Singular Value Decomposition
This presentation explores Singular Value Decomposition (SVD), a powerful mathematical concept that factorizes matrices into components crucial for various applications in computer science, including image compression and noise filtering. Deriving from foundational theorems, SVD provides insight into matrix properties and optimizes data representation. The discussion includes its practical implications, such as approximating matrices and improving data quality in bioinformatics. Current research directions utilizing SVD span from document retrieval to advanced machine learning applications.


Singular Value Decomposition
E N D
Presentation Transcript
Singular Value Decomposition Jonathan P. Bernick Department of Computer Science Coastal Carolina University
Outline • Derivation • Properties of the SVD • Applications • Research Directions
Matrix Decompositions • Definition: The factorization of a matrix M into two or more matrices M1, M2,…, Mn, such that M = M1M2…Mn. • Many decompositions exist… • QR Decomposition • LU Decomposition • LDU Decomposition • Etc. • One is special…
Theorem One • [Will] For an m by n matrix A:nm and any orthonormal basis {a1,...,an} of n, define (1) si = ||Aai|| (2) Then…
Theorem One (continued) Proof:
Theorem Two • [Will] For an m by n matrix A, there is an orthonormal basis {a1,...,an} of n such that for all i j, Aai Aaj = 0 • Proof: Since ATA is symmetric, the existence of {a1,...,an} is guaranteed by the Spectral Theorem. • Put Theorems One and Two together, and we obtain…
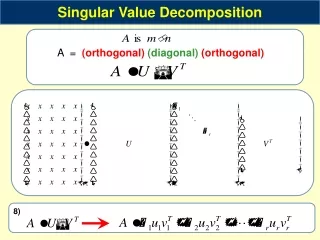
Singular Value Decomposition • [Strang]: Any m by n matrix A may be factored such that A = UVT • U: m by m, orthogonal, columns are the eigenvectors of AAT • V: n by n, orthogonal, columns are the eigenvectors of ATA • : m by n, diagonal, r singular values are the square roots of the eigenvalues of both AAT and ATA
SVD Example • From [Strang]:
SVD Properties • U, V give us orthonormal bases for the subspaces of A: • 1st r columns of U:Column space of A • Last m - r columns of U: Left nullspace of A • 1st r columns of V: Row space of A • 1st n - r columns of V: Nullspace of A • IMPLICATION: Rank(A) = r
Application: Pseudoinverse • Given y = Ax, x = A+y • For square A, A+ = A-1 • For any A… A+ = V-1UT • A+ is called the pseudoinverse of A. • x = A+y is the least-squares solution of y = Ax.
Given an m by n matrix A:nm with singular values {s1,...,sr} and SVD A = UVT, define U = {u1| u2| ... |um} V = {v1| v2| ... |vn}T Then… Rank One Decomposition Amay be expressed as the sum ofr rank one matrices
Matrix Approximation • Let A be an m by n matrix such that Rank(A) = r • If s1s2 ... sr are the singular values of A, then B, rank q approximation of A that minimizes ||A - B||F, is Proof: S. J. Leon, Linear Algebra with Applications, 5th Edition, p. 414 [Will]
Application: Image Compression • Uncompressed m by n pixel image: m×n numbers • Rank q approximation of image: • q singular values • The first q columns of U (m-vectors) • The first q columns of V (n-vectors) • Total: q× (m + n + 1) numbers
Example: Yogi (Uncompressed) • Source: [Will] • Yogi: Rock photographed by Sojourner Mars mission. • 256 × 264 grayscale bitmap 256 × 264 matrix M • Pixel values [0,1] • ~ 67584 numbers
Example: Yogi (Compressed) • M has 256 singular values • Rank 81 approximation of M: • 81 × (256 + 264 + 1) = ~ 42201 numbers
Application: Noise Filtering • Data compression: Image degraded to reduce size • Noise Filtering: Lower-rank approximation used to improve data. • Noise effects primarily manifest in terms corresponding to smaller singular values. • Setting these singular values to zero removes noise effects.
Example: Microarrays • Source: [Holter] • Expression profiles for yeast cell cycle data from characteristic nodes (singular values). • 14 characteristic nodes • Left to right: Microarrays for 1, 2, 3, 4, 5, all characteristic nodes, respectively.
Research Directions • Latent Semantic Indexing [Berry] • SVD used to approximate document retrieval matrices. • Pseudoinverse • Applications to bioinformatics via Support Vector Machines and microarrays.
References • [Berry]: Michael W. Berry, et. al., “Using Linear Algebra for Intelligent Information Retrieval,” CS 94-270, Department of Computer Science, University of Tennessee, 1994. Submitted to SIAM Review. • [Holter]: Neal S. Holter, et. al., “Fundamental patterns underlying gene expression profiles: Simplicity from complexity,” Proc. Natl. Acad. Sci. USA, 10.1073/pnas. 150242097, 2000 (preprint). Available online at www.pnas.org/doi/10.1073/pnas.150242097
References (continued) • [Strang]: Gilbert Strang, Linear Algebra and Its Applications, 3rd edition, Academic Press, Inc., New York, 1988. • [Will]: Todd Will, “Introduction to the Singular Value Decomposition,” Davidson College, http://www.davidson.edu/math/will/svd/index.html
Full Presentation Text http://www.coastal.edu/~jbernick/ Comments Welcome!