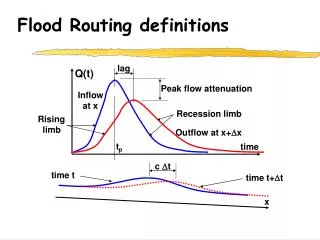
Advanced Statistical Methods for Feature Extraction and Pattern Classification in Speech Recognition
This comprehensive overview focuses on advanced statistical methods used in feature extraction and pattern classification for speech recognition. Key topics include training, testing, overfitting, and statistical discrimination methods such as the minimum distance classifier, Bayesian rule application, Gaussian classifiers, and neural networks. The differentiation between linear and nonlinear classifiers is examined, highlighting the significance of variability in speech signals and the powerful mathematical foundations that underpin these techniques. Insights into iterative training, covariance matrices, and upcoming assessments will also be discussed.


Advanced Statistical Methods for Feature Extraction and Pattern Classification in Speech Recognition
E N D
Presentation Transcript
From last time:PR Methods • Feature extraction + Pattern classification • Training, testing, overfitting, overtraining • Minimum distance methods • Discriminant Functions • Linear • Nonlinear (e.g, quadratic, neural networks) • -> Statistical Discriminant Functions
Statistical Pattern Recognition • Many sources of variability in speech signal • Much more than known deterministic factors • Powerful mathematical foundation • More general way of handling discrimination
Statistical Discrimination Methods • Minimum error classifier and Bayes rule • Gaussian classifiers • Discrete density estimation • Mixture Gaussians • Neural networks
we decide x is in class 2 we decide x is in class 1
How to approximate a Bayes classifier • Parametric form with single pass estimation • Discretize, count co-occurrences • Iterative training (mixture Gaussians, ANNs) • Kernel estimation
Minimum distance classifiers • If Euclidean distance used, optimum if: • Gaussian • Equal priors • Uncorrelated features • Equal variance per feature • If different variances per feature, correlated features, MD could be better
Then the discriminant function can be Di(x) = wiTx+ wi0 • Where Wi = Σi-1μi • Andwi0 = - ½ (μiTΣi-1μi) + log p(ωi) • This is a linear classifier
General Gaussian case • Unconstrained covariance matrices per class • Thenthe discriminant function is Di(x) = xTWix + wiTx + wi0 • This is a quadratic classifier • Gaussians are completely specified by 1stand 2nd order statistics • Is this enough for general populations of data?
A statistical discriminant function log p(x |ωi) + log p (ωi )
Remember: P(a|b) = P(a,b)/P(b) P(a,b) = P(a|b)P(b) = P(b|a)P(a)
Upcoming quiz etc. • Monday, 1st the guest talk on “deep” neural networks • Then the quiz. Topics: ASR basics, pattern recognition overview. Typical questions are multiple choice plus short explanation. Aimed at a 30 minute length. • There will be one more HW, one more quiz, then all oriented towards project.