Understanding Compression Techniques in Media Files
Explore compression methods for reducing raw media file sizes, including Run-Length Encoding (RLE), lossless vs. lossy compression, entropy and source coding, and practical examples. Learn how to apply RLE to compress data efficiently.


Understanding Compression Techniques in Media Files
E N D
Presentation Transcript
Compression • Sources • Chapter 6, main text: pp. 333-339 • Chapters 10 & 13 lab text: pp. 218-221, pp. 295-296 • Chapter 7 of Steinmetz & Nahrstedt (2002) • Run-length encoding (RLE) • http://www.prepressure.com/techno/compressionrle.htm
Media File Sizes • Raw media file sizes tend to be large • Audio: ‘raw’ is sample-based • Motion video/still images: raw is storing each image (e.g., frame) in its RGB representation for each pixel of the image resolution • Audio example: • 10 minutes of raw audio = 103, 359 KB • 44100 Hz sampling rate, 16 bit samples, stereo • Video example • 10 minutes of raw video = 16, 200, 200 KB • 640x480 pixels, 30 fps, 24 bit RGB pixels • BUT: We don’t always need or want files that are this big
Issues • Need: Perception • Human perception may not always need raw media to achieve reasonable performance • I.e., you may not always perceive the difference between having raw media and having media with lesser amounts of data (compressed media) • Want: Application requirements • Media file size related issues • Storage space: May have limited amounts of disk space • Transmission speed: Limits on real-time presentation • Requirements for quality vary depending on the application and individual • Quality of Service (QoS) requirements
Compression: The Idea • There is much information in the raw media files • Sometimes we don’t need all of it (perception, requirements) • There is redundancy • Reducing the number of bytes (changing raw to compressed) but preserving the original meaning or perception is often acceptable • Example: Video Compression • Temporal and spatial compression • Spatial: within a frame • Temporal: across frames • Key-frames in temporal compression • Store all information on one frame at particular intervals • Then store changes from this point • Uses frame differencing • Often, only slight changes from image to image in video • E.g., a common scene background
Terms and Methods • Compression, decompression • Specific algorithms and software required for both • Symmetric vs. Asymmetric compression/decompression • Symmetric: compression takes same amount of time as decompression • Asymmetric: one takes more time • E.g., compression takes a long time, but decompression is relatively fast • Types • Lossless compression • Improving code efficiency • E.g., CLUT in BMP (and AVI) files • Can reconstruct original data exactly • Lossy compression • Take into account perception, QoS requirements, and nature of data to reduce size • Cannot reconstruct original data exactly
Compression Techniques • Entropy Coding (lossless) • Encoding of bytes, without taking into account type of data (‘semantics’) • Examples • Run-length coding (e.g., BMP), • Huffman coding • Arithmetic coding • Source coding (often lossy) • Takes into account type of data • Prediction (DPCM, DM), Transformation (FFT, DCT), Layered coding (bit position, subsampling, subband coding), Vector quantization • Hybrid coding • JPEG, MPEG, H.263 Source: Steinmetz & Nahrstedt (2002), Ch.7
Run-Length Encoding: RLE • Partial Strategy: Analyze sequences of characters in files • If sequence just contains non-repeating characters • E.g., 12ABxy • Then, no savings: just code each character as the character itself • Otherwise, if sequence contains repeating characters • Replace sequence of same data value within a file • by a count number • and a single value (e.g., character) • Suppose the following string of ASCII data has to be compressed: ABBBBBBBBBCDEEEEF • Note: 9 B’s, 4 E’s • What will this look like in a compressed format? Lossless compression Source: http://www.prepressure.com/techno/compressionrle.htm
Problem • What if we had A9BCD4EF • As the uncompressed text? • We are unable to distinguish compressed text in the file from uncompressed text • Any numeric value in the file will be interpreted as the beginning of a compressed sequence • One solution • Use a special byte value to indicate when a compressed sequence of text follows, I.e., a count number follows • E.g., If we are coding ASCII text files, then ASCII does not use high order bit of byte, so special byte value can be 1000 0000 in binary (we’ll call this here)
RLE • Look at compressing same sequence again: ABBBBBBBBBCDEEEEF • Using RLE compression, the compressed file takes up 10 bytes and would look like this: A 9BCD4EF • Data size before compression: 17 bytes • Data size after compression: 10 bytes Savings: 17/10 = 1.7
Further Complication • Issue • In order to have a compression, need to have a sequence of >=4 of same characters • Solution • Don’t compress sequences of characters that have less than four repeated instances
Complete RLE Strategy • Analyze sequences of characters in files • If sequence just contains non-repeating characters, or sequences of repetitions of less than four of the same character • E.g., 12ABxyUU555 • Then, no savings: just code each character as the character itself • Otherwise, if sequence contains >= 4 repeating instances of a particular character • Replace sequence of same data value within a file by the following sequence: • First, a special marker that indicates that this sequence is compressed, call this • must be distinguishable from all other characters in the file • Then, a count number • Finally, the value (e.g., character) that was repeated
Huffman Coding • Bit sequence encoding based on statistics of occurrence of characters (bytes) in data • Idea: Code the most frequently occurring items with the fewest bits, and the least frequently occurring with more bits • Example • Say I give you a file • And, the file contains only the characters A, B, C, D, E • Need the probabilities of finding particular characters in this file • P(finding character A in the file) = P(A) = ? • P(finding character B in the file) = P(B) = ? • etc • How would we determine this? Lossless compression From example on p. 115-116, Steinmetz & Nahrsted (2002)
Frequencies and Probabilities • Just count up the number of A’s, B’s, C’s etc. Let N(A) = number of A’s in the file Let N(B) = number of B’s in the file • Etc • Let T = N(A) + N(B) + … The total number of characters in the file • Define P(A) = N(A)/T P(B) = N(B)/T • Etc.
Algorithm • Build an encoding binary tree from the leaves to the root as follows • Select two items (e.g., characters) with lowest probabilities • Combine into one node • Also call this an ‘item’ • Reassign probability as sum (‘or’ probability) • Apply technique until all items combined into the tree • Assign left/right edges between nodes “1” or “0” uniformly • E.g., left = 1, right = 0 • Path from root to leaf gives compressed encoding for that leaf item • Example • E.g., say the file we are compressing contains characters A, B, C, D, E with probabilities of occurrence: p(A)=.16, p(B) = .51, p(C)=.09, p(D)=.13, p(E)=.11
Important Property • No codes form a prefix of another • So, a sequence of codes in a file can only be interpreted in one way • No ambiguity
Background: Spatial Frequency Analysis • Idea of spatial frequency • Edges in images have high frequency values • Areas of the same color have low frequency values • High spatial frequency: Edges, details • Low spatial frequency: Main features • Examples • Russ, J. C. (1995). The Image Processing Handbook, 2nd Ed. CRC Press. • Pages 295, 298-299, 312 http://www.dai.ed.ac.uk/HIPR2/spatdom.htm
Example Nature Reviews Neuroscience4, 430 (2003); doi:10.1038/nrn1151
DCT: Discrete Cosine Transform • 1) Image is grouped into 8x8 pixel regions (e.g., each 8 bit pixels); Pixels: Sxy • 2) Spatial frequency transformation creating: Svu • Forward DCT • Creates 64 coefficient values, which are two-dimensional frequencies; e.g., S00 is fundamental color of all 64 pixels • 3) “Many images contain only a small portion of sharp edges; they consist mostly of areas of a single color” • Many coefficients with value 0 or near 0 • Entropy coding (e.g., Huffman coding) can be used to achieve data reduction p. 127 of Steinmetz & Klara Nahrstedt, 2002; quote from p. 129, same reference Inverse DCT used to decompress; limited precision used for DCT coefficients, therefore process is lossy Part of JPEG
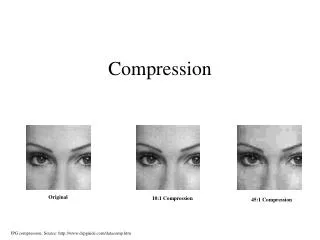
Issues & Tradeoffs • Time • Compression/decompression may take time • E.g., compressing raw video can take hours • Quality: Level of distortion • This is QoS (Quality of Service) dependent • E.g., for web-based programs, low quality images may be acceptable • Quantity: How much data • With more data we can often improve quality • But not necessarily
Codec’s • Compression and Decompression software for video and audio • “drivers” for the particular format used for the files • Depend on video/audio format, not on hardware • Within a particular general format (e.g., AVI or Quicktime) • E.g., with AVI, a Cinepak or Indeo codec can be used • Sorensen is available with Quicktime • Many codec’s can be used • Codec must be on both development & destination system • Some media players will search web sites for codecs • Software can detect the codec that media uses • AVI: http://p.duby.free.fr/avicodec.htm • MPEG: http://www.tmpgenc.net/e_main.html • Quicktime: quicktime Pro (www.quicktime.com)