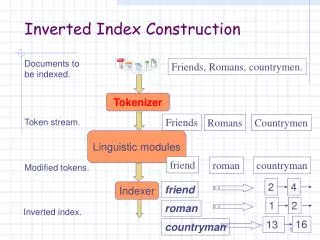
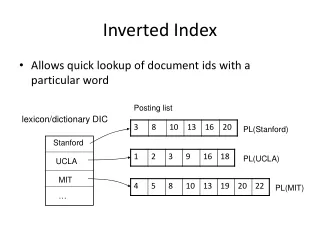
madrid 345, 777, 11437,…. museum 777, 1234, 4356, 12457,…. spain 4, 19, 29, 98, 143, 777, ... barcelona 145, 457, 777, 789, ... mall 678, 777, 2134, 3970, ... university 90, 256, 372, 511, 777, 1000, ... What are Inverted Indexes? •Storing information about where a word (term) occurs in the collection • Each word has an inverted list that is a sequence of integers (called docIDs), each of which uniquely identify a document in the collection •Inverted Indexes = a set of such inverted lists
DocID + Frequency •madrid: 345, 777, 11437,…. • madrid:<345, 7>, <777,4>, <11437,11>, … •Inverted list : <docID1, freq1>, <docID2, freq2>,<docID3, freq3>, … •Normal layout for better compression: store docIDs and frequencies separately madriddocID : 345, 777, 1437, … freq:7, 4, 11, ...
D-gaps (Differences Between DocIDs) • DocIDs madrid: 345, 777, 11437, … • D-gaps madrid: 345, 432, 10660, … • Frequences (Freqs): madrid: 7, 4, 11, ... Not in sorted order! No gaps!
Blocks of Inverted Lists (d-gaps) • madrid: 345, 111, 1, …, 2, 14, …, 312, 423, .. Partitioned into blocks •madrid: 345, 111, 1, …, 2, 14, …, 312, 423, .. block1 block2 block3 …
block1 block2 block3 … Indexes – In Summary •D-gaps: 345, 111, 1, …, 78 2, 14, …, 112 312, 423, …, 1238 ….. •Freqs: 4, 3, 7, …, 3 2, 8, …, 5 7, 3, …, 1 …..
Query Processing Index Index 777 madrid 345, 777, 11437,…. museum 777, 1234, 4356, 12457,…. disk memory
How to Judge Compression Techniques • Small compressed index size • Fast decompression (frequently called) • Compression can be slower (seldom called)
Existing Research on Compressing •DocID Many existing techniques •Frequency Few techniques
Related Research – Reordering • Given a collection of N documents, we need to first assign them document IDs •DocIDs can be assigned randomly, or simply in the order documents are crawled • However, researchers have found that special assignment strategies may result in better compression
Related Research – Reordering • R. Blanco and A. Barreiro. Document identifier reassignment through dimensionality reduction. ECIR’05. • D. Blandford and G. Blelloch. Index compression through document reordering. DCC’02 • W. Shieh, T. Chen, J. Shann, and C. Chung. Inverted file compression through document identifier reassignment. Inf. Processing and Management, 2003. • F. Silvestri. Sorting out the document identifier assignment problem. ECIR’07. • F. Silvestri, S. Orlando, and R. Perego. Assigning identifiers to documents to enhance the clustering property of fulltext indexes. SIGIR’04
Related Research – Reordering •Idea: first sort documents in a particular order such that similar documents are clustered (close to each other); then assign docIDs sequentially •Advantage: most d-gaps are smaller and can be better compressed •Reason:If a word occurs in a document, it is very likely it will occur in the similar documents; if these similar documents have similar docIDs, the d-gaps in the word’s inverted list will become much smaller • madrid (docIDs) 345, 777, 11437, 11438, 11443, 11450, ….. • madrid (d-gaps) 345, 432, 10660, 1, 5, 7,….. • One interesting re-ordering method: • sorting documents by URLs (F. Silvestri, Sorting out the document identifier reassignment problem, ECIR’07)
Existing Research about Compression with Reordering • Previous work has focused on determining the best possible ordering of documents • However, few existing techniques focusing on compressing indexes AFTER reordering • DocID : NO • Frequency: NO
Our work – the rest of the talk Given the special reordering (sorting by URLs), we study: •The best inverted index compression methods for • DocID • Frequency •Query processing •A hybrid approach combining different methods
DocID Compression - Contributions • Extensively study most existing methods •Propose improved PForDelta coding • Study effects on docID compression of document re-ordering
Experiment Setup • Data set • TREC GOV2 , 25.2 million pages • 1000 randomly selected queries • Measurement Metric • Size • Data associated with each query:MB/query • Data for the entire indexes: MB • Bits/int (somewhere) • Speed • Million Integers/second • Different orderings • Original • Random • Sorted
DocID (d-gap) Compression • Gamma coding • Delta coding • Variable byte coding (Var-byte) • Golomb coding • Rice coding • RiceVT coding • Simple9 (S9) • Simple16 (S16) • Interpolative (IPC) • PForDelta (PFD)
PForDelta coding (PFD) • S. Heman. Super-scalar database compression between RAM and CPU-cache. MS Thesis, Centrum voor Wiskunde en Informatica, Netherlands, July 2005 • M. Zukowski, S. Heman, N. Nes, and P. Boncz. Super-scalar RAM-CPU cache compression. In Proc. of the Int. Conf. on Data Engineering, 2006 • Decompression is extremely fast • Compression is not the best but still good
Problem: •We have to insert extra exceptions if two consecutive exceptions are far from each other PForDelta Coding (PFD, by S. Heman, etc) • Using 2 bits to encode 128 numbers 1 2 3 4 5 6 7 ... 124 125 126 127 128 3 42 2 3 3 1 1 … 3 3 23 1 2 11 10 11 11 01 01 … 11 11 01 10 42 23 a block of 128 numbers
lower 2 bits of 23 11 low 10 11 11 01 01 … 11 11 low 01 10 • Offset array S9, S16 • Exception array high high higher bits of 23 First Improvement of PForDelta (NewPFD) • Using b (e.g., 2) bits to encode 128 numbers 1 2 3 4 5 6 7 ... 124 125 126 127 128 3 42 2 3 3 1 1 … 3 3 23 1 2 11 10 11 11 01 01 … 11 11 01 10 42 23
Second Improvement of PForDelta (OptPFD) • How to select the number of bits b for each block? • The original PFD uses a constant value for b • A constant b is not good enough • b , waster more bits to encode each number • b , resulting in more exceptions • The best b should achieve the the best tradeoff between the compressed size and the decompresion speed • Difficult to formulize this
Second Improvement of PForDelta (OptPFD) How to select the number of bits b for each block? • Derive a global table for the choice of b -> tradeoff btw size and speed • Based on the table, we can dynamically choose b during query processingto achieve the best overall performance (We will talk this in more detail later)
Global table for OptPFD We want •Decompression speed is above 1200 Million DocIDs/second • Compressed size is no more than 1.5 MB/query
PForDelta is Extremely Fast for Decompression! Over 1 billion docIDs/second ! Million docIDs/second
Only1.47 bit/docID DocID Compression – with Re-ordering
Frequency Compression – Related Work • Few papers especially focusing on it •Usually just choose the methods that work well for compressing small numbers, such as Gamma coding, or Rice coding • No one has studied it for web indexes under document reordering
Frequency Compression – Unique Features • Normally frequencies are quite small values •Unlike docIDs, they are not in sorted order (this has nothing to do with re-ordering) •Re-ordering make them clustered, but we cannot directly take advantage of the clustering as docIDs since we cannot take gaps of them
Frequency Compression - My Algorithms • However, we still want to take advantage of the clustering property brought by reordering • Idea: When things are clustered but unsorted, we can use some transform to make the frequency values smaller • Preprocessing techniques: • Move to front (MTF) (Bently, burrows-wheeler compression, Comm. Of the ACM, 1986) • Most likely next (MLN)
Our Preprocessing Algorithms: MTF / MLN • Idea: Use indexes of previously occurrences to encode the current number. • Move to front (MTF) : Keep an additional index array, and do Move-To-Front operation during encoding • Most likely next (MLN): Keeps a small table that stores for each value which values are most likely to follow, sort values by their likelihoods, and then use indexes in the table to represent the values • Why better? Values of indexes of frequencies are smaller when frequencies are clustered !
Only 1.54 bit/freq Results – Compressed Size Compressed size (MBytes/query)
Results – Decompression Speed million frequencies/second
Compressed Size for the Entire Indexes Compressed • IPC, NewPFD, OptPFD • Compressed index size (MB) on the entire GOV2 data set, containing 25.2 Million web pages and the uncompressed size of it is 500GB!!! • IPC: 3.45GB, our optimized PFD is 3.88GB and super fast!
decompress skip skip Query Processing – Skipping 14 23 … 43 67 77 … 89 100 123 … 150 block3 (compressed ) block1 (compressed ) block2 (compressed ) • We must decompress the entire block of docIDs • Search 123:
• Query processing is faster ! • Reason: •After sorting by URLs, docIDsare clustered into fewer blocks! •Therefore, fewer blocks of docIDs need to be decompressed Query Processing – Impact of Reordering OptPFD
Then, How To Compress Indexes? • Tradeoff : compressed size vs decompression speed • Mixed Methods • Frequently used indexes – faster decompression e.g., PForDelta •Non-frequently used indexes – smaller compressed size e.g., IPC
PForDelta ? Or IPC? madrid 345, 777, 11437,…. museum 777, 1234, 4356, 12457,…. spain 4, 19, 29, 98, 143, 777, ... barcelona 145, 457, 777, 789, ... mall 678, 777, 2134, 3970, ... university 90, 256, 372, 511, 777, 1000, ... One Example of Using Mixed Methods • Goal: • The overall index size is minimized • While average time per query < a given time limit T •Solution: • Choose the list and compression methods that gives you the smallest increase in index size per time saved • Note: this can be easily integrated into the normal process of index construction, especially when indexes are built block-wise
Mixed Methods with OptPFD and IPC IPC OptPFD
Conclusions – How to Compress Web Indexes? Previous researchers found: • Reordering improve docID compression using standard compression methods In our paper: Given a particular ordering – sorting by URLs • DocID: • We proved this (sorting by URLs is better) by testing on most existing compression methods. • We proposed optimizedPForDelta which achieves the best performance in terms of both compressed size and decompression speed •Frequency • We proposed MTF/MLN to reduce the compressed size •Query processing (QP) • We found that reordering improves QP since less number of docIDs/freqs need to be decoded • Mixed Methods: We propose a hybrid method to try to achieve the best tradeoff between • The compressed size • Decompresion speed