A Dynamic Hybrid Cache Coherency Protocol for Shared-Memory MPSoC
This paper presents a novel dynamic hybrid cache coherency protocol aimed at enhancing the performance and energy efficiency of shared-memory multiprocessor system-on-chips (MPSoCs). By intelligently managing cache coherency through adaptive switching between invalidation and update protocols, the proposed solution minimizes memory access latencies while optimizing power consumption. We explore its effectiveness through experiments and performance comparisons utilizing projects such as FFT. The architecture enhances programmability in large-core scenarios while addressing power and performance challenges.


A Dynamic Hybrid Cache Coherency Protocol for Shared-Memory MPSoC
E N D
Presentation Transcript
A Dynamic Hybrid Cache Coherency Protocol for Shared-Memory MPSoC H. Chtioui*, R. Ben Atitallah+, S.Niar+, J.L. Dekeyser++ and M.Abid * *University of Sfax (Tunisia), +University of Valenciennes (France), ++INRIA Lille (France)
Power consumption: The new wall • Power increases nonlinearly with clock • High clock rates lead to poor power/performance efficiences • Cost cooling • Multi-core processor (or MPSoC) can get around this: Same performance with Reducing clock rate and saving power/energy consumption • Number of cores : 2X / 2 yrs ⇒ ≈ 64 cores in few years
Processor 1 + Cache Processor n + Cache Processor 1 + Cache Processor n + Cache Memory 1 Memory n Network on chip Centralized Shared Memory Network on chip Shared Memory Architecture for MPSoC • We focus on MPSoC architectures that use Shared Memory: • Facilitate programmability and integration of a large number of processors Distributedsharedmemory Centralized Mono/multi bankedsharedmemory
Shared Memory MPSoC : Examples ARM Cortex MPcore EyeQ2 TI Omap IBM Sony Cell
+50%/year +50%/Année Watts Processor/Memory Gap Cache to fill the gap Processor/Memory Perf Gap Power consumption Mechanism aiming at reducing both memory access latencies and energy consumption is necessary • MPSoC with centralized shared memory and network-on-chip (NoC): • disparity in term of speed between processor and memory - cache • interesting mechanism aiming at reducing both memory access latencies and energy consumption 10000 Mémoire goulot d’étranglement 1000 100 1 Memory Access= perf. 10 1 2004 2005 2006 2007 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 1980 1981 1982 1983 1984 1985 1986 1987 1988 2001 2002 2003
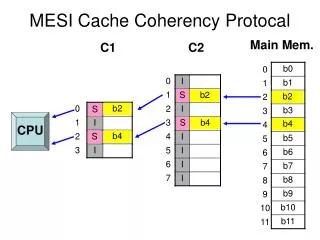
Cache Coherency Problem!! Processor 1 Processor 0 Processor 0 Processor 1 X 4 4 5 X X X 4 X<- 5 by processor 0 4 5 4 X X Shared memory Shared memory Copies of “X”are incoherent Copies of “X” are Coherent
Cache coherency techniques • Invalidation Protocol: send invalidation messages (adress) to sharer caches. • : data transfer operations. • : misses cache. • Update protocol: (address, value) of the data sent to all other sharers. • : misses cache. • : data transfer operations.
What is the best protocol? • Some experiments on the FFT (Fast Fourrier Transforms) • 3 Parallelization Schemes: • Producer/consumer (pipeline): shared blocs are Mostly-read : read more often than it is written • Task decomposition:shared blocs are read and written several times/processor. Processors cooperate in the calculation of the result. • Hybrid: both producer/consumer & task decomposition scheme used. Both mostly-read and frequently read-written shared data are present.
What is the best protocol? 4,2 3,5 4,1 3,4 4 3,3 3,9 Energy consumption (mJ) Energy consumption (mJ) 3,2 INVALIDATION 3,8 UPDATE 3,1 3,7 3 3,6 3,5 2,9 3,4 2,8 4KO 8KO 16KO 32KO 4KO 8KO 16KO 32KO Data cache size Data cache size FFT: Task decomposition Wrt shared data ++ FFT: Producer/consumer Wrt shared data --
Our Contribution • Improve performance & energy consumption of shared memory NoC-based MPSoC • Designing an efficient dynamic hybrid update/invalidate cache coherency protocol. • Based on a hardware solution (original architecture ): facilitates its implementation. • The proposed protocol captures changes of the data access patterns at run-time • Automatically switch to a new more efficient protocol when necessary.
Bus • Hybrid Protocol Implementation Architecture of the overall system Processor 1 Processor 0 Processor n-1 Cache 1 Cache 0 Cache n-1 NoC NoC examples Lock Engine Timer Centralized Shared Memory Centralized Directory
Hybrid Protocol Implementation • For each memory block: 2 protocols (Invalidation and Update) are possible (Initially: Invalidation) • If the number of misses becomes high : Update protocol. • The update protocol is applied during a certain number of operations (threshold) fixed dynamically: • Threshold: If the degree of sharing the block is important. • Threshold: If the degree of sharing the block is not important.
Hybrid Protocol Implementation • For each memory block: 2 counters are associated • UC (Update Counter) : threshold to switch from Inv to Upd • W (Write Counter) : counts number of invalidations • In case of $ miss: • If W is important : cache misses caused by the invalidation protocol are distant from each other,then UC- - • If W is reduced: cache misses caused by the invalidation protocol are very close to each other,then UC++
Experimental results SoCLib platform • Open platform to model and to simulate MPSoC architectures. • A library of reusable hardware components (IP), C++ (SystemC). • A crossbar is used to connect the processors to shared memory banks. • SocLib has been enhanced by power consumption models for each type of components.
Experimental results Performance comparison : FFT hybrid scheme, mixed shared data(both mostly-read and frequently read-writtenshared data) on a 4 processor 10%gain 10%gain
Experimental results Performance comparison for the FFT application with only mostly-read shared data on a 4 processor-MPSoC 10%gain
Experimental results Performance comparison for the FFT application using only frequently read-written shared data on a 4 processor-MPSoC
Experimental results Performance comparison for the matrix multiplication application Domain decomposition scheme on a 4 processor-MPSoC 20%gain
Bus Overhead reduction for the hybrid protocol • CACTI tool : overhead in terms of required area. • 25% of the shared memory area is used by the proposed protocol. Architecture of the overall system Processor 1 Processor 0 Processor n-1 Cache 1 Cache 0 Cache n-1 NoC Lock Engine Timer Centralized Shared Memory COUNTER ARRAYs & FSM Centralized Directory
Experimental results Energy consumption according to the number of blocks associated to each pair (W and UC) of counter for the MM application with four processors 25% to 7% overhead
Conclusions • A new dynamic hybrid protocol: A hardware solution • Able to adapt automatically to data access patterns at run-time. • Evaluated with an MPSoC centralized shared memory simulation platform with 2 applications FFT and MM. • Our hybrid protocol can significantly reduce both cache misses (Vs invalidation), and unnecessary updates (Vs update). • Proposed protocol may reduce the energy consumption by factors of 10% for the FFT and 20% for the MM.
A Dynamic Hybrid Cache Coherency Protocol for Shared-Memory MPSoC H. Chtioui*, R. Ben Atitallah+, S.Niar+, J.L. Dekeyser++ and M.Abid * *University of Sfax (Tunisia), +University of Valenciennes (France), ++INRIA Lille (France)
A Dynamic Hybrid Cache Coherency Protocol for Shared-Memory MPSoC By Hajer Chtioui, Rabie Ben Atitallah, Smail Niar, Jean-Luc Dekeyser and Mohamed Abid
Dynamic Hybrid Coherency Protocol • Existing hybrid protocols: • Require ++ hardware and software resources & Energy • Limited improvement performance Vs single protocol. • Reason: Inadequacy between the applications requirements and the architecture (protocol). • Hybrid: Many protocols. • Dynamic: On-line. • Adaptive: Able to adapt automatically to data access patterns. • To propose a hardware solution that uses an original architecture (Embedded system).
Architecture of the Cell two instructions per cycle 128-bit operands four 128-bit rings 64-bit PowerPC: 2 threads
a) FSM for a bloc in the directory b) FSM for a bloc in the cache FSM of the hybrid protocol
Experimental results Energy consumption according to the data cache size and the number of processors for hybrid, invalidation and update protocols (FFT application with mixed shared data)