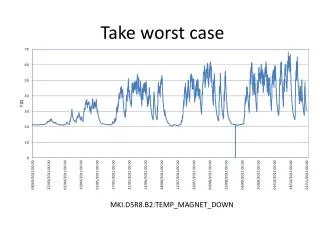
Figure 5.4. Worst case execution of the resilient termination protocol
90 likes | 237 Vues
Figure 5.4. Worst case execution of the resilient termination protocol.

Figure 5.4. Worst case execution of the resilient termination protocol
E N D
Presentation Transcript
Figure 5.4. Worst case execution of the resilient termination protocol Termination and Recovery
The second issue can lead to very subtle problems. Again, consider the scenario where Site 1 sends a committable message to Site 2 and then crashes. Site 2 sends out non-committable messages, receives the committable message from Site 1, commits, and then promptly fails. Now, Site 3 receives a single non-committable message (from Site 2). Let us assume that Site 3 was not aware that Site 1 was up at the beginning of the protocol (a reasonable assumption). Then, Site 3 would not suspect that messages it received were inconsistent with those received by Site 2, and it would make an inconsistent commit decision2. Termination and Recovery
Aborted On the other hand, it is always safe to commit the transaction during a round of “committable” messages, even when additional site failures are detected, because in a progressive protocol an operational site in a committable state never moves to a non-committable state. Therefore, a failed site can never influence its committable cohorts. The protocol is summarized in Figure 5.5. To commit a transaction may take only a single message round; however, to abort a transaction normally requires at least two message rounds. The first message round is required to establish the operational sites because generally a site is not certain of which sites are currently up. Termination and Recovery
Recovery Protocol Protocols at failed site to complete all transactions outstanding at the time of failures. • Classes of failures • Site failure • Lost messages • Network partitioning • Byzantine failures • Effects of failures • Inconsistent database • Transaction processing is blocked • Failed component unavailable Termination and Recovery
Independent Recovery A recovering site makes a transition directly to a final state without communicating with other sites. • Lemma For a protocol, if a local state’s concurrency set contains both an abort and commit, it is not resilient to an arbitrary failure of a single site. Si→ commit because other sites may be in abort Si→ abort because other sites may be in commit Rule 1: S: Intermediate state If C(s) contains a commit failure transition from S to commit Otherwise failure transition from S to abort cannot cannot Termination and Recovery
site 1 fails S1 S(S2) Rule 2: For each intermediate state Si: If tj S(Si) and tj has a failure transition to a commit (abort), then assign a timeout transition from Si to a commit (abort). Theorem: Rules 1 and 2 are sufficient for designing protocols resilient to a single site failure. p: consistent p': p + failure + time out transition Termination and Recovery
Theroem: There exists no protocol using independent recovery that is resilient to arbitrary failures by two sites. G0→ abort |G1 | Gk-1→ site j recovers to abort | only j makes a transition ↨ other sites recover to abort Gk→ site j recovers to commit | Gm→ commit same state exists for other sites first global state Failure of j recover to commit Failure of any other site recover to abort Termination and Recovery
Theorem: There exists no protocol resilient to a network partitioning when messages are left. Rule 3 Rule 4 • Theorem: Rules 3 and 4 are necessary and sufficient for making protocols resilient to a partition in a two-site protocol. • Theorem: There exists no protocol resilient to a multiple partition. Rules 1 Rule 2 Insomorphic to undelivered message ↔ timeout timeout ↔ failure Termination and Recovery
Definition Protocol is synchronous within one state transition if one site never leads another site by more than one state transition. Theorem: Fundamental non-blocking A protocol is non-blocking iff: 1. no local state S C(S) = A (abort) and C (commit) 2. no non-committable state S C(S) = C Lemma: A protocol that is synchronous within one state transition is non-blocking iff: • No local state adjacent to both a commit and an abort state. • 2. No non-committable state adj. to a commit state. Termination and Recovery