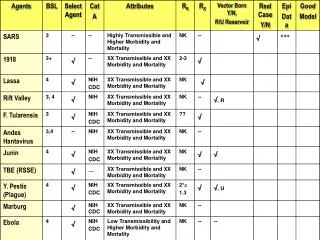
Evaluating OLTP Execution Strategies: A Study of Stratified and Collective Approaches
This research paper explores the efficiency of two distinct OLTP execution strategies: Stratified Execution (STREX) and Collective Caches (SLICC). By analyzing their micro-architectural effectiveness, particularly in terms of cache refill counts and instruction stalls, we aim to reveal their impact on transaction throughput in multi-core environments. Additionally, the paper discusses proposed hybrid solutions that leverage the strengths of both approaches to optimize instruction caches and reduce performance bottlenecks. This study enlightens the ongoing discourse on improving transaction processing in modern CPU architectures.
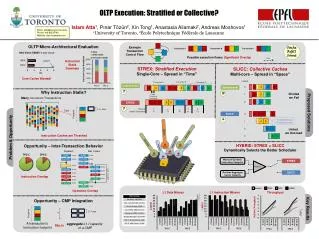

Evaluating OLTP Execution Strategies: A Study of Stratified and Collective Approaches
E N D
Presentation Transcript
OLTP Execution: Stratified or Collective? Transaction B Transaction C Transaction A Islam Atta1, Pınar Tözün2, Xin Tong1, Anastasia Ailamaki2, Andreas Moshovos1 1University of Toronto, 2École Polytechnique Fédérale de Lausanne Better Better Email: iatta@eecg.toronto.edu Phone: 416-805-8790 Website: http://islamatta.com OLTP Micro-Architectural Evaluation Cache Refill Count Transaction A Example Transaction Control Flow Intel Xeon X5660 4-way Issue Transaction B Possible execution flows;Significant Overlap Ideal Instruction Stalls Dominate Transaction C STREX: Stratified Execution Single-Core – Spread in “Time” SLICC: Collective Caches Multi-core – Spread in “Space” Time Core Cycles Wasted! CORES Conventional A A A A 0 Conventional C B C B C A A A A B 9 Why Instruction Stalls? 10 Divided we Fail 1 B B B Cache Thrashing Overhead Many concurrent Transactions A C A B B C B A C A C C C 2 STREX Proposed Solutions 3 4 Phase # 1 5 2 3 Leader Transaction T2 T1 T1 T1 T1 L1-I size SLICC B A C A 0 Each Footprint 4 Threads Migrate Chasing Locality 1 B A A C 2 United we Succeed Problem & Opportunity Instruction Caches are Thrashed B C 3 HYBRID: STREX + SLICC Dynamically Selects the Better Scheduler Opportunity – Inter-Transaction Behavior Payment New Order R(WH) 41.5KB R(WH) 41.4KB Measure Dynamic Instruction Footprint R(DIST) 40.5KB R(DIST) 40.5KB STREX R(CUST) 40.5KB 28.8KB TPC-C TPC-E IT(CUST) 41.8KB Compare R(ITEM) 39.6KB U(DIST) R(CUST) 39.1KB R(STO) 40.2KB SLICC Runtime Aggregate Cache Capacity U(CUST) 29.9KB Loop (OL_CNT) U(STO) 29.4KB Instruction Overlap Baseline U(DIST) 28.7KB I(OL) 65.3KB SLICC U(WH) 28.7KB 41.5KB I(ORD) STREX I(HIST) 47.4KB I(NORD) 41.5KB HYBRID Operation Overlap L1 Data Misses L1 Instruction Misses Throughput Opportunity – CMP Integration Key Results Footprint L1-I size A transaction's Instruction footprint aggregate L1-I capacity of a CMP fits in