Membrane: Operating System Support for Restartable File Systems
The Membrane framework introduces a lightweight, transparent mechanism for supporting restartable file systems. By detecting faults and rolling back to the last trusted state, it allows file systems to continue handling requests seamlessly without user awareness of underlying faults. Membrane effectively addresses transient and fail-stop faults, although some file system bugs could still potentially corrupt kernel states. Our research evaluates fault detection and recovery methods, demonstrating that Membrane significantly reduces recovery time and enhances system resilience against file system failures.


Membrane: Operating System Support for Restartable File Systems
E N D
Presentation Transcript
Membrane: Operating System Support for Restartable File Systems Swaminathan Sundararaman, Sriram Subramanian, Abhishek Rajimwale, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, Michael M. Swift Computer Sciences Department, University of Wisconsin, Madison FAST 10 Speaker: T.C Huang 15/Mar/10
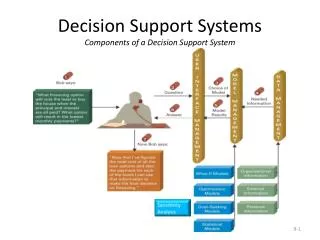
Membrane Recover file system state in following fashion • Lightweight • Transparent • User will not be aware of FS fault • FS restart and continue handling to request
STEP • File system detects a fault • Membrane rollback the FS state to last checkpoint (last trusted state) • Replay FS writes that occurred after checkpoint • Release kernel lock, free allocated memory • Proceed later requests without fault
Fault Model • Membrane does NOT to handle all fault types • Best handle • Transient : race condition / bit flip • Fail-Stop : BUG() • Bad handle – wild write
The major drawback of membrane is that the boundary we use is soft: some file system bugs can still corrupt kernel state outside the file system and recovery will not succeed.
Fault Detection • Hardware : hardware detectable faults • e.g. divide-by-zero, null pointer… • check faulting instruction handler • Software 1: Use existed checks in FS code • Re-define panic() / BUG() / assert() in FS code forward Membrane recovery code • Software 2: • add parameter check on any call from FS into kernel
Fault Anticipation • Checkpoint • divide FS operations into epochs ( or transactions) • ensure on-disk checkpoint image is consistent • State Tracking • Track all updates / lock / states • log to in-memory log and parallel stacks
Checkpointing • checkpoint is a consistent FS state • No operations are in-flight • For Journaling FS / shadow-paging FS • Use in-built checkpoint • For others, build a generic checkpoint mechanism at VFS layer
Tracking State with Log/Stack Track all changes after checkpoint • FS operations log • write, read, unlink, attribute change… • Application-visible session log • file ID, file position, open epoch number, …
Tracking State with Log/Stack • Mallocs table • Add a new GFP_RESTARTABLE to mem-alloc layer recognization • Lock stack • Modified lock functions to track • Only global locks are saved • Execution state stack • also called unwind stack • function calls , registers… • wrap all calls from kernel to FS to save information
Fault Recovery • Halt in-flight threads and park incoming / in-flight threads • mark all code pages of FS as non-executable • code pages of FS are recorded when FS registration • all threads involves in FS will trap into faults • Unwind in-flight threads • use execution state stack • skip/trust unwind protocol • also unlock related locks by referencing lock stack • Commit dirty pages of previous epoch to storage • only ext2/VFAT or other simple FSs
Fault Recovery • Unmount file system • free memory by referencing memalloc table • Remount file system • Roll-forward • use VFS interface • restore active session information by referencing session log • replay FS operations in FS operations log • Restart execution • wake up all parked threads
AMD 2.2GHz CPU 2 x 80GB disks 2GB memory Linux 2.6.15 Ext2 , VFAT Ext3 with full data journaling Evaluation
How Detect? • o : kernel oops • G : general protection fault • i : invalid opcode • d : fault detected • Application? • : keep working • X : killed by OS • s : operation fault only • e : application return fault • Footnotes • a : FS usable, but can’t unmount • b : late oops or fault
Fault Studies • 91% faults incurs kernel oops • 1/3 cases need reboot and fsck • Parameter check (boundary) catches faults but FS can not handle returned error code properly • With Menbrane, faults can be detected and applications didn’t notice faults
Recovery Time • when data=0, open session=0, log record=0, recovery time= 8.6ms
Conclusions • File systems fail frequently (?) • Membrane transforms file system failure from a show-stopping event into a small performance issue.
How Detect? • o : kernel oops • G : general protection fault • i : invalid opcode • d : fault detected • Application? • : keep working • X : killed by OS • s : operation fault only • e : application return fault • Footnotes • a : FS usable, but can’t unmount • b : late oops or fault
How Detect? • o : kernel oops • G : general protection fault • i : invalid opcode • d : fault detected • Application? • : keep working • X : killed by OS • s : operation fault only • e : application return fault • Footnotes • a : FS usable, but can’t unmount • b : late oops or fault