Query Processing and Optimization
This review explores the architecture of database storage managers, focusing on secondary storage organization. A mapping table is utilized to manage the allocation of frames in a buffer pool during page requests. It details the pinning and unpinning of pages, the structure of records and files, various indexing techniques, and the efficient use of B+-trees for data retrieval. It also outlines steps for effective query processing, including query translation, algebraic optimization, plan selection, and evaluation to minimize disk I/O costs. This comprehensive approach enhances the overall database performance.


Query Processing and Optimization
E N D
Presentation Transcript
Query Processing and Optimization (Review from Database II)
Data Organization on Secondary Storage Architecture of a database storage manager: A mapping table maps page# to frame# free frame disk page buffer pool secondary storage
Buffer Management When a page is requested, the storage manager looks at the mapping table to see if this page is in the pool. If not: • If there is a free frame, it allocates the frame, reads the disk page into frame, and inserts the mapping from page# to frame# into the mapping table. • Otherwise, it selects an allocated frame and replaces it with the new page. If the victim frame is dirty (has been updated), it writes it back to disk. It also updates the mapping table. Then it pins the page.
Pinning/Unpinning Data The page pin is a memory counter that indicates how many times this page has been requested. The pin counter and the dirty bit of each frame can be stored in the mapping table. When a program requests a page, it must pin the page, which is done by incrementing the pin counter. When a program doesn’t need the page anymore, it unpins the page, which is done by decrementing the pin counter. When the pin is zero, the frame associated with the page is a good candidate for replacement when the buffer pool is full.
A Higher-Level Interface Page I/O is very low level. You can abstract it using records, files, and indexes. A file is a sequence of records, while each record is an aggregation of data values. Records are stored on disk blocks. Small records do not cross page boundaries. The blocking factor for a file is the average number of file records stored on a disk block. Large records may span multiple pages. Fixed-size records are typically unspanned. The disk pages of a file that contain the file records may be contiguous, linked, or indexed. A file may be organized as a heap (unordered) or a sequential (ordered) file. Ordered files can be searched using binary search but they are hard to update. A file may also have a file descriptor (or header) that contains info about the file and the record fields.
Indexes The most common form of an index is a mapping of one or more fields of a file (this is the search key) to record ids (rids). It speeds up selections on the search key. An index gives an alternative access path to the file records on the index key. Types of indexes: • Primary index: if the search key contains the primary key. If the search key contains a candidate key, is a unique index. Otherwise, it is a secondary index. • Clustered index: when the order of records is the same as the order of index. • Dense index: when, for each data record, there is an entry in the index with search key equal to the associated record fields. Otherwise, it is sparse. A sparse index must be clustered, to be able to locate records with no search key.
B+-trees B+-trees are variations of search trees that are suitable for block-based secondary storage. They allow efficient search (both equality & range search), insertion, and deletion of search keys. Characteristics: • Each tree node corresponds to a disk block. The tree is kept height-balanced. • Each node is kept between half-full and completely full, except for the root, which can have one search key minimum. • An insertion into a node that is not full is very efficient. If the node is full, we have an overflow, and the insertion causes a split into two nodes. Splitting may propagate to other tree levels and may reach the root. • A deletion is very efficient if the node is kept above half full. Otherwise, there is an underflow, and the node must be merged with neighboring nodes.
B+-tree Node Structure Order p of a B+-tree is the max number of pointers in a node: p = (b+k)/(k+d) where b is the block size, k is the key size, and d is the pointer size. Number of pointers, q, in an internal node/leaf: p/2 q p Search, insert, and delete have logqN cost (for N records). Internal node … … K1 Ki-1 Ki Kq-1 P1 Pi Pq K K1 Ki-1< K Ki K > Kq-1
Example For a 1024B page, 9B key, and 7B pointer size, the order is: p = (1024+9)/(9+7) = 64 In practice, typical order is p=200 and a typical fill factor is 67%. That is, the average fanout is 133 (=200*0.67). Typical capacities: • Height 3: 2,352,637 records (=1333) • Height 4: 312,900,700 records (=1334)
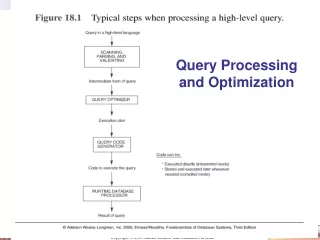
Query Processing Need to evaluate database queries efficiently. Assumptions: • You can not upload the entire database in memory • You want to utilize the memory as much as possible • The cost will heavily depend on how many pages you read from (and write to) disk. Steps: • Translation: translate the query into an algebraic form • Algebraic optimization: improve the algebraic form using heuristics • Plan selection: consider available alternative implementation algorithms for each algebraic operation in the query and choose the best one (or avoid the worst) based on statistics • Evaluation: evaluate the best plan against the database.
Evaluation Algorithms: Sorting Sorting is central to query processing. It is used for: • SQL order-by clause • Sort-merge join • Duplicate elimination (you sort the file by all record values so that duplicates will moved next to each other) • Bulk loading of B+-trees • Group-by with aggregations (you sort the file by the group-by attributes and then you aggregate on subsequent records that belong to the same group, since, after sorting, records with the same group-by values will be moved next to each other)
External Sorting Available buffer space: nB 3 Number of blocks in file: b Number of initial runs: nR = b/nB Degree of merging: dm = min(nB-1,nR) Number of passes is logdmnR file Memory (nB blocks) merging sorting merging initial runs Sorting cost: 2*b Merging cost: 2*b*logdmnR Total cost is O(b*logb)
Example With 5 buffer pages, to sort 108 page file: • Sorting: nR=108/5 = 22 sorted initial runs of 5 pages each • Merging: dm=4 run files to merge for each merging, so we get 22/4=6 sorted runs (5 pages each) that need to be merged • Merging: we will get 6/4=2 sorted runs to be merged • Merging: we get the final sorted file of 108 pages. Total number of pages read/written: 2*108*4 = 864 pages (since we have 1 sorting + 3 merging steps).
Replacement Selection Question: What’s the best way to create each initial run? With QuickSort: you load nB pages from the file into the memory buffer, you sort using QuickSort, and you write the result to a runfile. So the runfile is always at most nB pages. With HeapSort with replacement selection: you load nB pages from file into the memory buffer, you perform BuildHeap to create the initial heap in memory. But now you continuously read more records from the input file, you Heapify each record, and you remove and write the smallest element of the heap (the heap root) into the output runfile until the record sort key is larger than the smallest key in the heap. Then, you complete the HeapSort in memory and you dump the sorted file to the output. Result: the average size of the runfile is now 2*nB. So even though HeapSort is slower than QuickSort for in-memory sorting, it is better for external sorting, since it creates larger runfiles.
Join Evaluation Algorithms Join is the most expensive operation. Many algorithms exist. Join: R R.A=S.B S Nested loops join (naïve evaluation): res for each rR do for each sS do if r.A=s.B then insert the concatenation of r and s into res Improvement: use 3 memory blocks, one for R, one for S, and one for the output. Cost = bR+bR*bS (plus the cost for writing the output), where bR and bS are the numbers of blocks in R and S.
Block Nested Loops Join Try to utilize all nB blocks in memory. Use one memory block for the inner relation, S, one block for the output, and the rest (nB-2) for the outer relation, R: while not eof(R) { read the next nB-2 blocks of R into memory; start scanning S from start one block at the time; while not eof(S) { read the next block of S; perform the join R R.A=S.B S between the memory blocks of R and S and write the result to the output; } }
Block Nested Loops Join (cont.) Cost: bR+bR/(nb-2)*bS But, if either R or S can fit entirely in memory (ie. bRnb-2 or bSnb-2) then the cost is bR+bS. You always use the smaller relation (in number of blocks) as outer and the larger as inner. Why? Because the cost of S R.A=S.B R is bS+bS/(nb-2)*bR. So if bR>bS, then the latter cost is smaller. Rocking the inner relation: Instead of always scanning the inner relation R from the beginning, we can scan it top-down first, then bottom-up, then top-down again, etc. That way, you don’t have to read the first or last block twice. In that case, the cost formula will have bS-1 instead of bS.
Index Nested Loops Join If there is an index I (say a B+-tree) on S over the search key S.B, we can use an index nested loops join: for each tuple rR do { retrieve all tuples sS using the value r.A as the search key for the index I; perform the join between the r and the retrieved tuples from S } Cost: bR+|R|*(#of-levels-in-the-index), where |R| is the number of tuples in R. The number of levels in the B+-tree index is typically smaller than 4.
Sort-Merge Join Applies to equijoins only. Assume R.A is a candidate key of R. Steps: • Sort R on R.A • Sort S on S.B • Merge the two sorted files as follows: r first(R) s first(S) repeat { while s.Br.A { if r.A=s.B then write <r,s> to the output s next(S) } r next(R) } until eof(R) or eof(S)
Sort-Merge Join (cont.) Cost of merging: bR+bS If R and/or S need to be sorted, then the sorting cost must be added too. You don’t need to sort a relation if there is a B+-tree whose search key is equal to the sort key (or, more generally, if the sort key is a prefix of the search key). Note that if R.A is not candidate key, then switch R and S, provided that S.B is a candidate key for S. If neither is true, then a nested loops join must be performed between the equal values of R and S. In the worst case, if all tuples in R have the same value for r.A and all tuples of S have the same value for s.B, equal to r.A, then the cost will be bR*bS. Sorting and merging can be combined into one phase. In practice, since sorting can be done in less than 4 passes only, the sort-merge join is close to linear.
Hash Join Works on equijoins only. R is called the built table and S is called the probe table. We assume that R can fit in memory Steps: • Built phase: read the built table, R, in memory as a hash table with hash key R.A. For example, if H is a memory hash table with n buckets, then tuple r of R goes to the H(h(r.A) mod n) bucket, where h maps r.A to an integer. • Probe phase: scan S, one block at a time: res for each sS for each rH(h(s.B) mod n) if r.A=s.B then insert the concatenation of r and s into res
Partitioned Hash Join If neither R nor S can fit in memory, you partition both R and S into m=min(bR,bS)/(k*nB) partitions, where k is a number larger than 1, eg, 2. Steps: • Partition R: create m partition files for R: R1,…Rm for each rR put r in the partition Rk, where k=h(r.A) mod m • Partition S: create m partition files for S: S1,…Sm for each sS put s in the partition Sk, where k=h(s.B) mod m • for i=1 to m perform in-memory hash join between Ri and Si
Partitioned Hash Join (cont.) If the hash function does not partition uniformly (this is called data skew), one or more Ri/Si partitions may not fit in memory. We can apply the partitioning technique recursively until all partitions can fit in memory. Cost: 3*(bR+bS) since each block is read twice and written once. In most cases, it’s better than sort-merge join, and is highly parallelizable. But sensitive to data skew. Sort-merge is better when one or both inputs are sorted. Also sort-merge join delivers the output sorted.
Aggregation with Group-by If it is aggregation without group-by, then simply scan the input and aggregate using one or more accumulators. For aggregations with a group-by, sort the input on the group-by attributes and scan the result. Example: select dno, count(*), avg(salary) from employee group by dno Algorithm: sort employee by dno into E; efirst(E) count0; sum0; de.dno; while not eof(E) { if e.dno<>d then { output d, count, sum/count; count0; sum0; de.dno } count count+1; sumsum+e.salary enext(E); } output d, count, sum/count;
Other Operators Aggregation with group-by (cont.): Sorting can be combined with scanning/aggregation. You can group-by using partitioned hashing using the group-by attributes for hash/partition key. Other operations: • Selection can be done with scanning the input and testing each tuple against the selection condition. Or you can use an index. • Intersection is a special case of join (the predicate is an equality over all attribute values). • Projection requires duplicate elimination, which can be done with sorting or hashing. You can eliminate duplicates during sorting or hashing. • Union requires duplicate elimination too.
Combining Operators Each relational algebraic operator reads one or two relations as input and returns one relation as output. It can be very expensive if the evaluation algorithms that implement these operators had to materialize the output relations into temporary files on disk. Solution: Stream-based processing (pipelining). Iterators: open, next, close Operators work on stream of tuples now. Operation next returns one tuple only, which is sent to the output stream. It is ‘pull’ based: To create one tuple, the operator calls the next operation over its input streams as many times as necessary to generate the tuple. D B C A
Stream-Based Processing Selection without streams: table selection ( table x, bool (pred)(record) ) { table result = empty for each e in x if pred(e) then insert e into result return result } Stream-based selection: record selection ( stream s, bool (pred)(record) ) { while not eof(s) { r = next(s) if pred(r) thenreturn r } return empty_record } struct stream { record(next_fnc)(…); stream x; stream y; args; } record next ( stream s ) if (s.y=empty) return (s.next_fnc)(s.x,s.args) else return (s.next_fnc)(s.x,s.y,s.args) join x y x.A=y.B selection x y x.C>10
But … Streamed-based nested loops join: record nested-loops ( stream left, stream right, bool (pred)(record,record) ) { while not eof(left) { x = next(left) while not eof(right) { y = next(right) if pred(x,y) thenreturn <x,y> } open(right) } return empty_record } • If the inner stream is the result of a another operator (such as a join), it is better to materialize it into a file. So this works great for left-deep trees. • But doesn’t work well for sorting (a blocking operator).
Query Optimization A query of the form: select A1,…,An from R1,…,Rm where pred can be evaluated by the following algebraic expression: A1,…An(pred(R1… Rm)) Algebraic optimization: Find a more efficient algebraic expression using heuristic rules.
Heuristics • If pred in pred is a conjunction, break pred into a cascade of : p1 and …pn(R) = p1(… pn(R)) • Move as far down the query tree as possible: p(R S) = p(R) S if p refers to R only • Convert cartesian products into joins R.A=S.B(R S) = R R.A=S.B S • Rearrange joins so that there are no cartesian products • Move as far down the query tree as possible (but retain attributes needed in joins/selections).
Example select e.fname, e.lname from project p, works_on w, employee e where p.plocation=‘Stafford’ and e.bdate>’Dec-31-1957’ and p.num=4 and p.number = w.pno and w.essn=e.ssn e.fname, e.lname p.pnumber=w.pno p.pnumber e.fname, e.lname, w.pno p.plocation=‘Stafford and p.num=4 w.essn=e.ssn p project w.essn, w.pno e.ssn, e.fname, e.lname w works_on e.bdate>’Dec-31-1957’ e employee
Plan Selection It has 3 components: • Enumeration of the plan space. • Only the space of left-deep plans is typically considered. • Cartesian products are avoided. • It’s NP-hard problem. • Some exponential algorithms (O(2N) for N joins) are still practical for everyday queries (<10 joins). We will study the system R dynamic programming algorithm. • Many polynomial-time heuristics exist. • Cost estimation • Based on statistics, maintained in system catalog. • Very rough approximations; still black magic. • More accurate estimations exist based on histograms. • Plan selection. • Ideally, want to find the best plan. Practically, want to avoid the worst plans.
Cost Estimation The cost of a plan is the sum of the cost of all the plan operators. • If the intermediate result between plan operators is materialized, we need to consider the cost of reading/writing the result. • To estimate the cost of a plan operator (such as block-nested loops join), we need to estimate the size (in blocks) of the inputs. • Based on predicate selectivity. Assumed independence of predicates. • For each operator, both the cost and the output size needs to be estimated (since it may be needed for the next operator). • The sizes of leaves are retrieved from the catalog (statistics on table/index cardinalities). • We will study system R. • Very inexact, but works well in practice. Used to be widely used. • More sophisticated techniques known now.
Statistics Statistics stored in system catalogs typically contain • Number of tuples (cardinality) and number of blocks for each table and index. • Number of distinct key values for each index. • Index height, low and high key values for each index. Catalogs are updated periodically, but not every time data change (too expensive). This may introduce slight inconsistency between data and statistics, but usually the choice of plans is resilient to slight changes in statistics. Histograms are better approximations: # of tuples M Tu W Th F Sa Su Day of week M