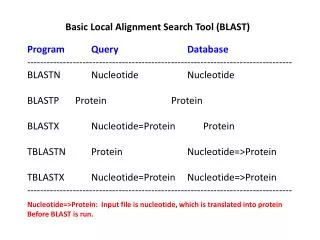
BLAST - Basic Local Alignment Search Tool
BLAST - Basic Local Alignment Search Tool. Published in 1990 by Altschul, Gish, Miller, Myers, and Lipman Originally for ungapped local comparison of sequences. It has since been expanded to involve comparisons of gapped sequences.


BLAST - Basic Local Alignment Search Tool
E N D
Presentation Transcript
BLAST - Basic Local Alignment Search Tool Published in 1990 by Altschul, Gish, Miller, Myers, and Lipman Originally for ungapped local comparison of sequences. It has since been expanded to involve comparisons of gapped sequences. There have been several extensions of the technique and improvements to the basic tool throughout the 17 years of its life thus far.
Needleman-Wunsch, SemiGlobal Alignment, and Smith-Waterman assume we know which two sequences we need to compare. • BLAST is designed to do a database search for possible matching sequences: • There is no known starting point to begin the matches • There is not a well established format for the information stored in the data • It is like searching for a file in a cluttered office – see Professor Leinbach’s or Professor James’ offices for reference. • The amazing thing is that BLAST has been so successful!
Consider this sequence • gtcaaatgaaaggagtttctacatttatgtcggaaatgctggaaacagcttctatattaa • We want to search for possible matches to gain clues to its identity • Place a sliding window 11 or 12 nucleotides long over the sequence • gtcaaatgaaaggagtttctacatttatgtcggaaatgctggaaacagcttctatattaa • Extract that subsequence and compress it to 3 bytes • Code a as 002 c as 012 g as 102 and t as 112 • Thus, the 11 characters take up 22 bits – 3 bytes with two bits unused • Using a Finite State Automaton, eliminate subsequences that occur with a very high frequency in the database • If the subsequence survives, i.e. is determined to be relatively rare, use hash table to locate sequences in the database that contain that subsequence. • Extend the match in both directions scoring the extension until the match drops below a predetermined threshold. If it survives for the length of the original sequence – report the result • Slide the window down one character and repeat steps 2 - 6 • The above is only an approximate description of the BLAST algorithm.
Here is one of the BLAST results for our sequence: Score = 44.1 bits (22), Expect = 0.035 Identities = 34/38 (89%), Gaps = 0/38 (0%) Strand=Plus/Plus Query 12 GGAGTTTCTACATTTATGTCGGAAATGCTGGAAACAGC 49 ||||| || ||||||||| | ||||||||||||||||| Sbjct 5030 GGAGTGTCAACATTTATGGCTGAAATGCTGGAAACAGC 5067 With a report of: gi|71835970|gb|DQ117988.1| Physcomitrella patens DNA mismatch repair protein MSH2 gene The result along with 68 others was reported in about 30 seconds of searching on a Friday afternoon before a holiday. The search involved over 3 million subject sequences accounting for over 16 billion characters!
Let’s try to mimic what may have happened to get this alignment. (This is all hypothetical for illustrative purposes only.) • 0. The user determines a scoring scheme, the sliding window size, the window cutoff score and a threshold for the extension. Let’s choose • score: match =1 mismatch = -1 • window size = 11 window cutoff score = 9 • extension threshold = 4 below present maximum • minimum reportable sequence length = 25 • BLAST has compiled a preliminary list of “words” that are considered as significant. One of the words is ATGCTGGAAAC. • This sequence is found in the MSH2 Gene of the moss. So the match begins. Query: ATGCTGGAAAC • Moss: ATGCTGGAAAC
We now begin the extension to the right and our score of 11 advances to a score of 14 (our present maximum) since we have three more matches • Query: ATGCTGGAAACAGC • Moss: ATGCTGGAAACAGC • We continue the extension and have 3 successive mismatches, 1 match, and then two more mismatches. The score is now four below the previous maximum of 14 • Query: ATGCTGGAAACAGCTGACTA • Moss: ATGCTGGAAACAGCCACCAG • We prune this part of the sequence • 5. We now repeat the extension process going to the left and obtain • the reported sequence of 27 characters • Query 12 GGAGTTTCTACATTTATGTCGGAAATGCTGGAAACAGC 49 • | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | • Moss 5030 GGAGTGTCAACATTTATGGCTGAAATGCTGGAAACAGC 5067
Let’s look at a real BLAST report using the blast2seq program on the NCBI BLAST page. For this example we compared pig -globin and Human Hemoglobin, beta mRNA. BLAST2Res.html Using accession numbers: 28302128(Human) and X86791.1(pig) Let’s look at a real BLAST report using the blast2seq program on the NCBI BLAST page. For this example we compared pig -globin and Human Hemoglobin, beta mRNA. BLAST2Res.html Using accession numbers: 28302128(Human) and X86791.1(pig) Let’s look at a real BLAST report using the blast2seq program on the NCBI BLAST page. For this example we compared pig -globin and Human Hemoglobin, beta mRNA. BLAST2Res.html Using accession numbers: 28302128(Human) and X86791.1(pig) Note the parameters that have been set by the user (or default) prior to beginning the search.
For protein sequences the window is 3 - 4 amino acids long: • 1 Amino Acid = 3 Nucleotides • 3 Amino Acids = 9 Nucleotides = 18 Bits coded • 4 Amino Acids = 12 Nucleotides = 3 Bytes coded • Alternative: One byte for each of Amino Acid Letters then a window of 3 Amino Acids would take 3 Bytes. • We will choose a window length of 3 Bytes for our example. • The BLAST algorithm has three main parts • Compile a list of pairwise alignments with the window called word pairs. • Scan this list for word pairs that meet some threshold score, T • Extend the word pairs that surpass some cutoff score S at which point those hits will be reported to the user. Scores are calculated by some scoring matrix, say BLOWSUM62.
Let’s apply these rules to the following sequences: • Bovine RBP • hmsatakgrv rllnnwdvca dmvgtftdte dpakfkmkyw gvasflqkgn ddhwiidtdy • 61 etfavqyscr llnldgtcad sysfvfardp sgfspevqki vrqrqeelcl arqyrliphn • 121 gycdgksern il • Human RBP • 1 mkwvwallll aawaaaerdc rvssfrvken fdkarfsgtw yamakkdpeg lflqdnivae • 61 fsvdetgqms atakgrvrll nnwdvcadmv gtftdtedpa kfkmkywgva sflqkg • These are rather short sequences and the matching subsequences are easy for us • to find. However, the computer has a narrow field of vision and needs to • follow the Algotithm.
Step 1: • First calculate the score for matching word in the sliding window with itself: • msa = (5 + 4 + 4) = 13 • Set a threshold (this is arbitrary), say T = 9 now match all possible word pairs with the word in the window • Words > T Words < T • msc = (5 + 4 + 9) = 17 msw = (5 + 4 – 3) = 6 • mst = (5 + 4 + 0) = 9 msf = (5 + 4 – 2) = 7 • mss = (5 + 4 + 1) = 10 mva = (5 – 3 + 4) = 6 • mta = (5 + 5 + 4) = 14 mia = (5 – 3 + 4) = 6 • mga = (5 + 0 + 4) = 9 dsa = (-3 + 4 + 4) = 5 • esa = (1 + 4 + 4) = 9 hsa = (-2 + 4 + 4) = 6 • This is only a partial list. There are 8,000 possible word pairs • We test the subject sequence for any occurrence of the words in the word pair that are above the threshold and are considered to be significant, i.e. occurring in the database with low frequency.
Next we (arbitrarily) set a cut off score for our extension, say S = 15. If the local alignment falls below this score, we stop aligning the sequences. hmsatakgrvrllnnwdvcadmvgtftdtedpakfkmkywgvasflqkgnddhwiidtdy fsvdetgqmsatakgrvrllnnwdvcadmvgtftdtedpakfkmkywgvasflqkg The box encloses our original match. We extend the match to the right and we come to the end of the second sequence (Human RBP) so we must stop. We now extend the original match to the left and the first sequence (Bovine RBP) ends with a mismatch. So, we do not include it in the report. Here is the report from the actual NCBI BLAST 2 Sequences program: Score = 104 bits (259), Expect = 1e-21 Identities = 48/48 (100%), Positives = 48/48 (100%), Gaps = 0/48 (0%) Query 69 MSATAKGRVRLLNNWDVCADMVGTFTDTEDPAKFKMKYWGVASFLQKG 116 MSATAKGRVRLLNNWDVCADMVGTFTDTEDPAKFKMKYWGVASFLQKG Sbjct 2 MSATAKGRVRLLNNWDVCADMVGTFTDTEDPAKFKMKYWGVASFLQKG 49
The Effect of the Threshold Parameter In the original papers on BLAST by Steven Altschul, David Lipman et. al. in 1990 and 1997 they called the threshold parameter T. In the NCBI BLAST program, this threshold is called f. Jonathan Pevsner (Bioinformatics and Functional Genomics, Wiley-Liss, 2003, p 102) reports on the effect of using different threshold values for performing a gapped BLAST search using RBP4 (NP_006735) as the Query sequence f = 11 (default) f = 5 f = 17 Number of sequences in db 1,046,476 1,046,476 1,046,476 Number of hits to the db 129,839,417 2,200,945,350 12,002,487 Number of extensions 5,198,652 589,935,555 61,838 Number of successful exten. 8,377 13,145 1,117 Number of HSPs gapped 145 146 93
The FASTA Heuristic Search Algorithm
FASTA • Developed by Pearson & Lipman in 1988 • Part of a family of algorithms known as FASTX Algorithms • Compares Query to every sequence in the database • Generally takes more time than BLAST • Uses a predetermined scoring matrix • Nucleotides: Identity, Cantor-Jukes, Kimura • Proteins: PAM250, Blosum62, Blosum50 • More Sensitive than BLAST especially when sequences are repetitive • Can do gapped comparisons
Algorithmic Details • Break the algorithm into words (similar to the sliding window in BLAST, although these are smaller) sometimes called a ktup (for k-tuple) Generally, 1 – 2 Amino Acids for proteins 4 – 6 Nucleotides for DNA Larger word sizes are usually less sensitive. • Gap Penalties (set by user – these are only suggestions) Opening or origination: -12 for proteins -16 for DNA Extension or Length: -2 for proteins -4 for DNA
Step1 – Break Query Sequence Into Words Our Example Sequence: R K T U R K R K T U R K K T T U U R R K K R R K K T T U These words will be placed within a table for comparison with the sequence from the database. Initially score based on the number of identities
Compare RKTURKRKTU with ARKURWKTUR Hash Table Key Address RK 1, 5, 7 KT 2, 8 TU 3, 9 UR 4 KR 6
Compare RKTURKRKTU with ARKURWKTUR Hash Table Key Address RK 1, 5, 7 KT 2, 8 TU 3, 9 UR 4 KR 6
FASTA – Steps 2, 3, & 4 2. In the complete query sequence locate the 10 regions having the highest score with the database sequence. Rescore those regions with a PAM or Blosum matrix. If necessary, trim the ends of the region if the result is a higher score. Call this score init1 3. Try to join some of the regions from step 2 even with gaps inserted if it makes a better overall score. Call this score an initnscore. 4. Use the full Smith – Waterman Algorithm on a narrow band, usually chosen to be 32 residues wide around the best matches from step 3. This is called the opt score.
Graphical Display of the Four Step FASTA Process Step 1 Step 2 Step 4 Step 3
Some Problems with FASTA • A sequence with 50% similarity could be missed • AKAKAKAKAKAKAKAKAKAK • ARARARARARARARARARAR • 2. The join in step 4 restricts the band to a width 32. Suppose that 2 proteins are identical except that one has a gap of length greater than 32 in the middle. FASTA will only pick up on one side of the gap. • FASTA picks up on only perfect matches and ignores conservative replacement in proteins, i.e. it may miss sequences with functional homology, but not identity. • NOTE: using a smaller word size can help with 1 and 3. No Word Matches
The Following Graphic Compares The Three Local Alignment Algorithms Speed is Graphed vs. Quality of the Results
A FASTA search engine is located at the BioChem Department server at the University of Virginia and can be reached through the URL http://fasta.bioch.virginia.edu/fasta This site allows the user to choose the database against which the query sequence will be run. In fact, the user can choose multiple databases! The user can then set the following parameters: ktup length scoring matrix gap origination gap exension A FASTA search engine is located at the BioChem Department server at the University of Virginia and can be reached through the URL http://fasta.bioch.virginia.edu/fasta This site allows the user to choose the database against which the query sequence will be run. In fact, the user can choose multiple databases! The user can then set the following parameters: ktup length scoring matrix gap origination gap exension A FASTA search engine is located at the BioChem Department server at the University of Virginia and can be reached through the URL http://fasta.bioch.virginia.edu/fasta This site allows the user to choose the database against which the query sequence will be run. In fact, the user can choose multiple databases! The user can then set the following parameters: ktup length scoring matrix gap origination gap exension
Here is the result of that search (whale hemoglobin vs hippo hemoglobin :
We also compare the whale hemoglobin with the same subunit of the pig hemoglobin