
Improve Run Generation
Strategies to Improve Disk Memory Efficiency, Reduce Runs, and Increase CPU Utilization with Quick Sort and Internal Sorting Schemes. Includes a new buffer strategy for steady-state operations.

Improve Run Generation
E N D
Presentation Transcript
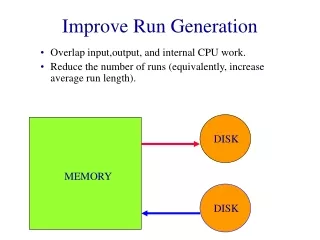
DISK MEMORY DISK Improve Run Generation • Overlap input,output, and internal CPU work. • Reduce the number of runs (equivalently, increase average run length).
6 2 8 5 11 10 4 1 9 7 3 4 2 3 5 1 6 10 11 9 7 8 Internal Quick Sort Use 6 as the pivot (median of 3). Input first, middle, and last blocks first. In-place partitioning. Input blocks from the ends toward the middle. Sort left and right groups recursively. Can begin output as soon as left most block is ready.
B1 B2 B3 Alternative Internal Sort Scheme Partition into 3 buffers. DISK DISK
Read from disk Write to disk Run generation Steady State Operation • Synchronization is done when the active input buffer gets empty (the active output buffer will be full at this time).
Use 2 input and 2 output buffers. Rest of memory is used for a min loser tree. Loser Tree Input 0 Output 0 Output 1 Input 1 DISK MEMORY DISK New Strategy
Read from disk Write to disk Run generation Steady State Operation • Synchronization is done when the active input buffer gets empty (the active output buffer will be full at this time).
O0 O1 I1 I0 Initialize 3 4 8 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 Fill From Disk
O0 O1 I1 I0 Initialize 3 6 1 4 8 5 7 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 Fill From Disk
O0 O1 I1 I0 Initialize 1 3 6 3 2 4 8 5 7 6 9 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 Fill From Disk
O0 O1 I1 I0 Initialize 1 3 2 6 3 4 2 4 8 5 7 6 9 5 8 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 Fill From Disk
O0 O1 I1 I0 Initialize 1 3 2 6 3 4 5 4 8 5 7 6 9 5 8 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 Fill From Disk
O0 O1 I1 I0 Initialize 2 3 2 6 3 4 5 4 8 5 7 6 9 5 8 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 Fill From Disk
2 O0 O1 3 2 6 3 4 5 4 8 5 7 6 9 5 8 4 3 6 8 1 5 7 3 2 6 9 4 5 2 5 8 I1 I0 Fill From Tree Generate Run 1 3 5 4 Fill From Disk
3 O0 O1 I1 I0 Fill From Tree 1 Generate Run 1 2 3 2 6 3 4 5 4 8 5 7 6 9 5 8 3 4 3 6 8 5 7 3 2 6 9 4 5 2 5 8 3 5 4 Fill From Disk
4 5 O0 O1 I1 I0 Fill From Tree 1 2 Generate Run 1 3 3 2 6 3 4 5 4 8 5 7 6 9 5 8 3 5 4 3 6 8 5 7 3 6 9 4 5 2 5 8 3 5 4 Fill From Disk
5 4 O0 O1 I1 I0 Fill From Tree 1 2 Generate Run 1 3 2 3 2 6 3 4 5 4 8 5 7 6 9 5 8 3 5 4 4 3 6 8 5 7 3 6 9 4 5 5 8 3 5 4 Interchange Role Of Buffers Fill From Disk
4 5 O0 O1 I1 I0 Interchange Role Of Buffers Write To Disk Fill From Tree 1 2 3 2 3 2 6 3 4 5 4 8 5 7 6 9 5 8 3 5 4 4 3 6 8 5 7 3 6 9 4 5 5 8 1 9 2 Fill From Disk
4 5 O0 O1 I1 I0 Write To Disk Fill From Tree 1 2 Continue With Run 1 3 2 3 4 6 3 4 5 4 8 5 7 6 9 5 8 3 5 4 4 3 6 8 5 7 3 6 9 4 5 5 8 1 9 2 Fill From Disk
5 1 5 O0 O1 I1 I0 Write To Disk Fill From Tree 1 3 2 Continue With Run 1 4 2 3 4 6 3 4 5 4 8 5 7 6 9 5 8 5 4 4 3 6 8 5 7 3 6 9 4 5 5 8 1 1 9 2 Fill From Disk
5 1 5 O0 O1 7 9 5 I1 I0 Write To Disk Fill From Tree 1 3 2 3 Continue With Run 1 4 2 3 4 6 3 4 5 4 8 5 7 6 9 5 8 9 5 4 4 3 6 8 5 7 6 9 4 5 5 8 1 1 9 2 Fill From Disk
5 5 1 O0 O1 7 5 9 I1 I0 Write To Disk Fill From Tree 1 3 2 3 Continue With Run 1 4 2 3 3 4 6 3 4 5 4 8 5 7 6 9 5 8 2 9 5 4 4 6 8 5 7 6 9 4 5 5 8 1 1 9 2 Interchange Role Of Buffers Fill From Disk
5 1 5 O0 O1 7 5 9 I1 I0 Fill From Tree Interchange Role Of Buffers Write To Disk 3 3 4 3 3 4 6 3 4 5 4 8 5 7 6 9 5 8 2 9 5 4 4 6 8 5 7 6 9 4 5 5 8 1 6 1 3 Fill From Disk
5 2 1 5 O0 O1 7 5 9 I1 I0 Fill From Tree Write To Disk 3 3 Continue With Run 1 4 3 3 4 6 3 4 5 4 8 5 7 6 9 5 8 2 9 5 4 4 6 8 5 7 6 9 4 5 5 8 1 6 1 3 Fill From Disk
5 2 5 1 O0 O1 6 9 5 5 7 I1 I0 Fill From Tree Write To Disk 4 3 3 Continue With Run 1 4 3 3 4 6 3 4 5 4 8 5 7 6 9 5 8 6 2 9 5 4 6 8 5 7 6 9 4 5 5 8 1 6 1 3 Fill From Disk
5 1 2 1 5 9 O0 O1 4 5 9 7 5 5 6 I1 I0 Fill From Tree Write To Disk 4 3 4 3 Continue With Run 1 4 3 3 6 3 4 5 4 8 5 7 6 9 5 8 6 2 9 5 1 4 6 8 5 7 6 9 5 5 8 1 6 1 3 Fill From Disk
Buffer Reduction • We may reduce the number of buffers to 3. • At any time, 1 us used to read into, 1 to write from, and the 3rd both feeds the loser tree and is filled from the tree. • The 3 physical buffers rotate through these three roles.
RUN SIZE • Let k be number of external nodes in loser tree. • Run size >= k. • Sorted input => 1 run. • Reverse of sorted input => n/k runs. • Average run size is ~2k.
Comparison • Memory capacity = m records. • Run size using fill memory, sort, and output run scheme = m. • Use loser tree scheme. • Assume block size is b records. • Need memory for 4 buffers (4b records). • Loser tree k = m – 4b. • Average run size = 2k = 2(m – 4b). • 2k >= m when m >= 8b.
m 600 1000 5000 10000 k 200 600 4600 9600 2k 400 1200 9200 19200 Comparison • Assume b = 100.
Comparison • Total internal processing time using fill memory, sort, and output run scheme = O((n/m) m log m) = O(n log m). • Total internal processing time using loser tree = O(n log k). • Loser tree scheme generates runs that differ in their lengths.
9 6 4 3 6 9 4 3 Merging Runs Of Different Length 22 22 13 7 15 7 Cost = 42 Cost = 44 Best merge order?





















