Entity Tables, Relationship Tables
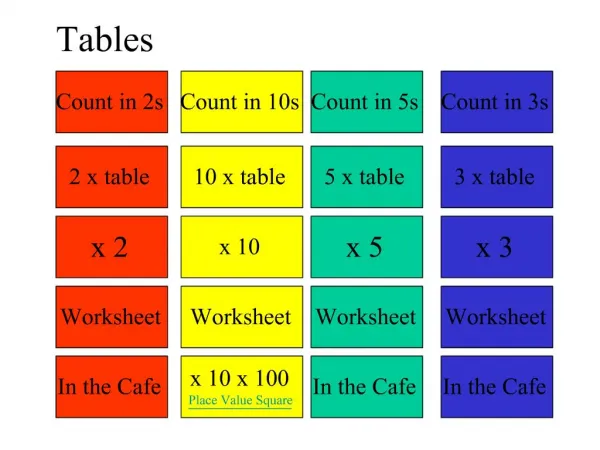
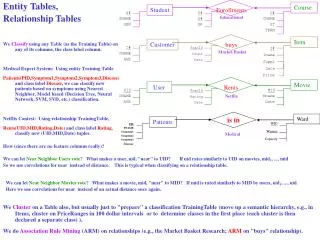
Entity Tables, Relationship Tables. Educational. Market Basket. Netflix. Medical. is in. Ward. Item. Course. Movie. Customer. Patients. Student. User. Rents. Enrollments. buys. Has. WID Wname Capacity. I# Iname Suppl Date Price. MID Mname Date. C#

Entity Tables, Relationship Tables
E N D
Presentation Transcript
Entity Tables, Relationship Tables Educational Market Basket Netflix Medical is in Ward Item Course Movie Customer Patients Student User Rents Enrollments buys Has WID Wname Capacity I# Iname Suppl Date Price MID Mname Date C# CNAME ST TERM C# S# GR TranID Rating Date PID PNAME Symptom1 Symptom2 Symptom3 Disease UID CNAME AGE TranID Count Date C# CNAME AGE S# SNAME GEN We Classify using any Table (as the Training Table) on any of its columns, the class label column. Medical Expert System: Using entity Training Table Patients(PID,Symptom1,Symptom2,Symptom3,Disease) and class label Disease, we can classify new patients based on symptoms using Nearest Neighbor, Model based (Decision Tree, Neural Network, SVM, SVD, etc.) classification. Netflix Contest: Using relationship TrainingTable, Rents(UID,MID,Rating,Date) and class label Rating, classify new (UID,MID,Date) tuples. How (since there are no feature columns really)? We can let Near Neighbor Users vote? What makes a user, uid, "near" to UID? If uid rates similarly to UID on movies, mid1, ..., mid. So we use correlations for near instead of distance. This is typical when classifying on a relationship table. We can let Near Neighbor Movies vote? What makes a movie, mid, "near" to MID? If mid is rated similarly to MID by users, uid1, ..., uid.. Here we use correlations for near instead of an actual distance once again. We Cluster on a Table also, but usually just to "prepare" a classification TrainingTable (move up a semantic hierarchy, e.g., in Items, cluster on PriceRanges in 100 dollar intervals or to determine classes in the first place (each cluster is then declared a separate class) ). We do Association Rule Mining (ARM) on relationships (e.g., the Market Basket Research; ARM on "buys" relationship).
a5 a6a10=Ca11 a12 a13 a14distance from 000000 Workspace for the 3 nearest neighbors so far C=1 wins! distance=3, don’t replace distance=2, don’t replace distance=2, don’t replace distance=3, don’t replace distance=2, don’t replace distance=2, don’t replace distance=4, don’t replace distance=3, don’t replace distance=2, don’t replace distance=3, don’t replace distance=2, don’t replace distance=2, don’t replace distance=4, don’t replace 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 distance=1, replace 0 0 0 0 0 0 WALK THRU a kNN classification example: 3NN CLASSIFICATION of an unclassified sample, a=( a5 a6 a11 a12 a13 a14 ) = =( 0 0 0 0 0 0 ). t12 0 0 1 0 1 1 0 2 t13 0 0 1 0 1 0 0 1 t53 0 0 0 0 1 0 0 1 t15 0 0 1 0 1 0 1 2 0 1 Key a1 a2 a3 a4a5 a6 a7 a8 a9 a10=Ca11 a12 a13 a14 a15 a16 a17 a18 a19 a20 t12 1 0 1 0 0 0 1 1 0 1 0 1 1 0 1 1 0 0 0 1 t13 1 0 1 0 0 0 1 1 0 1 0 1 0 0 1 0 0 0 1 1 t15 1 0 1 0 0 0 1 1 0 1 0 1 0 1 0 0 1 1 0 0 t16 1 0 1 0 0 0 1 1 0 1 1 0 1 0 1 0 0 0 1 0 t21 0 1 1 0 1 1 0 0 0 1 1 0 1 0 0 0 1 1 0 1 t27 0 1 1 0 1 1 0 0 0 1 0 0 1 1 0 0 1 1 0 0 t31 0 1 0 0 1 0 0 0 1 1 1 0 1 0 0 0 1 1 0 1 t32 0 1 0 0 1 0 0 0 1 1 0 1 1 0 1 1 0 0 0 1 t33 0 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 0 0 1 1 t35 0 1 0 0 1 0 0 0 1 1 0 1 0 1 0 0 1 1 0 0 t51 0 1 0 1 0 0 1 1 0 0 1 0 1 0 0 0 1 1 0 1 t53 0 1 0 1 0 0 1 1 0 0 0 1 0 0 1 0 0 0 1 1 t55 0 1 0 1 0 0 1 1 0 0 0 1 0 1 0 0 1 1 0 0 t57 0 1 0 1 0 0 1 1 0 0 0 0 1 1 0 0 1 1 0 0 t61 1 0 1 0 1 0 0 0 1 0 1 0 1 0 0 0 1 1 0 1 t72 0 0 1 1 0 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 t75 0 0 1 1 0 0 1 1 0 0 0 1 0 1 0 0 1 1 0 0
WALK THRU of required 2nd scan to find Closed 3NN set. Does it change vote? 3NN set after 1st scan Unclassified sample: 0 0 0 0 0 0 a5 a6a10=Ca11 a12 a13 a14distance t12 0 0 1 0 1 1 0 2 t13 0 0 1 0 1 0 0 1 t53 0 0 0 0 1 0 0 1 0 1 d=2, include it also d=2, include it also d=2, include it also d=2, include it also d=4, don’t include d=4, don’t include d=3, don’t include d=3, don’t replace d=3, don’t include d=3, don’t include d=2, include it also d=2, include it also d=2, include it also d=2, include it also 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 d=1, already voted d=2, already voted d=1, already voted 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 YES! C=0 wins now! Vote after 1st scan. Key a1 a2 a3 a4a5 a6 a7 a8 a9 a10=Ca11 a12 a13 a14 a15 a16 a17 a18 a19 a20 t12 1 0 1 0 0 0 1 1 0 1 0 1 1 0 1 1 0 0 0 1 t13 1 0 1 0 0 0 1 1 0 1 0 1 0 0 1 0 0 0 1 1 t15 1 0 1 0 0 0 1 1 0 1 0 1 0 1 0 0 1 1 0 0 t16 1 0 1 0 0 0 1 1 0 1 1 0 1 0 1 0 0 0 1 0 t21 0 1 1 0 1 1 0 0 0 1 1 0 1 0 0 0 1 1 0 1 t27 0 1 1 0 1 1 0 0 0 1 0 0 1 1 0 0 1 1 0 0 t31 0 1 0 0 1 0 0 0 1 1 1 0 1 0 0 0 1 1 0 1 t32 0 1 0 0 1 0 0 0 1 1 0 1 1 0 1 1 0 0 0 1 t33 0 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 0 0 1 1 t35 0 1 0 0 1 0 0 0 1 1 0 1 0 1 0 0 1 1 0 0 t51 0 1 0 1 0 0 1 1 0 0 1 0 1 0 0 0 1 1 0 1 t53 0 1 0 1 0 0 1 1 0 0 0 1 0 0 1 0 0 0 1 1 t55 0 1 0 1 0 0 1 1 0 0 0 1 0 1 0 0 1 1 0 0 t57 0 1 0 1 0 0 1 1 0 0 0 0 1 1 0 0 1 1 0 0 t61 1 0 1 0 1 0 0 0 1 0 1 0 1 0 0 0 1 1 0 1 t72 0 0 1 1 0 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 t75 0 0 1 1 0 0 1 1 0 0 0 1 0 1 0 0 1 1 0 0
WALK THRU: C3NN using P-trees First let all training points at distance=0 vote, then distance=1, then distance=2, ... until 3 For distance=0 (exact matches) constructing the P-tree, Ps then AND with PC and PC’ to compute the vote. (black denotescomplement,red denotes uncomplemented a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 No neighbors at distance=0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 C 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 C 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 C 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 Ps 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 a1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0 a4 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a7 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a8 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a9 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 0 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a15 1 1 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 a16 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 a17 0 0 1 0 1 1 1 0 0 1 1 0 1 1 1 0 1 a18 0 0 1 0 1 1 1 0 0 1 1 0 1 1 1 0 1 a19 0 1 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 key t12 t13 t15 t16 t21 t27 t31 t32 t33 t35 t51 t53 t55 t57 t61 t72 t75 a20 1 1 0 0 1 0 1 1 1 0 1 1 0 0 1 1 0 a2 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 a3 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1
Construct Ptree, PS(s,1) = OR Pi = P|si-ti|=1; |sj-tj|=0, ji = ORPS(si,1) S(sj,0) P14 P13 P12 P11 P6 P5 0 1 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 OR WALK THRU: C3NNC distance=1 nbrs: i=5,6,11,12,13,14 i=5,6,11,12,13,14 j{5,6,11,12,13,14}-{i} a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 C 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 C 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 a10 =C 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 PD(s,1) 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0 a4 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a7 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a8 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a9 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 0 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a15 1 1 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 a16 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 a17 0 0 1 0 1 1 1 0 0 1 1 0 1 1 1 0 1 a18 0 0 1 0 1 1 1 0 0 1 1 0 1 1 1 0 1 a19 0 1 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 key t12 t13 t15 t16 t21 t27 t31 t32 t33 t35 t51 t53 t55 t57 t61 t72 t75 a20 1 1 0 0 1 0 1 1 1 0 1 1 0 0 1 1 0 a2 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 a3 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1
OR{all double-dim interval-Ptrees}; PD(s,2) =OR Pi,j Pi,j = PS(si,1) S(sj,1) S(sk,0) i,j{5,6,11,12,13,14} k{5,6,11,12,13,14}-{i,j} 0 1 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 a14 1 1 0 1 1 0 1 1 1 0 1 1 0 0 1 1 0 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 0 1 1 0 0 0 0 0 1 1 0 1 1 0 0 0 1 a13 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a12 0 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 0 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 1 1 1 0 0 1 0 1 1 1 0 1 1 1 0 1 1 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a6 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a5 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 1 1 WALK THRU: C3NNC distance=2 nbrs: We now have the C3NN set and we can declare C=0 the winner! We now have 3 nearest nbrs. We could quite and declare C=1 winner? P5,12 P5,13 P5,14 P6,11 P6,12 P6,13 P6,14 P11,12 P11,13 P11,14 P12,13 P12,14 P13,14 P5,11 P5,6 a10 C 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 a5 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 a6 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 a11 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 a12 1 1 1 0 0 0 0 1 1 1 0 1 1 0 0 1 1 a13 1 0 0 1 1 1 1 1 0 0 1 0 0 1 1 1 0 a14 0 0 1 0 0 1 0 0 0 1 0 0 1 1 0 0 1 key t12 t13 t15 t16 t21 t27 t31 t32 t33 t35 t51 t53 t55 t57 t61 t72 t75
In this example, there were no exact matches (dis=0 nbrs or similarity=6 neighbors) for the sample. There were two nbrs found at a distance of 1 (dis=1 or sim=5) and nine dis=2, sim=4 nbrs. All 11 neighbors got an equal votes even though the two sim=5 are much closer neighbors than the nine sim=4. Also processing for the 9 is costly. A better approach would be to weight each vote by the similarity of the voter to the sample (We will use a vote weight function which is linear in the similarity (admittedly, a better choice would be a function which is Gaussian in the similarity, but, so far, it has been too hard to compute). As long as we are weighting votes by similarity, we might as well also weight attributes by relevance also (assuming some attributes are more relevant than others. e.g., the relevance weight of a feature attribute could be the correlation of that attribute to the class label). P-trees accommodate this method very well (in fact, a variation on this theme won the KDD-cup competition in 02 ( http://www.biostat.wisc.edu/~craven/kddcup/ ) and is published in the so-called Podium Classification methods. Notice though that the Ptree method (Horizontal Processing of Vertical Data or HPVD) really relies on a bonafide distance, in this case Hamming Distance or L1. However, the Vertical Processing of Horizontal Data (VPHD) doesn't. VPHD therefore works even when we use a correlation as the notion of "near". If you have been involve in the DataSURG Netflix Prize efforts, you will note that we used Ptree technology to calculate correlations but not to find near neighbors through correlations.
User Movie Rents MID Mname Date UID CNAME AGE TID Rating Date Netflix Again, Rents is also a Table ( Rents(TID, UID,MID,Rating,Date) ), using the class label column, Rating, we can classify potential new ratings. Using these predicted ratings, we can recommend Rating=5 rentals. Does ARM require a binary relationship? YES! But since every Table gives a binary relationship between any two of its columns we can do ARM on them. E.g., we could do ARM on Patients(symptom1, disease) to try to determine which diseases symptom1 alone implies (with high confidence) AND in some cases, the columns of a Table are really instances of another entity. E.g., Images, e.g., Landsat Satellite Images, LS(R, G, B, NIR, MIR, TIR), with wavelength intervals in micrometers: B=(.45, .52], G=(.52, .60], R=(.63, .69], NIR=(.76, .90], MIR=(2.08, 2.35], TIR=(10.4, 12.5] Known recording instruments (that record the number of photons detected in a small space of time in any a given wavelength range) seem to be very limited in capability (eg, our eyes, CCD cameras...). If we could record all consecutive bands (e.g., of radius .025 µm) then we would have a relationship between pixels (given by latitude-longitude) and wavelengths. Then we could do ARM on Imagery!!!!
e.g., Horizontal Trans TT(I)Table t1 i1 t2 i1, i2, i4 t3 i1, i3 t4 i1, i2, i4 t5 i3, i4 Its graph t1 i1 t2 i2 A t3 i3 t4 i4 C t5 T I Intro to AssociationRule Mining (ARM) Given any relationship between entities, T(e.g., a set of Transactions an enterprise performs) and I(e.g., a set of Items which are acted upon by those transactions). e.g., in Market Basket Research (MBR)the transactions, T, are thecheckout transactions (a customer going thru checkout) and the items, I, are theItems available for purchase in that store. The itemset, T(I),associated with (or related to) a particular transaction, T, is the subset of the items found in the shopping cart or market basket that the customer is bringing through check out at that time). an Association Rule, AC, associates two disjoint subsets of I (called Itemsets). (Ais called theantecedent, C is called theconsequent) The support [set] of itemsetA,supp(A), is the set of of t's that are related to every aA, e.g., if A={i1,i2} and C={i4} then supp(A)={t2, t4} (support ratio = {t2,t4}| / |{t1,t2,t3,t4,t5}| = 2/5 ) Note: | | means set size or count of elements in the set. The support [ratio] of ruleAC, supp(AC),is the support of {A C}=|{t2,t4}|/|{t1,t2,t3,t4,t5}|=2/5 The confidence of ruleAC, conf(AC),is supp(AC) / supp(A) = (2/5) / (2/5) = 1 Data Miners typically want to find all STRONG RULES, AC, with supp(AC) ≥ minsupp and conf(AC) ≥ minconf (minsupp, minconf are threshold levels) Note that conf(AC) is also just the conditional probability of t being related to C, given that t is related to A).
APRIORI Association Rule Mining:Given a Transaction-Item Relationship, the APRIORI algorithm for finding all Strong I-rules can be done: 1. vertically processing of a Horizontal Transaction Table (HTT) or 2. horizontally processing of a Vertical Transaction Table (VTT).In 1., a Horizontal Transaction Table (HTT) is processed through vertical scans to find all FrequentI-sets (I-sets with support minsupp, e.g., I-sets "frequently" found in transaction market baskets).In 2. a Vertical Transaction Table (VTT) is processed thru horizontal operations to find all FrequentI-setsThen each Frequent I-set found is analyzed to determine if it is the support set of a strong rule.Finding all Frequent I-sets is the hard part. To do this efficiently, APRIORI Algorithm takes advantage of the "downward closure" property for Frequent I-sets: If an I-set is frequent, then all its subsets are also frequent.E.g., in the Market Basket Example, If A is an I-subset of B and if all of B is in a given Transaction's basket, the certainly all of A is in that basket too. Therefore Supp(A) Supp(B) whenever AB.First, APRIORI scans to determine all Frequent 1-item I-sets (contain 1 item; therefore called 1-Itemsets),next APRIORI uses downward closure to efficiently find candidates for Frequent 2-Itemsets,next APRIORI scans to determine which of those candidate 2-Itemsets is actually Frequent,next APRIORI uses downward closure to efficiently find candidates for Frequent 3-Itemsets,next APRIORI scans to determine which of those candidate 3-Itemsets is actually Frequent, ...Until there are no candidates remaining (on the next slide we walk through an example using both a HTT and a VTT)
ARMThe relationship between Transactions and Items can be expressed in a 2 1s, 3 2s, 3 3s, 1 4, 3 5s Frequent (supp 2) 2 3 3 1 3 2 3 3 3 1-Iset supports Start by finding Frequent 1-ItemSets. or a Vertical Transaction Table (VTT) Horizontal Transaction Table (HTT) minsupp is set by the querier at 1/2 and minconf at 3/4 (note minsupp and minconf can expressed as counts rather than as ratios. If so, since there are 4 transactions, then as counts, minsupp=2 and minconf=3): (downward closure property of "frequent") Any subset of a frequent itemset is frequent. APRIORI METHOD: Iteratively find the Frequent k-itemsets, k=1,2,... Find all strong association rules supported by each frequent Itemset. (Ck will denote candidate k-itemsets generated at each step. Fk will denote frequent k-itemsets).
F3 = L3 C1 F1 = L1 C2 F2 = L2 C3 C2 ARM itemset Scan D {2 3 5} {1 2 3} {1,3,5} Scan D Scan D P1 2 //\\ 1010 P2 3 //\\ 0111 P1^P2^P3 1 //\\ 0010 Build Ptrees: Scan D P1^P2 1 //\\ 0010 P3 3 //\\ 1110 P1^P3 ^P5 1 //\\ 0010 P1^P3 2 //\\ 1010 P4 1 //\\ 1000 P2^P3 ^P5 2 //\\ 0110 P5 3 //\\ 0111 P1^P5 1 //\\ 0010 L2={13}{23}{25}{35} L1={1}{2}{3}{5} L3={235} P2^P3 2 //\\ 0110 P2^P5 3 //\\ 0111 P3^P5 2 //\\ 0110 HTT {123} pruned since {12} not frequent {135} pruned since {15} not frequent Example ARM using uncompressed Ptrees(note: I have placed the 1-count at the root of each Ptree)
L3 L1 L2 ARM 1-ItemSets don’t support Association Rules (They will have no antecedent or no consequent). 2-Itemsets do support ARs. Are there any Strong Rules supported by Frequent=Large 2-ItemSets(at minconf=.75)? {1,3} conf{1}{3} = supp{1,3}/supp{1} = 2/2 = 1 ≥ .75 STRONG conf{3}{1} = supp{1,3}/supp{3} = 2/3 = .67 < .75 {2,3} conf{2}{3} = supp{2,3}/supp{2} = 2/3 = .67 < .75 conf{3}{2} = supp{2,3}/supp{3} = 2/3 = .67 < .75 {2,5} conf{2}{5} = supp{2,5}/supp{2} = 3/3 = 1 ≥ .75STRONG! conf{5}{2} = supp{2,5}/supp{5} = 3/3 = 1 ≥ .75STRONG! {3,5} conf{3}{5} = supp{3,5}/supp{3} = 2/3 = .67 < .75 conf{5}{3} = supp{3,5}/supp{5} = 2/3 = .67 < .75 Are there any Strong Rules supported by Frequent or Large 3-ItemSets? {2,3,5} conf{2,3}{5} = supp{2,3,5}/supp{2,3} = 2/2 = 1 ≥ .75STRONG! conf{2,5}{3} = supp{2,3,5}/supp{2,5} = 2/3 = .67 < .75 No subset antecedent can yield a strong rule either (i.e., no need to check conf{2}{3,5} or conf{5}{2,3} since both denominators will be at least as large and therefore, both confidences will be at least as low. conf{3,5}{2} = supp{2,3,5}/supp{3,5} = 2/3 = .67 < .75 No need to check conf{3}{2,5} or conf{5}{2,3} DONE!
Collaborative Filteringis the prediction of likes and dislikes (retail or rental) from the history of previous expressed purchase of rental satisfactions (filtering new likes thru the historical filter of “collaborator” likes) E.g., the $1,000,000 Netflix Contestwas to develop aratings prediction program that can beat the one Netflix currently uses (called Cinematch) by 10% in predicting what rating users gave to movies. I.e., predict rating(M,U) where (M,U) QUALIFYING(MovieID, UserID). Netflix uses Cinematch to decide which movies a user will probably like next (based on all past rating history). All ratings are "5-star" ratings (5 is highest. 1 is lowest. Caution: 0 means “did not rate”). Unfortunately rating=0 does not mean that the user "disliked" that movie, but that it wasn't rated at all. Most “ratings” are 0. Therefore, the ratings data sets are NOT vector spaces! One can approach the Netflix contest problem as a data mining Classification/Prediction problem. A "history of ratings given by users to movies“, TRAINING(MovieID, UserID, Rating, Date) is provided, with which to train your predictor, which will predict the ratings given to QUALIFYING movie-user pairs (Netflix knows the rating given to Qualifying pairs, but we don't.) Since the TRAINING is very large, Netflix also provides a “smaller, but representative subset” of TRAINING, PROBE(MovieID, UserID)(~2 orders of magnitude smaller than TRAINING). Netflix gave 5 years to submit QUALIFYING predictions. That contest was won in the late summer of 2009, when the submission window was about 1/2 gone. The Netflix Contest Problem is an example of the Collaborative Filtering Problem which is ubiquitous in the retail business world (How do you filter out what a customer will want to buy or rent next, based on similar customers?).
ARM in Netflix? User Movie Rents MID Mname Date UID CNAME AGE Rating Date ARM used for pattern mining in the Netflix data? In general we look for rating patterns (RP) that have the property RP true ==> MIDr (movie, MID, is rated r). Singleton Homogeneous Rating Patterns: RP = Nr Multiple Homogeneous Rating Patterns: RP = N1r & ... & Nkr Multiple Heterogeneous Rating Patterns: RP = N1r1 & ... & Nkrk