Download

1 / 54
540 likes | 669 Vues
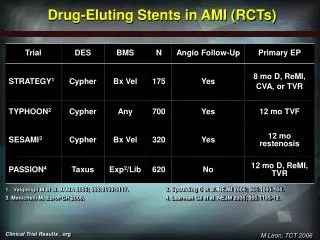
Baseline Measurements in RCTs. To adjust or not to adjust, that is the question. The first table of the results section of most journal articles contains a summary of baseline characteristics as below: Group 1 Group 2 p N per group 25 25 Age (mean) 38.4 41.2 .24

E N D
Baseline Measurements in RCTs To adjust or not to adjust, that is the question
The first table of the results section of most journal articles contains a summary of baseline characteristics as below: Group 1 Group 2 p N per group 25 25 Age (mean) 38.4 41.2 .24 Sex (% male) 72% 64% .55 hemoglobin (g/ml) 103.4 104.8 .81 Hypertension 56% 24% .02 Previous MI 48% 24% .08
Assuming that this is a randomized trial, what is the question that the p-value are answering now? Are they useful? In a randomized experiment, we know: 1. Outcome differences that occur may occur by chance or because there is a true difference between treatments. 2. Baseline differences that occur must occur by chance or because someone has been “fiddling” with the randomization process.
What is the point of determining the probability that the difference occurred by chance when we know it occurred by chance? The only time this might be useful would be when we suspect that somebody has been cheating and not randomizing fairly. If randomizing has been fair, are the p-values of any usefulness?
No, not really. Why not? Because with very large sample sizes, inconsequential differences between treatments may be statistically significant. At the same time, with very small sample sizes, large differences at baseline may not be statistically significant but may have a huge bearing on the outcome.
In the previous example, there was double the proportion of patients with previous MI in one group than the other , but the difference was not significant. What should one look at in the baseline table? The magnitude of the difference between treatment groups on variables known or highly suspected of being related to the outcome of interest.
What if there is a large difference on a variable not related to outcome? It will not have any impact on the result of the trial.
Example: Variable highly correlated with outcome: Rate of MI or Cardiac Death Previous MI: 50% No previous MI: 25% Treatment 1 Treatment 2 Previous MI N=80 N=40 No previous MI N=20 N=60
Number of Poor Outcomes Expected: Treatment 1 Treatment 2 Previous MI 80X.5=40 40X.5=20 No previous MI 20X.25=5 60X.25=15 Total Poor Outcomes Expected: 40+5=45 20+15=35
Example: Variable not correlated with outcome: Rate of MI or Cardiac Death Sex= Male: 50% Sex=Female: 50% Treatment 1 Treatment 2 Male N=80 N=40 Female N=20 N=60
Number of Poor Outcomes Expected: Treatment 1 Treatment 2 Male 80X.5=40 40X.5=20 Female 20X.5=10 60X.5=30 Total Poor Outcomes Expected: 40+10=50 20+30=50
Baseline Characteristics p-values on baseline characteristics indicate only whether randomization worked - one expects that one of every 20 characteristics will have a p <.05. Lack of balance on baseline characteristics is only important if those characteristics are associated with outcome.
Failure to reach statistically significant differences on baseline characteristics does not assure one that there is lack of confounding. In small studies, the power to detect significant differences is low. More attention should be paid to the size and distribution of the difference rather than the p-value.
If one is concerned about important baseline characteristics, then an adjusted analysis should be planned and implemented whether or not significant baseline differences between treatments occur. Adjustment for important baseline characteristics will result in improved precision and power even when there is perfect balance on such factors. Adjustment for factors unassociated with outcome will decrease power very slightly.
RCTs with Survival Outcomes • How does adjustment for important baseline covariates affect power?
RCTs with Survival Outcomes • How does adjustment for important baseline covariates affect power? • Hernandez et al (Annals Epi 2006)
RCTs with Survival Outcomes • Varied predictive effect of covariate, covariate prevalence as well as treatment effect
Modeling no Treatment Effect • Adjustment for covariate did not affect type 1 error
Modeling Treatment Effect (hi prev cov) • For hazard ratio on treatment of 1.4 and 1.7, adjusting for a moderate covariate effect (HR=2) reduced sample size by 15% • For hazard ratio on treatment of 1.4 and 1.7, adjusting for a strong covariate effect (HR=5) reduced sample size by 45%
Modeling Treatment Effect (low prev cov) • For hazard ratio on treatment of 1.4 and 1.7, adjusting for a moderate covariate effect (HR=2) reduced sample size by 4% • For hazard ratio on treatment of 1.4 and 1.7, adjusting for a strong covariate effect (HR=5) reduced sample size by 12%
Conclusions • Adjustment for covariates results in increased power without effect on type 1 error
Covariate adjustment with binary outcomes (logistic regression) in RCTs (Hernandez, JCE, 2004) • Varied treatment effects, covariate effects, outcome incidences, and covariate prevalences
1. Type 1 error unaffected for adjustment • 2. Adjustment for non-predictive covariate has a trivial negative effect on sample size
3. For a strong covariate (OR=5), covariate prevalence = 50%, adjustment decreases sample size by 13%; for a very strong covariate (OR=30), adjustment decreases sample size by 45% for both weak (OR=1.4) and moderate (OR=1.7) treatment effects
4. As covariate prevalence decreases, sample size savings decrease: • Prevalence Savings • 50% 13% • 25% 10% • 12.5% 6%
Conclusion • Adjustment results in greater power without a negative effect on type 1 error • Simulations used a single covariate; savings are potentially greater with multiple important predictors
Sample size with continuous outcomes: What is the best way to deal with baseline measurements? Alternatives: • Ignore 2. Subtract (differences) 3. Regression
Let’s examine the relationship between the estimates of variance using different strategies
The difference between two groups (parallel design) The variance of the difference is equal the sum of the variances for each group.
Assuming that variance is homogeneous (ie same in both groups), this means that the variance of the difference is twice the variance of the individual groups.
In addition, if one takes two measurements on a group of individuals and calculates the variance of the difference between the first and second measurements, the variance will depend on the correlation between the two measures.
If they are completely independent (correlation=0), then the variance will be the same as if one were assessing the variance of the difference between two independent groups, i.e. as above the variance of the difference is equal to twice the variance of the individual time points.
However, if there is a correlation (r) between the two time points s2difference= s2time 1+s2time 2_-2r(stime 1 X stime 2) Using these facts as a basis, one can determine the relative size of the variance for the three different designs, and hence determine relative sample sizes. Assumption: Variance is homogeneous across treatments and time.
Parallel Design (Final Scores Only) s2total=s2group1+s2group 2=2s2group 1
ParallelDesign (Change from Baseline: Group 1 vs Group 2) For group 1: s2diff=s2baseline+ s2followup - 2rsbaselinesfollowup For group 2: s2diff=s2baseline+ s2followup - 2rsbaselinesfollowup
For a comparison of change from baseline in group 1 vs group 2: Simply add the two together. Assuming s2baseline=s2followup The sum is equivalent to: (1_r) 4s2
Now let's compare the two designs: Parallel groups final scores: 2s2 Parallel groups (change scores): (1_r) 4s2
Parallel groups final scores: 2s2 Parallel groups (change scores): (1_r) 4s2 If r = .5, then the variance of the change scores will be equal the variance than the final scores. If r > .5, then the variance of the change scores will be less than the variance than the final scores.
Parallel groups (change scores): (1_r) 4s2 If r > .5, then the variance of the change scores will be less than the variance than the final scores.
The use of change scores in the parallel group design can be used to help control variance and decrease sample size when the correlation between pre and post scores are high.
This should be the case when the study group is relatively heterogeneous (i.e. high variability between subjects) at baseline on the measurement of interest. The variance will be even more tightly controlled if one uses analysis of covariance.
What are we assuming when we use change scores? Less variance in the change score than in the final scores? Why this assumption? If the study sample is relatively heterogeneous at baseline, expect significant variance in final scores. On the other hand, the amount of change might be relatively homogeneous, i.e. patients at various levels might experience similar change.
Example: Initial Final Change 10 20 10 10 20 10 10 20 10 15 25 10 15 25 10 15 25 10 20 30 10 20 30 10 20 30 10
If the final score were used, there would be quite a bit of variability, but if the change score were used, there would be little variability. • We use our knowledge of the initial score to predict the patients’ final scores • In fact, it is unusual for change scores to be unrelated to baseline scores
In other words, the amount of change often is influenced by patients’ scores at baseline
Other alternatives? The change score approach assumes that the best equation explaining the relationship between the final score (Y) and the initial score (X) is of the form; Y= a + X Where a = some constant amount.
In the previous example, the final score was predicted by the equation: Final score = 10 + 1*Initial Score
It is often the case that the amount of change expected varies depending on the initial score especially when it involves a variable that is variable measured with considerable error • The highest scores probably reflect random variation above the true score, and lower scores reflect random variation below the true scores. • Thus, we expect greater change in the lower scores.
Y X
Solution: Analysis of covariance Fits the best linear relationship between initial score and final score • Limitations: If comparing two groups, analysis of covariance makes the assumption that the coefficient of X (i.e. the slope of the line) is the same for the two treatment groups. • If not, ANCOVA should not be used.