Compression
Compression. Monica Stoica, smonica@cs.bu.edu Boston University. Books used: Information Technology by David Cyganski. Why Image Compression?.


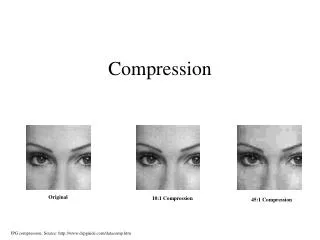
Compression
E N D
Presentation Transcript
Compression Monica Stoica, smonica@cs.bu.edu Boston University Books used: Information Technology by David Cyganski
Why Image Compression? • A high-quality image may require 10 to 100 million bits for representation. For example, a nearly photographic image requires approximately 1,280 rows of 800 pixels each, with 24 bits of color information per pixel; that is, a total of 24,576,000 bits, or 3,072,000 bytes. The large data files associated with images thus drive the need for extremely high compression ratios to make storage (particularly of movies) practical. • Without compression, a CD with a storage capacity of approximately 600 million bytes would only be able to store about 200 pictures like that above, or, at the 24 frames per second rate of a motion picture, about 8 seconds of a movie.
Why can we do compression? • Suppose we agree with a friend that from now on, whenever we would have spoken the word ``information,'' we will instead simply say ``eep.'' And, in the odd situation in which we should ever actually need to say eep itself one or more times, we will simply tack on an extra eep, for example, saying eepeepeep to convey the unusual message ``eepeep.'' Consider the benefits: • We have reduced every occurrence of the common four-syllable word, information, into a single syllable word; • We have a simple scheme that we can use to still convey an eep or even an eepeep when we really want to do so; The penalty is that we need to add a syllable to every eep utterance we make. But how often does it happen that we need to say eep or any of its derivatives?
Images have redundant data • Imagery data has more redundancy than we can generally find in other types of data. For example, a pair of adjacent rows of picture elements in an image are usually nearly identical, while two adjacent lines of text in a book have essentially no commonality. • The human eye is very tolerant of approximation error in an image. We may decide to exploit this tolerance to produce increased compression, at the expense of image quality (that is, we may intentionally introduce some error into the image). This approach would never be applied to financial data, for example, but for imagery the information loss may be irrelevant.
Loss less vs. Lossy • Usual methods of compression are called loss less coding techniques. With loss less coding, we restore every detail of the original data upon decoding. Obviously this is a necessity for numerical, financial documents. • Our tolerance of image approximation and need for high compression opens the opportunity to exploit a new form of coding: lossy coding. Lossy coding can only be applied to data such as images and audio for which humans will tolerate some loss of fidelity(faithfulness of our reproduction of an image after compression and decompression with the original image). Because we are no longer being held to the same requirements that underline the reproduction of financial or engineering data, we should be able to realize greater compression of the data as we increase the allowed loss of information.
Run Length Encoding • Is a common method that does not attempt to achieve the maximum compression available, but that is simple to implement. • For example, take the case of facsimile (fax) images of typical office documents. These two-color images (black and white) are predominantly white. • Many entire horizontal lines of picture elements are entirely white. Furthermore, if a given pixel is black or white,the chances are very good that the next pixel will match it. We call these groups of identical picture elements ``runs,'' and can assign codes to them that are much shorter than would be the case if the intensity and color of each individual picture element were transmitted. This form of data compression is called ``run length coding.''
Run length Coding • The purpose of run length encoding is to achieve easy compression by exploiting this special structure of images (runs) • It is done at very little computational expense in the coding and decoding process, so the computer takes a very small time to run it.
Example of Run length Coding in everyday life • Suppose you and a friend were given the task of counting the number of men and the number of women exiting a certain building. To make sure that no one is missed, you will simply watch the door and call out the sex of the person leaving. Your friend will make the appropriate notations in a notebook that you can later tally. After a half hour of calling out ``man, man, man, woman, woman, woman, woman, man, woman,...,'' you are getting quite tired of talking so much and your friend is getting quite tired of making little stroke marks in the man and woman columns. Your frustration causes you to become innovative
Continuation • There is no reason to call out and write down a result at each and every event. You could have called out the same sequence we described above in this way: ``Three men, four women, man, woman,....'' This is called run length encoding. Your friend, knowing the two categories, does not confuse the numbers for genders. • Hence, numbers can be intermixed in the stream of words to compress the amount of talking and writing involved in recording an unbroken sequence of one gender.
The JPEG Standard for Lossless Compression • while run length encoding is suitable where moderate compression is sufficient and fast processing of the compression by a computer is desired, there are needs for better compression of images as well. • For example, if data transmission rates are very slow, or if the amount of data storage that is available is very small, then high compression is needed even though it might take longer to compute once the image makes to the local computer.
JPEG • Joint Photographic Experts Group - the group of vendors and researchers that cooperated to design this industry standard for image compression. • The JPEG image compression standard 8.1 is actually not a single approach to compressing images. Rather, the standard describes 29 distinct coding systems for compression of images. The standard includes so many options because the needs of users vary so much with respect to quality versus compression, and compression computation time. The committee of experts developing these standards decided to provide abroad selection from which to choose.
JPEG • These various approaches can be divided into two basic groups: those that are loss less, like the run length encoding method we just described, and those that are lossy. • The lossy JPEG compression options are often used in practice. In this presentation, we discuss the loss less approach first, which includes only two of the 29 JPEG versions. Both of these use a technique called predictive coding to attempt to identify pixels later in the image in terms of previous pixels in that same image.
JPEG • There is not just a single prediction process that is used.The predictive process that is used in the loss less JPEG coding is varied automatically for any image on a line by line basis. The choice is made according to that prediction method that yields the best prediction overall for the entire line. There are seven prediction methods available in the loss less JPEG coding standards. These may be divided into the following categories: • 1.Predict the next pixel on a line in the image as having the same value as the previous pixel on that line. • 2.Predict the next pixel on the line as having the same value as the pixel on the line directly above it. • 3.Predict the next pixel on the line as having a value related to the values of three nearby pixels, such as the average of the three nearby pixel values.
JPEG • The next encoding step after the predicted pixel value is formed, is to compare that value to the actual pixel value. The difference, if any, forms that output stream of information to be sent to the next encoder step. If these differences are large, nothing is gained by this prediction process. • However, as a result of the smoothness and general redundancy of most pictures, the differences generally consist of a series of relatively small positive and negative numbers that represent the typically small errors in the prediction. The probabilities associated with these values are high for small error values, and are quite small for large errors.
JPEG Loss less better than Run Length Code • The typical loss less compression that we can achieve in this way for natural images is 2:1, or a 50% reduction in image data. • While this is substantial, it does not in general solve the problem of storing or moving very large sequences of images as encountered in high quality video.
GIF: Another Lossless Image Compression • GIF stands for Graphics Interchange Format and was developed by CompuServe. CompuServe was one of the pioneering companies in providing telephone-based computer network access, initially to its own bulletin boards and other services, and more recently to the Internet. • Their interest in creating the GIF compression scheme was that of making the exchange of pictures via telephone connections to their system practical. • GIF compression is much faster than is a direct application of the LZ algorithm, on which it is based.
GIF • we treat each byte of data as a indivisible message (one of the 256 colors allowed by the GIF format) and code strings of these whole bytes. This approach takes advantage of the fact that our images are structured and that strings of color patterns will be quite common. • Here we see GIF as occupying a place between that of run length encoding and loss less JPEG encoding in the spectrum of possibilities between low complexity and low compression systems (RLE) and high complexity and high compression systems (JPEG).
Lossy Compression • lossy compression algorithms obtain greater compression by allowing distortion of the image that will be recovered on decompression. In effect, these systems simplify the image by removing information from them. The more the degree of simplification, the less the recovered image will look like the original. • Because the allowable distortion varies according to the purpose of the image, the amount of compression is typically set by the user of the compression system. Thus, little if any lossy compression is typically acceptable for spy satellite and medical images, while considerable compression is applied to the screen saver and icon images that are displayed on one's computer.
Simple Lossy Compression Method • It subtracts from each pixel the value of the pixel before it in a line. Now, it scans the result looking for patterns of the form (1,-1), (-1,1), (1,0,-1), (-1,0,1), (1,0,0,-1), (-1,0,0,1) and replaces them with strings of two, three, or four zeros, respectively. These patterns correspond to locations where the adjacent pixels are very similar in color values. • What this is doing is replacing changes in intensity that reverse themselves with no change at all. • The pattern (1,-1) for example would be caused by a string of pixels in which an increase in brightness by a single level is immediately followed by a decrease by a single level. Under our compression scheme, the change will not be found in the new, compressed, image.
Simple Lossy Compression Method • Thus we have simplified the picture, but in such a way that it would only be revealed upon extremely careful inspection. • Next, a run length encoding is applied. Thanks to the simplification step,there ought now to be more long runs of similar pixel values. Hence the compression should be better than before at a small loss of fidelity.
JPEG Lossy Compression • The JPEG standard includes a set of sophisticated lossy compression options, which resulted from much experimentation by the creators of JPEG with regard to human acceptance of types of image distortion. The JPEG standard was the result of years of effort by the Joint Photographic Experts Group, which was formed as a joint effort by two large, standing, standards organizations,the CCITT (European Telecommunications Standards Organization) and the ISO (International Standards Organization). • The JPEG lossy compression algorithm consists of an image simplification stage, which removes image complexity at some loss of fidelity, followed by a loss less compression step based on predictive filtering and Huffman or arithmetic coding.
JPEG Lossy Compression • Recall that to represent color images, three values per pixel are needed. These may be the intensities of the three primary colors(red, green, and blue), or three other values that can be related mathematically to the primary colors. • The lossy JPEG approach requires that color images be treated in such an alternative form. That is, the original color image is separated into three images, one of which represents the brightness of each pixel, and the others of which represent color information. • In the JPEG image reduction process, if the image is pixels in size, we break it into square blocks of pixels and treat each block independently. The 64 pixel values in each block are transformed into a new set of 64 values.However, these new 64 values, known also as weights, form an entirely new way of representing an image than we have treated so far.
JPEG Lossy Compression • Imagine 64 slide projectors all playing light on a single screen. Further imagine that each of these projectors projects a different picture so that what we see is the result of overlapping all the pictures.Finally, imagine that we can control the brightness of each projector independently. The 64 weights tell us how bright or dim to make each projector so that the overlapped image forms a desired picture. • The 64 images that the weights refer to are pixel images that don't resemble anything from a particular image. However, it can be shown that any image can be created by superimposing all 64 images with appropriate scaling of the intensities of each one.
Advantages • It is fast to compute compared to many other suitable image transformations, • It usually tends to result in low values for the weights of some of its basis images. • The image that results from deleting low weight components is generally pleasing to the eye.
Last, but not the least… • The JPEG lossy compression algorithm next simplifies (throws away information) the weight data to reduce the number of bits in the images while doing minimal damage to the image quality. The process used is as follows: • First the smallest weights are eliminated, by setting them to zero. • The remaining weights are rounded off so that they may be represented with few bits. The amount of rounding, and hence then umber of bits transmitted, varies among all the weights,according to observed levels of sensitivity of viewers to these degradations.