Download

1 / 31
310 likes | 451 Vues
This study examines how different subsampling rates affect subbagging and related ensemble techniques using stable classifiers. Ensemble learning combines predictions from multiple models to enhance accuracy and efficiency. Key methods explored include bagging, subbagging, and double bagging, highlighting how subsampling without replacement can create diverse training sets. We analyze bias-variance tradeoffs among these techniques and present experimental results to demonstrate their effectiveness. Insights from this research contribute to the understanding of improving ensemble classifier performance via subsampling strategies.

E N D
Effect of Subsampling Rate onSubbagging and Related Ensembles ofStable Classifiers Zaman Faisal Kyushu Institute of Technology Fukuoka, JAPAN
Contents • ensemble learning • bagging • what is subsampling? • subagging • double bagging • subsample in double bagging = double subagging • bias – variance of a learning algorithm • what is stable learning algorithm • experiments and results • conclusion
Ensemble Learning Ensemble learning refers to a collection of methods that learn a target function by training a number of individual learners and combining their predictions. • Accuracy: a more reliable mapping can be obtained by • combining the output of multiple “experts” • Efficiency: a complex problem can be decomposed into • multiple sub-problems that are easier to understand • and solve. Example of ensemble methods : Bagging, Boosting, Double Bagging, Random Forest, Rotation Forest.
Bagging(Bootstrap Aggregating) Bagging uses the bootstrapping to generate multiple versions of the training set; then build predictor on each version. Then the prediction of these classifiers are combined or aggregated to get the final decision rule. • Bagging is executed as follows: • 1. Repeat for b=1, . . . B • a) Take a bootstrap replicate Xbof the training set XTRAIN. • b) Construct a base classifier Cb(x). • 2. Combine base classifiers Cb(x), b=1,2, . . . B; • by the simple majority rule to a final decision rule CCOMB.
Bagging(Bootstrap Aggregating) architecture T Using bootstrapping create multiple training sets T1 T2 T3 TB-1 TB Create multiple version of the baseclassifiers O1 O2 O3 OB-1 OB The out-of bag samples C1 C2 C3 CB-1 CB w2 w1 w2 w2 w1 w2 w1 w2 w1 w2 w1 w1 w1 w2 Majority voting Classifier outputs Standard Bagging Procedure CCOM
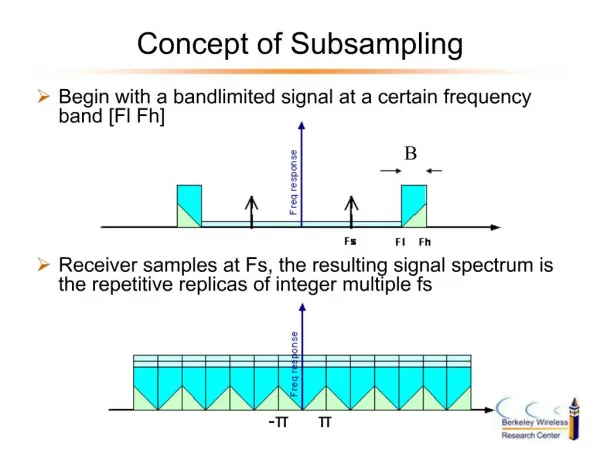
Subsampling-definition Subsampling is a computationally intensive resamplingmethod. In bootstrap we take samples of size n out of n, where n is the size of the training sample; where as in subsampling we take samples of size m out of n. In subsampling the sampling is without replacement for each sample, unlike the bootstrapping.
Subsampling-example • Let T be a training set with n elements. • A subsample Tb can be created from T choosing m elements from T randomly, without replacement. • In the following example we have created an example with 5 subsamples, each having 3 instances, which is half of the original training sample. • T T1 T2 T3 T4 T5 X(1) X(2) X(3) X(4) X(5) X(6) X(3) X(2) X(5) X(2) X(3) X(1) X(5) X(2) X(1) X(1) X(6) X(4) X(6) X(4) X(5) Example of 5 subsamples
Subsampling Ratio-definition In the example we have subsampledhalf of the training sample size for each subsample. This is called the subsampling ratio. This is denoted with ρ. So if ρ = 0.4 and training sample size is N, then each subsample shall have ρxN instances.
Subagging Subbagging ( SUBsampleAGGregatING) Subbagging was proposed by P. Bühlman in 2003. In Subbagging : 1) Use ,”subsamples” to generate multiple training sets instead of bootstrap samples. 2) In the case of CART, it performs quite similar to Bagging. 3) When the size of each subsample is half of the training set then the subbagging with CART performs alike Bagging with CART.
Double Bagging • Double Bagging was first proposed by TorstenHothorn in 2002. The • main idea of double bagging lies in increasing (adding) additional • predictors with the original predictors. They used LDA as the • additional classifier model. • These additional predictors are generated from the out-of-bag • sample. • In bagging in each bootstrap replicate 63% of the original • training instances are sampled, where as the rest (37%) are • unsampled; these samples are called out-of-bag samples (OOBS). • In Double bagging classifiers models are built using these OOBS • and then trained back on the bootstrap replicates to generate • additional predictors.
Double Bagging-Algorithm In general the Double Bagging algorithm is performed as the following steps: Loop Start: For b = 1,2, … B Step 1: Generate bootstrap sample from the training set. Step 2: From the out-of-bag sample of the construct a classifier model. Step 3a: Use this additional classifier on the bth bootstrap sample to generate additional predictors. Step 3b: Do the same for a testing instance x, and generate additional predictors with x. Step 4: Build a tree classifier model with bth bootstrap replicate and the additional predictors. Finish. Step 5: Combine all the tree models using, “average” rule. Step 6: Classify a test instance x with the additional predictors using the combined tree( tree ensemble).
Double Bagging-architecture Training Set N = No. of Observations in Data α = percentage of observations N*α T Data N*(1-α) Test Test Set Step 1: T1 O1 T2 O2 TB OB … Multiple bootstrap Sets Test Set Step 2: Training Classifier models using out-of-bag samples Model1 Model2 ModelB Step 3a and 3b: Using these classifiers in Bootstrap samples and Test set to get additional predictors C1 T1 C2 T2 CB TB Building DT ensemble with the additional predictors DT1 DT2 DTB Combine the DT using average rule Test TC1 TCB … , CCOMB
Subsample in Double Bagging-Algorithm • In Double Bagging instead of bootstrap samples, we can use subsamples. This has • two major advantages: • it will enlarge the out-of-bag sample size, which entails a better learning of the • additional classifier. • b) the time complexity of the ensemble learning will be reduced. N = No. of Observations in Data ρ = Subsampling Ratio Sampling without replacement T N*ρ = size of subsample T Data O N*(1-ρ) = size of out-of- bag sample O So if ρ = 0.5 then the size of the OOBS will be larger than the usual bagging OOBS and in addition to that the size of the subsample will be smaller, which ensure that the training time of the ensemble will be less.
Bias and Variance of a learning algorithm • Bias systematic error component (independent of the learning sample) • Variance error due to the variability of the model with respect to the learning sample randomness • Intrinsic Error There are errors due to bias and errors due to variance • Error = Bias2 + Variance + Intrinsic Error
Stable learning algorithm - Bias – variance point of view A learning algorithm is called stable if it has high bias but low variance. This means that in each prediction problem the predicted examples of that algorithm will not differ much. Example: Linear classifiers, Nearest Neighbor classifiers, Support Vector Machine, e.t.c. In the opposite a learning algorithm is called instable if it has low bias but high variance. Example: Decision Tree.
Experiment and Results • We have used three additional classifier models in double bagging with different subsamples ratios: • Linear Support Vector Machine (LSVM) • Stable Linear Discriminant Classifier (sLDA) • Logistic Linear Classifier (LogLC)
Experiment and Results In the experiments we have used five different subsampling ratios, ρ = 0.2, 0.3, 0.5, 0.65, 0.75, 0.8 We have five datasets from UCI Machine Learning Repository. We have used 10-Crossvalidation to compute the errors of the methods. Table: Descriptions of the datasets
Experiment and Results- Diabetes Dataset Results Double SubaggingResults Subagging Results Misclassification Error Misclassification Error Subsample Ratios Subsample Ratios Figure: Misclassification Error of Double Subagging and Subagging in Diabetes Data with different stable classifieirs
Experiment and Results- German Dataset Results Double SubaggingResults Subagging Results Figure: Misclassification Error of Double Subagging and Subagging in German Data with different stable classifieirs
Experiment and Results- Glass Dataset Results Double SubaggingResults Subagging Results Misclassification Error Misclassification Error Subsample Ratios Subsample Ratios Figure: Misclassification Error of Double Subagging and Subagging in Glass Data with different stable classifieirs
Experiment and Results- Heart Dataset Results Double SubaggingResults Subagging Results Misclassification Error Misclassification Error Subsample Ratios Subsample Ratios Figure: Misclassification Error of Double Subagging and Subagging in Heart Data with different stable classifieirs
Experiment and Results- Ion Dataset Results Double SubaggingResults Subagging Results Misclassification Error Misclassification Error Subsample Ratios Subsample Ratios Figure: Misclassification Error of Double Subagging and Subagging in Ion Data with different stable classifieirs
Conclusion • In almost all datasets, double subagging performed quite better than subagging. • Double Subagging performed well with very small subsample ratios ρ= 0.3. • With subsample ratio ρ= 0.65~0.8 the performance of double subagging is BAD. • Performance of LSVM and Loglc are competitive as additional classifier in Double Subagging. • In subagging all the classifiers performed very competitively; with sLDA showing slightly better performance than LSVM and Loglc. • In case of subagging, it performed well with larger subsample ratios ρ= 0.75 and 0.8 in almost all datasets (exception is Heart dataset). • With very small subsample ratios subagging performed very BAD. • There is an opposite relationship in the performance of Double subagging and subagging. For each dataset for each classifier, double subagging performed best with the subsample ratio ρLOW= 1-ρHIGH, where ρHIGH is the subsample ratio with which the subagging performed best.