Design
The Splice methodology revolutionizes system design by simplifying application complexity through middleware adaptation. It emphasizes a "divide and conquer" approach, allowing for autonomous processes that enhance interoperability and scalability within legacy and modern systems. The Shared Data Space concept facilitates interaction via a common data repository where autonomous applications operate independently, ensuring robust data management and fault tolerance. As a result, design and integration efforts become more efficient, enabling incremental deployments and a future-proof architecture with enhanced component reuse.

Design
E N D
Presentation Transcript
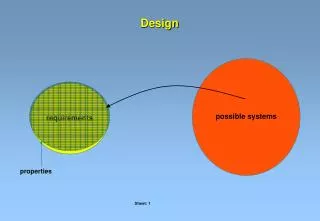
properties Design possible systems requirements
Divide and conquer No properties
Splice • Deceptively simple, yet powerful concept • major shift of application complexity to middleware • has proven to greatly simplify system design • radically changed the ratio between design and integration effort • Integration oriented • components • legacy systems • incremental deployment • interoperability • different operational modes
Splice • Highly adaptive • future proof • component re-use • robust • scalable • Paradigm shift • simple concept, thus small learning effort • bridges the gap between design and implementation
Shared Data Space • Common data repository • Autonomous applications • Interaction only through SDS • Only deals with appl. program interaction • Does not hide O.S.
Dataspace • System statespace partitioned into “sorts” • A “sort” is represented as a <tag,value> pair • Access to data through tags and queries
Shared Data Space Conceptual architecture
Design consequences • Assume a traffic management application • Detection loops in road surface • Control station • Visual signals for drivers • One process collects data from detection loops • Another process decides on signals • A third process interacts with road manager collect decide interact situation traffic parameters
Collect: • suppose collect buffers all measurements as ‘traffic’ while (true) put_data(‘traffic’,traffic); sleep(n); • Decide: • decide requests a batch of measurements, then uses the current parametersettings to compute the signals to be set while (true) if ( (traffic_data:=get_data(‘traffic’)) == TRUE) params:=get_data(‘parameters’); situation:=compute_situation(traffic_data); signals:=compute_signals(situation, params); put_data(‘signals’, signals); put_data(‘situation’, situation); sleep(n);
Problems addressed • Processes are autonomous • failure of a process may result in starvation, but not in deadlock • processes can be added/removed • Distribution not yet solved • Scalability not addressed • recovery not handled
Shared Data Space Distribution • Data allocated in central dataspace • bottleneck for access • vulnerable for failures
Shared Data Space Distribution • Data uniquely allocated in distributed dataspace • remote access latency problem • vulnerable for failures
Distribution • Data replicated in distributed dataspace • shortest possible latencies • robust • consistency problem Shared Data Space Platform 1 Platform 2 Platform n
Design consequences • Extension of traffic management application • possibility of inconsistent behavior access traffic signals collect decide interact situation parameters traffic
Data survives appl. or machine crash when duplicated on multiple machines Persistence • Independent application processes • only task is to ensure availability of data • can be replicated, since no operational output • Special service for restoring lost data • Solution for process migration • Solution for fail-stop failures cache coupled to process Shared Data Space
Persistence Shared Data Space Data survives appl. or machine crash Data survives system crash
Fault tolerance • Cold stand-by (passive replication): use semi-persistence • Hot stand-by (semi-active replication) • process subscribes to all sorts, then waits for signal that it may start • a process manager activates one of possibly severalstandby processes if there is no active process • Active replication • currently, application developer’s problemthere is a theoretical, but not yet practical solution
Passive replication C P platform k platform i
Passive replication No history! P new C platform k platform i
g Passive replication state data state data C P state data state data platform k platform i
g Passive replication state data state data P new C state data state data platform k platform i platform i
g Passive replication state data state data P new C state data state data platform k platform i platform i platform i
pers. data state data appl progr state data file with persistent data appl progr state data Start-up sequence initializeSplice
A’ M Semi active replication A Shared Data Space
Engineering • Hot standby • need reliable fault detector - hard problem • selection of replica to become active process after failure • process must be engineered for this feature main subscribe(a); ... subscribe(z); wait_for_activation(); -- only one will be activate at any time while true ...
Semi-active replication C C P platform k platform i
Semi-active replication C P platform k platform i
M Scoping (worlds) A’ A
Engineering • Scalability • without data visibility restriction, processing requirements can become overwhelming • flat namespace gives configuration problem • Component isolation • identical subsystems may have same names • Different operational modes • training • simulation • testing / maintenance • operational
Worlds and subsystems v,x,z x,y,z x,y,z v,x,z z subsystem 0 subsystem 1 z system
Worlds and scopes Dynamic scopes
Worlds and scopes Variable grid & dynamic scopes
A’ M Scoping (privacy) A
Engineering • Automatic selection of available resource • uses standard mechanism for requesting service • service parameters allow discrimination between requests • Once a private connection is established uses standard mechanism • data sorts defined during negotiation • partition of dataspace unaccessible for others • Connection can be terminated by either participating process
A’ M Shared access A
Implementation • Shared dataspace consists of • connectivity administration • using dynamic (lazy) binding • publish/subscribe-based communication mechanism • data management facilities • configurable per subscription • system management facilities
Distribution Initial situation appl appl shared-data space herald i herald j multicast / broadcast
publish() j db availability of data of sort “” Distribution Declaration of intent appl appl subscribe(,db) shared-data space herald i herald j need for data of sort “”
+v Distribution Write operation appl appl write(,v) shared-data space j herald i herald j forward data
Distribution Read operation appl appl X = read(,q) shared-data space : j V herald i herald j
Distribution Write operation (detailed) write(,v) , QoS j <a,v0,t0>, <a,v1 ,t1 >, ..., <a,vn ,tn > t < t0 + timeout n = buffersize herald i forward data using specified QoS
Distribution Read operation • Several storage modules available • default: practical compromise between speed and sophistication • queue • history: ordered by application-defined time-stamp • single-place buffer • Application may specify own repository • Wake-up or polling choice
SPLICE • Datamodel • Sorts correspond to C structs or Ada records • Index may be defined • Sorts may be associated with multiple categories • Instances can be defined in different subspaces (worlds)
SPLICE • Subscription • per datasort, or • can be defined for a group of sorts, or • may be specified for sorts in a category, or • all sorts in a group of worlds • Datamanagement controlled by application • Data transfer mode application defined • Rich query language (depending on database used) • Filters for data-dependent subscription
temp temp, press, color color press Multi-sort subscription corresponding instances are assembled, based on common key (natural join) default values for missing instances may be defined
Data categories • User defined • Typical usage: • persistent data • starting a system in a predefined state • process-state data (context) • starting a process in a predefined state • persistent data • fault-tolerance • late starters
Subscription to category all in cat X in cat X
Subscription to category all in cat X in cat X in cat X Treated as individual subscriptions Sort spec made available for application Mechanism is used for persistence
Standard services • Sort name translation • World name translation • Persistent data management • Process restart • Hot stand-by
Introspection • Applications can subscribe to system data • hosts (nodes, machines) • processes • subscriptions • publications • data sorts • defined worlds • ...