Download

1 / 171
1.76k likes | 2.08k Vues
WARNING! 175 slides! Print in draft mode, 6 to a page to conserve paper and ink!. TR 555 Statistics “Refresher” Lecture 2: Distributions and Tests. Binomial, Normal, Log Normal distributions Chi Square and K.S. tests for goodness of fit and independence Poisson and negative exponential

E N D
WARNING! 175 slides! Print in draft mode, 6 to a page to conserve paper and ink! TR 555 Statistics “Refresher”Lecture 2: Distributions and Tests • Binomial, Normal, Log Normal distributions • Chi Square and K.S. tests for goodness of fit and independence • Poisson and negative exponential • Weibull distributions • Test Statistics, sample size and Confidence Intervals • Hypothesis testing WARNING! 175 slides! Print in draft mode, 6 to a page to conserve paper and ink!
Another good reference • http://www.itl.nist.gov/div898/handbook/index.htm
Another good reference • http://www.ruf.rice.edu/~lane/stat_sim/index.html
Bernoulli Trials • Only two possible outcomes on each trial (one is arbitrarily labeled success, the other failure) • The probability of a success = P(S) = p is the same for each trial (equivalently, the probability of a failure = P(F) = 1-P(S) = 1- p is the same for each trial • The trials are independent
Binomial, A Probability Distribution • n = a fixed number of Bernoulli trials • p = the probability of success in each trial • X = the number of successes in n trials The random variable X is called a binomial random variable. Its distribution is called a binomial distribution
The binomial distribution with n trials and success probability p is denoted by the equation or
The binomial distribution with n trials and success probability p has • Mean = • Variance = • Standard deviation =
Binomial Distributions with p=.2 n=5 n=10 n=30
Transportation Example • The probability of making it safely from city A to city B is.9997 (do we generally know this?) • Traffic per day is 10,000 trips • Assuming independence, what is the probability that there will be more than 3 crashes in a day • What is the expected value of the number of crashes?
Transportation Example • Expected value = np = .0003*10000 = 3 • P(X>3) = 1- [P (X=0) + P (X=1) + P (X=2) + P (X=3)] • e.g.,P (x=3) = 10000!/(3!*9997!) *.0003^3 * .9997^9997 = .224 • don’t just hit 9997! On your calculator! • P(X>3) = 1- [.050 + .149 + .224 + .224] = 65%
Continuous probabilitydensity functions • The curve describes probability of getting any range of values, say P(X > 120), P(X<100), P(110 < X < 120) • Area under the curve = probability • Area under whole curve = 1 • Probability of getting specific number is 0, e.g. P(X=120) = 0
Characteristics of normal distribution • Symmetric, bell-shaped curve. • Shape of curve depends on population mean and standard deviation . • Center of distribution is . • Spread is determined by . • Most values fall around the mean, but some values are smaller and some are larger.
Probability = Area under curve • Normal integral cannot be solved, so must be numerically integrated - tables • We just need a table of probabilities for every possible normal distribution. • But there are an infinite number of normal distributions (one for each and )!! • Solution is to “standardize.”
Standardizing • Take value X and subtract its mean from it, and then divide by its standard deviation . Call the resulting value Z. • That is, Z = (X- )/ • Z is called the standard normal. Its mean is 0 and standard deviation is 1. • Then, use probability table for Z.
Suppose we want to calculate where We can calculate And then use the fact that We can find from our Z table
Suppose we wanted to calculate The using the law of complements, we have This is the area under the curve to the right of z.
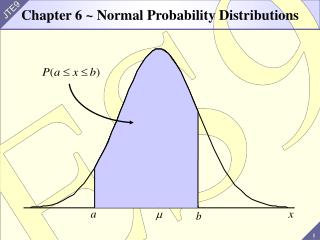
Now suppose we want to calculate This is the area under the curve between a and b. We calculate this by first calculating the area to the left of b then subtracting the area to the left of a. Key Formula!
Transportation Example • Average speeds are thought to be normally distributed • Sample speeds are taken, with X = 74.3 and sigma = 6.9 • What is the speed likely to be exceeded only 5% of the time? • Z95 = 1.64 (one tail) = (x-74.3)/6.9 • x = 85.6 • What % are obeying the 75mph speed limit within a 5MPH grace?
Assessing Normality • the normal distribution requires that the mean is approximately equal to the median, bell shaped, and has the possibility of negative values • Histograms • Box plots • Normal probability plots • Chi Square or KS test of goodness of fit
Transforms:Log Normal • If data are not normal, log of data may be • If so, …
Chi Square Test • AKA cross-classification • Non-parametric test Use for nominal scale data (or convert your data to nominal scale/categories) • Test for normality (or in general, goodness of fit) • Test for independence(can also use Cramer’s coefficient for independence or Kendall’s tau for ratio, interval or ordinal data) • if used it is important to recognize that it formally applies only to discrete data, the bin intervals chosen influence the outcome, and exact methods (Mehta) provide more reliable results particularly for small sample size
Chi Square Test • Tests for goodness of fit • Assumptions • The sample is a random sample. • The measurement scale is at least nominal • Each cell contains at least 5 observations • N observations • Break data into c categories • H0 observations follow some f(x)
Chi Square Test • Expected number of observations in any cell • The test statistic • Reject (not from the distribution of interest) if chi square exceeds table value at 1-α (c-1-w degrees of freedom, where w is the number of parameters to be estimated)
Chi Square Test • Tests independence of 2 variables • Assumptions • N observations • R categories for one variable • C categories for the other variable • At least 5 observations in each cell • Prepare an r x c contingency table • H0 the two variables are independent
Chi Square Test • Expected number of observations in any cell • The test statistic • Reject (not independent) if chi square exceeds table value at 1-α distribution with (r - 1)(c - 1) degrees of freedom
Transportation Example Number of crashes during a year
Transportation Example Adapted from Ang and Tang, 1975