Call For Tender Discovery
Call For Tender Discovery. Zhen Zheng. IR on the Web Crawlers parallel crawler intelligent crawler Domain Specific Web Searching (CFT.) Development tools References. IR on the Web CFT. = Tenders search on the web = IR on the Web. Query. Search & match. Indexed


Call For Tender Discovery
E N D
Presentation Transcript
Call For Tender Discovery Zhen Zheng
IR on the Web Crawlers parallel crawler intelligent crawler Domain Specific Web Searching (CFT.) Development tools References
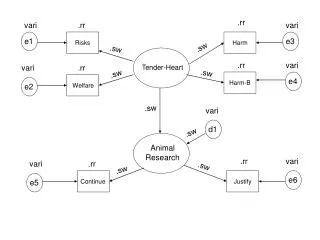
IR on the Web CFT. = Tenders search on the web = IR on the Web Query Search & match Indexed files Query Processor Page ranking Document Processor Responses Browse Web Crawlers Web pages
parallel crawler • Partitioning the Web partition function, crawling modes • Evaluation Metrics overlap, coverage,communication overhead
intelligent crawler [2] • Best-first crawling • Focused crawling is best ie. Only tender related sites/pages • Based on Linkage locality • Based on sibling locality • Based on URL tokens ie. www.city.kingston.on.ca/cityhall /tenders/index.asp www.orangeville.org/tenders.phpwww.tenderscancada.com contactscanada.gc.ca/en/tender-e.htm etc. • Based on html tag, like title,meta • Based on web page content • Based onpage score ….
Domain Specific Web Searching [1] Features: • Easy to apply to heuristic search • Use meta search engine • Implement on the fly • Collaborative,parallel search • Apply to intelligent, agent technologies etc. • Reduce the storage of downloaded web pages • Objective:find complete possibility
Domain Specific Web Searching (CFT.) For tenders: • Use meta search engine at first, ie. Google API,Yahoo,MSN etc. • Geographic category, such as “ ** city tenders” • Use “Search” when crawling • Refine keyword ie, tender,tenders, city tenders etc. • Auto-fill form • Authority page • Hub page
Search Form? URLs Start Crawling Prototype: Query /Seed URL yes No Weight & Order Focus Crawling URLs
Why fill search form first? • Fast • Directly Most general web sites provide search function. Such as: yahoo, google, msn, altavista … www.stjohns.ca; www.cityofkingston.ca; http://www.city.whitehorse.yk.ca …
Why focus crawling? • Accurate • Complete Shrink query response ---> filter ---> accurate Enlarge query terms ---> query modification ---> complete classification[5] [6] hyperlink analysis[7] For example: www.merx.ca
Discuss • Data page • Hub page Data page: term frequency, compond terms frequency. such as: tender, tender / closing date … Hub page(assume): 1) outbound links > 10 2) links/string tokens > 5% 3) language anchor text, as English , Français • Snapshot next page
Development tools • HTMLParser (v 1.4) A super-fast real-time parser for real-world HTML, simplicity in design, speed and ability to handle streaming real-world html. Parser,Scanner,FormTag, InputTag etc. open source. • Google API Create a Google API Account, get your Google Web APIs license key,1000 queries per day, top 10 results per query. Don’t provides ‘link:’ function. • Httpunit The center of HttpUnit is the Web Conversation class, which takes the place of a browser talking to a single site. WebConversation, WebResponse, WebLink, WebTable, WebForm etc. open source.
Development tools • Lucene Jarkarta Lucene is a high-performance, full-featured, java, open source, text search engine API. Document, Field, IndexWriter, file-based or RAM-based Directory, Analyzers, Query, QueryParser, IndexSearcher, Hits etc. • Websphinx It isa Java class library and interactive development environment for web crawlers. It consists of the Crawler Workbench and the WebSPHINX class library. It is intended more for personal use, to crawl perhaps only hundreds of web pages otherwise it can use up memory quickly. Because, it retains all the pages and links that it has crawled until you clear the crawler.
Development tools • Swish-e Swish-e is Simple Web Indexing System for Humans - Enhanced It is a search engine written by perl, efficient and fast. • JavaCC-htmlparer (Quiotix Corporation) This is a JavaCC grammar for parsing HTML documents. The parser transforms an input stream into a parse tree; the elements of the parse tree are defined in HtmlDocument. You can then traverse the tree using the Visitor pattern, like HtmlVisistor, HtmlDumper, HtmlCollector,HtmlScruber.
References [1] “A Method for Indexing Web Pages Using Web Bots” byBoleslaw K. Szymanski and Ming-Shu Chung, January 2002 Department of Computer Science Rensselaer Polytechnic Institute, Troy, N.Y. 12180-3590, USA [2] “ Intelligent Crawling on the World Wide Web with Arbitrary Predicates” byCharu C. Aggarwal, Fatima Al-Garawi & Philip S.Yu, IBM T.J. Watson Resch. Ctr Yorktown Heights,NY 10598 , www10 May 1-5,2001,HongKong. ACM 1-58113-348-0/01/0005 [3] “Extracting Logical Schema from the Web” by Vincenza Carchiolo et al, University of Catania Applied Intelligence 18,341-355,2003 [4] “ Web Search – Your Way” by J.Glover Steve Lawrence et al. NEC Research Institute 4 Independence Way Princeton, NJ 08540
[5] “ Improving Catergory Specific Web Search by Learning Query Modifications” By Eric J. Glover Gary W. Flake et al. NEC Research Institute, EECS Department University of Michigan • [6] “ Web Search Using Automatic Classification” By Chandra Chekuri, Prabhakar Raghavan et al. Computer Science Department, Stanford university; IBM Almaden Research Center • [7] “ Enhanced hypertext categorization using hyperlinks” By Soumen Chakrabarti, Byron Dom, Piotr Indyk. IBM Almaden Research Center ; Computer Science Department, Stanford university
-- Linkage locality -- Sibling locality • In practice, suppose we have pagexyz.html, we can use google find its parent pages withlink:xyz.html, then we can find xyz’s sibling pages following the links within its parent pages. topic X X topicZ topicZ X ... topicZ Y Y Z ? Z ? Y