Download

1 / 20
200 likes | 216 Vues
Explore tools and approaches for merging and analyzing ontologies, with focus on collaboration, ontology mapping, and addressing scale. Discover Chimaera, an ontology evolution environment, and the Semantic e-Science Data Evaluation system. Enhance your data registration process with domain-specific checks and broader audience interfaces.

E N D
Information Fusion: Moving from domain independent to domain literate approaches Professor Deborah L. McGuinness Tetherless World Constellation, Rensselaer Polytechnic Institute Troy, NY USA AGU 2008 Fall Meeting 15–19 December 2008, San Francisco, California
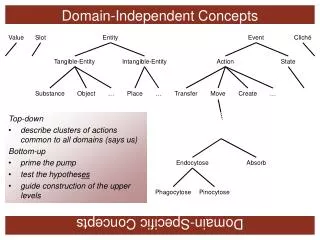
Previous (CS) Work • General toolkit work exists to support many aspects of analysis and evolution of knowledge encodings • Issues diagnosis and support for: • Collaboration (with distributed teams) • Diverse training levels • Interconnectivity with many systems/standards • Scale • Ontology mapping and merging • Ontology (schema) diagnostics • Instance level registration and analysis
Approaches • Review structure and encoding of schema for logical and possible problems • Review structure and encoding of ground data for logical and possible problems • Review (and automatically or semi-automatically gather) existing ontologies and data • Incorporate domain knowledge into analysis and mapping/merging process • Expose selected resources to help domain experts find, encode, and analyze
Chimaera: An Ontology Evolution Environment • An interactive web-based tool aimed at supporting: • Merging (later mapping) of ontological terms from varied sources • Diagnosis of coverage and correctness of ontologies • Maintaining ontologies over time • Features: multiple I/O languages, loading and merging into multiple namespaces, collaborative distributed environment support, integrated browsing/editing environment, extensible diagnostic rule language • Built by computer scientists uses domain independent approach. Has been extended to leverage selected portions of domain dependent info. (www.ksl.stanford.edu/software/chimaera)
The Analysis Task • Review KBs that: • Were developed using differing standards • May be syntactically but not semantically validated • May use differing modeling representations • Produce KB logs (in interactive environments) • Identify provable problems • Suggest possible problems in style and/or modeling • Are extensible by being user programmable
Loads in logic encoding: Integrity/ logical checks (numbers outside ranges, missing values, values of wrong type, “Bad” form checks cycles in structure referenced but not defined, redundant super classes …
The KB Merging -> Mapping Task • Work with Knowledge bases that: • Were developed independently by multiple authors • Express overlapping knowledge in a common domain • Use differing representations and vocabularies • Produce merged KB with • Non-redundant • Coherent • Unified vocabulary, content, and representation • Later emphasis (by this and other work) on creating mapping relationships rather than merging commands
Next Generation • Update to current languages (OWL, SPARQL, …) • Leverage general (domain independent) foundations • Focus more on instance level data (studies show more than 90% of RDF data is instance data) • Focus more on mapping rather than merging
SEDRE (Sinha Rezgui): a system that enables scientists to semantically register data sets for optimal querying and semantic integration • SEDRE enables mapping of heterogeneous data to concepts in domain ontologies • Uses an ontology for the registration procedure Ontology-Enabled Data Registration:
How to find the data? • Include background knowledge of the form data providers typically do. One example from using terms and relationships from volcano chemistry, atmospheric chemistry, thermal profiles, solar irradiance data, etc.
Registration of Volcanic Data • Location Codes: • U - Above the 180° turn at Holei Pali (upper Chain of Craters Road) • L - Below Holei Pali (lower Chain of Craters Road) • UL - Individual traverses were made both above and below the 180° turn at Holei Pali • H - Highway 11 SO2 Emission from Kilauea east rift zone - vehicle-based (Source: HVO) Abreviations: t/d=metric tonne (1000 kg)/day, SD=standard deviation, WS=wind speed, WD=wind direction east of true north, N=number of traverses
Registering Volcanic Data (2) • Uses background knowledge to provide connections – for example by linking volcanoes to their lat long location. • Exposes chemistry information in a typical structured form
Directions • Include background ontologies in domain areas • Focus on instance data and schema data (e.g. TW-OIE) • Add domain-specific checks that should be performed • Update interfaces to aim at broader (not just CS) audience • Integrate more with existing (often domain-specific) environments (e.g., SEDRE) • Focus on known issues such as unit conversion support • Leverage extensive acronym expansion options (e.g., Chimaera’s extension to include other vocabularies) • Smart search (e.g. Noesis) • Use results of learners /crawlers • Scale