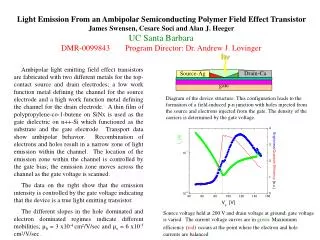
Maximizing Patent Annotation: Techniques, Benefits & Challenges
E N D
Presentation Transcript
Patent Processing with GATE Kalina Bontcheva, Valentin TablanUniversity of Sheffield
Outline • Why patent annotation? • The data model • The annotation guidelines • Building the IE pipeline • Evaluation • Scaling up and optimisation • Find the needle in the annotation (hay)stack GATE Summer School - July 27-31, 2009
What is Semantic Annotation? • Semantic Annotation: • Is about attaching tags and/or ontology classes to text segments; • Creates a richer data space and can allow conceptual search; • Suitable for high-value content • Can be: • Fully automatic, semi-automatic, manual • Social • Learned GATE Summer School - July 27-31, 2009
Semantic Annotation GATE Summer School - July 27-31, 2009
Why annotate patents? • Simple text search works well for the Web, but, • patent searchers require high recall (web search requires high precision); • patents don't contain hyperlinks; • patent searchers need richer semantics than offered by simple text search; • patent text amenable to HLT due to regularities and sub-language effects. GATE Summer School - July 27-31, 2009
How can annotation help? • Format irregularities • “Fig. 3”, “FIG 3”, “Figure 3”, etc. • Data normalisation • “Figures. 3 to 5” -> FIG. 2, FIG 4, FIG 5. • “23rd Oct 1998” -> 19981023 • Text mining – discovery of: • product names and materials; • references to other patents, publications and prior art; • measurements. • etc. GATE Summer School - July 27-31, 2009
Manual vs. Automatic • Manual SA • high quality • very expensive • requires small data or many users (e.g flickr, del.icio.us). • Automatic SA • inexpensive • medium quality • can only do simple tasks • Patent data • too large to annotate manually • too difficult to annotate fully automatically GATE Summer School - July 27-31, 2009
The SAM Projects • Collaboration between Matrixware, Sheffield GATE team, and Ontotext • Started in 2007 and ongoing • Pilot study for applicability of Semantic Annotation to patents • GATE Teamware: Infrastructure for collaborative semantic annotation • Large scale experiments • Mimir: Large scale indexing infrastructure supporting hybrid search (text, annotations, meaning) GATE Summer School - July 27-31, 2009
Technologies Data Enrichment (Semantic Annotation) Knowledge Management Data Access (Search/Browsing) Teamware KIM Large Scale Hybrid Index GATE OWLIM GATE OWLIM GATE ORDI JBPM, etc… TRREE Lucene, etc… TRREE MG4J, etc… TRREE Sheffield Ontotext Other GATE Summer School - July 27-31, 2009
Teamware revisited: A Key SAM Infrastructure Collaborative Semantic Annotation Environment • Tools for semi-automatic annotation; • Scalable distributed text analytics processing; • Data curation; • User/role management; • Web-based user interface. GATE Summer School - July 27-31, 2009
Semantic Annotation Experiments Wide Annotation • Cover a range of generally useful concepts: Documents, document parts, references • High level detail. Deep Annotation • Cover a narrow range of concepts Measurements • As much detail as possible. GATE Summer School - July 27-31, 2009
Data Model GATE Summer School - July 27-31, 2009
Example Bibliographic Data GATE Summer School - July 27-31, 2009
Example measurements GATE Summer School - July 27-31, 2009
Example References GATE Summer School - July 27-31, 2009
The Patent Annotation Guidelines • 11 pages (10 point font), with concrete examples, general rules, specific guidelines per type, lists of exceptions, etc. • The section on annotating measurements is 2 pages long! • The clearer the guidelines – the better Inter-Annotator Agreement you’re likely to achieve • The higher the IAA – the better automatic results can be obtained (less noise!) • The lengthier the annotations – the more scope for error there is, e.g., references to other papers had the lowest IAA GATE Summer School - July 27-31, 2009
Annotating Scalar Measurements • numeric value including formulae • always related to a unit • more than one value can be related to the same unit • ... [80]% of them measure less than [6] um [2] ... • [2x10 -7] Torr • [29G×½]” needle • [3], [5], [6] cm • turbulence intensity may be greater than [0.055], [0.06] ...
Annotating Measurement Units • including compound unit • always related to at least one scalarValue • do not include a final dot • %, :, / should be annotated as unit • deposition rates up to 20 [nm/sec] • a fatigue life of 400 MM [cycles] • ratio is approximately 9[:]7
Annotation Schemas: Measurements Example <?xml version="1.0"?> <schema xmlns="http://www.w3.org/2000/10/XMLSchema"> <element name="Measurement"> <complexType> <attribute name="type" use="required"> <simpleType> <restriction base="string"> <enumeration value="scalarValue"/> <enumeration value="unit"/> </restriction> </simpleType> </attribute> <attribute name="requires-attention" use="optional"> <simpleType> <restriction base="string"> <enumeration value="true"/> <enumeration value="false"/> </restriction> </simpleType> </attribute>
The IE Pipeline • JAPE Rules vs Machine Learning • Moving the goal posts: dealing with unstable annotation guidelines • JAPE – just change a few rules hopefully • ML – could require significant manual re-annotation effort of the training data • Bootstrapping training data creation with JAPE patterns – significantly reduces the manual effort • For ML to be successful, we need IAA to be as high as possible – noisy data problem otherwise • Insufficient training data initially, so chose JAPE approach GATE Summer School - July 27-31, 2009
Example JAPEs for References Macro: FIGNUMBER //Numbers 3, 45, also 3a, 3b ( {Token.kind == "number"} ({Token.length == "1",Token.kind == "word"})? ) Rule:IgnoreFigRefsIfThere Priority: 1000 ( {Reference.type == "Figure"} )--> {} Rule:FindFigRefs Priority: 50 ( ( ({Token.root == "figure"} | {Token.root == "fig"}) ({Token.string == "."})? ((FIGNUMBER) | (FIGNUMBERBRACKETS) ):number ):figref )--> :figref.Reference = {type = "Figure", id = :number.Token.string} GATE Summer School - July 27-31, 2009
Example Rule for Measurements Rule: SimpleMeasure /* * Number followed by a unit. */ ( ({Token.kind == "number"}) ):amount ({Lookup.majorType == "unit"}):unit --> :amount.Measurement = {type = scalarValue, rule = "measurement.SimpleMeasure"}, :unit.Measurement = {type = unit, rule = "measurement.SimpleMeasure"} GATE Summer School - July 27-31, 2009
The IE Annotation Pipeline GATE Summer School - July 27-31, 2009
Hands-on: Identify More Patterns • Open Teamware and login • Find corpus patents-sample • Run ANNIC to identify some patterns for references to tables and figures and measurements • There are already POS tags, Lookup annotations, morphological ones • Units for measurements are Lookup.majorType == “unit” GATE Summer School - July 27-31, 2009
The Teamware Annotation Project • Iterated between JAPE grammar development, manual annotation for gold-standard creation, measuring IAA and precision/recall for JAPE improvements • Initially gold standard doubly annotated until good IAA is obtained, then moved to 1 annotator per document • Had 15 annotators working at the same time GATE Summer School - July 27-31, 2009
Measuring IAA with Teamware • Open Teamware • Find corpus patents-double-annotation • Measure IAA with the respective tool • Analyse the disagreements with the AnnDiff tool GATE Summer School - July 27-31, 2009
Producing the Gold Standard • Selected patents from two very different fields: mechanical engineering and biomedical technology • 51 patents, 2.5 million characters • 15 annotators, 1 curator reconciling the differences GATE Summer School - July 27-31, 2009
The Evaluation Gold Standard GATE Summer School - July 27-31, 2009
Preliminary Results GATE Summer School - July 27-31, 2009
Running GATE Apps on Millions of Documents • Processed 1.3 million patents in 6 days with 12 parallel processes. • Data sets from Matrixware: • American patents (USPTO): 1.3 million, 108 GB, average file size - 85KB. • European patents (EPO): 27 thousand, 780MB, average file size - 29KB. GATE Summer School - July 27-31, 2009
Large-scale Parallel IE • Our experiments were carried out on the IRF’s supercomputer with Java (jrockit-R27.4.0-jdk1.5.0 12) with up to 12 processes • SGI Altix 4700 system comprising 20 nodes each with four 1.4GHz Itanium cores and 18GB RAM • In comparison, we found it 4x faster on Intel Core 2 2.4GHz GATE Summer School - July 27-31, 2009
Large-Scale, Parallel IE (2) • GATE Cloud (A3): dispatches documents to process in parallel; does not stop on error • Ongoing project, moving towards Hadoop • Contact Hamish for further details • Benchmarking facilities: generate time stamps for each resource and display charts from them • Help optimising the IE pipelines, esp. JAPE rules • Doubled the speed of the patent processing pipeline • For a similar third-party GATE-based application we achieved a 10-fold improvement GATE Summer School - July 27-31, 2009
Optimisation Results GATE Summer School - July 27-31, 2009
MIMIR: Accessing the Text and the Semantic Annotations • Documents: 981,315 • Tokens: 7,228,889,715 (> 7 billion) • Distinct tokens: 18,539,315 (> 18m) • Annotation occurrences: 151,775,533 (> 151m) GATE Summer School - July 27-31, 2009