ASR Front End Processing
ASR Front End Processing. Implemented on Texas Instruments OMAP-L137 Jacob Zurasky – 12/12/11. Project Goals. Create a front-end for embedded ASR Extract feature vectors from speech data Allow for many different specifications


ASR Front End Processing
E N D
Presentation Transcript
ASR Front End Processing Implemented on Texas Instruments OMAP-L137 Jacob Zurasky – 12/12/11
Project Goals • Create a front-end for embedded ASR • Extract feature vectors from speech data • Allow for many different specifications • Extract features real-time, while allowing enough CPU time for analysis
Hardware Platform • Texas Instruments OMAP – L137 DSP, dual core • TMS320C6747 • ARM9 • AIC3106 Audio Codec • 64MB SDRAM
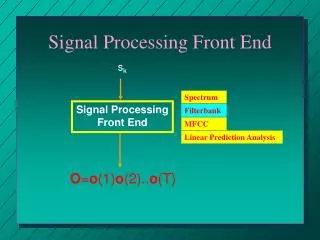
Signal Flow Block Diagram Audio Framing Pre-Emphasis Window FFT Mel Filter Log DCT Deltas 13 - MFCCs 13 - Deltas 13 - Delta Deltas
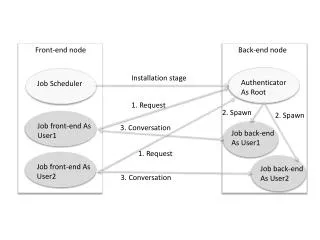
Data Streams • Streams are a way to transfer blocks of data efficiently • Uses enhanced direct memory access (EDMA) • Block of data can be accessed by SIO_reclaim(…) • Block of data can be sent by SIO_issue(…) Input Stream DSP Audio Codec Output Stream
Stream Example • After SIO_reclaim, pIn points to input data and pOut points to output data • After SIO_issue, those buffers are reused by the audio codec
Pre-Emphasis • y[n] = x[n] – ax[n-1] • First order high-pass filter • Used to compensate for the higher frequency roll-off in human speech production
Windowing Function • Rectangular, Hann, Hamming, Cosine, Gaussian… Hamming Window
FFT • Magnitude of Frequency Spectrum • Texas Instrument’s DSPLIB for C67x
Mel Filter • Triangular Bandpass Filters along Mel Frequency Scale • Mimics the logarithmic nature of human hearing
Discrete Cosine Transform (DCT) • Transforms back from frequency domain • Typically first 12 values are used as the Mel Frequency Cepstral Coefficients • Look-up table for efficiency
Deltas • Produce 13 MFCC’s per frame • 13 more from the first derivative • 13 additional from the second derivative • 39 dimensional vector to represent the current frame
Observations • Pre-Emphasis and Windowing an input frame Input Frame Pre-Emphasis and Windowed Frame
Observations • FFT and Log, Mel Filter Magnitude of Frequency Spectrum Log, Mel Filtered Spectrum
Observations • Discrete Cosine Transform to produce MFCC’s Mel Frequency Cepstral Coefficients Full Feature Vector for 1 frame
Observations • Frame Size = 256 samples @ 16 kHz Fs • 1 Frame = 16 mS • Feature Extraction Time • Debug – 1.55 mS • Release – 0.25 mS • Real Time Feature Extraction • 0.25 mS / 16 mS = 1.56% usuage
Future Goals • Complete training code for DSP • Load training data to SDRAM • DSP calculates all feature vectors associated with a given phone • Calculates Gaussian mixture model • Save acoustic model off-chip • Evaluate the acoustic model (digital recognition) • Complete embedded ASR on limited vocabulary